一、个人需求
由于一直用Linux系统,对于词典的支持特别不好,对于我这英语渣渣的人来说,当看英文文档就一直卡壳,之前用惯了有道词典,感觉很不错,虽然有网页版的但是对于全站英文的网页来说并不支持。索性自己实现一个,基于Python编写的小工具实现有道词典,同时还可以将不认识的生词写入生词本中(xml格式),然后定期批量导入有道词典、沪江英语、金山词霸等。需要申请有道api.
二、代码
由于程序过于简单就不再分析了,一些功能还尚在完善中。代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90 | #!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Date : 2014-04-03 21:12:16
# @Function: 有道翻译命令行版
# @Author : BeginMan
import os
import sys
import urllib
import urllib2
reload(sys)
sys.setdefaultencoding("utf-8")
import simplejson as json
import platform
import datetime
API_KEY = '你的'
KEYFORM = '你的'
def GetTranslate(txt):
url = 'http://fanyi.youdao.com/openapi.do'
data = {
'keyfrom': KEYFORM,
'key': API_KEY,
'type': 'data',
'doctype': 'json',
'version': 1.1,
'q': txt
}
data = urllib.urlencode(data)
url = url+'?'+data
req = urllib2.Request(url)
response = urllib2.urlopen(req)
result = json.loads(response.read())
return result
def Sjson(json_data):
query = json_data.get('query','') # 查询的文本
translation = json_data.get('translation','') # 翻译
basic = json_data.get('basic','') # basic 列表
sequence = json_data.get('web',[]) # 短语列表
phonetic,explains_txt,seq_txt,log_word_explains = '','','',''
# 更多释义
if basic:
phonetic = basic.get('phonetic','') # 音标
explains = basic.get('explains',[]) # 更多释义 列表
for obj in explains:
explains_txt += obj+'\n'
log_word_explains += obj+','
# 句子解析
if sequence:
for obj in sequence:
seq_txt += obj['key']+'\n'
values = ''
for i in obj['value']:
values += i+','
seq_txt += values+'\n'
print_format = '*'*40+'\n'
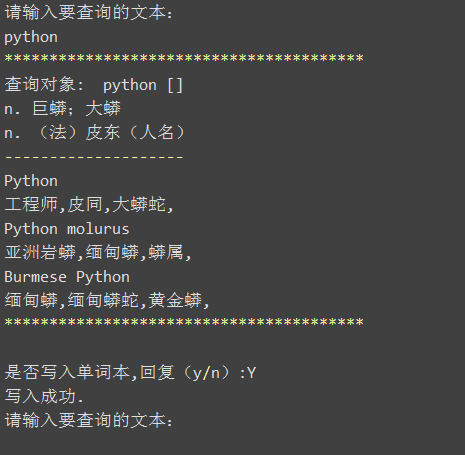
print_format += u'查询对象: %s [%s]\n' %(query,phonetic)
print_format += explains_txt
print_format += '-'*20+'\n'+seq_txt
print_format += '*'*40+'\n'
print print_format
choices = raw_input(
u'是否写入单词本,回复(y/n):')
if choices in ['y','Y']:
filepath = r'/home/beginman/pyword/%s.xml' %datetime.date.today()
if (platform.system()).lower() == 'windows':
filepath = r'E:\pyword\%s.xml' %datetime.date.today()
fp = open(filepath,'a+')
file = fp.readlines()
if not file:
fp.write('<wordbook>\n')
fp.write(u""" <item>\n <word>%s</word>\n <trans><![CDATA[%s]]></trans>\n <phonetic><![CDATA[[%s]]]></phonetic>\n <tags>%s</tags>\n <progress>1</progress>\n </item>\n\n""" %(query,log_word_explains,phonetic,datetime.date.today()))
fp.close()
print u'写入成功.'
def main():
while True:
txt = raw_input(u'请输入要查询的文本:\n')
if txt:
Sjson(GetTranslate(txt))
if __name__ == '__main__':
main()
|
三、效果图