
作者:KingShine,现居北京,程序猿一枚。主要方向为数据分析、自然语言处理,大数据。希望结交到志同道合的朋友,共同进步。
本文主要是作为一个PySpark的入手实例来做,数据来源网络。主要用到两个数据文件:action.txt,document.txt。下表为action.txt,数据格式:userid~docid~behaivor~time~ip,即:用户编码~文档编码~行为~日期~IP地址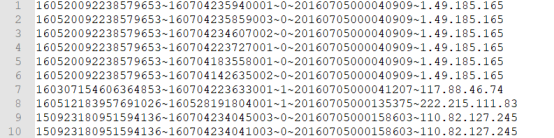
下表为document.txt,数据格式:docid~channelname~source~keyword:score,即:文档编码~类别(大类)~主题(细类)~关键词:权重
用户点击率即为action.txt文件中每个用户behaivor列中1的数量除以0的数量。
2、读取数据,将数据根据‘~’拆分,获取userid和behavior两列



4、将userid,behavior和数量取出作为3列,并转为DataFrame格式
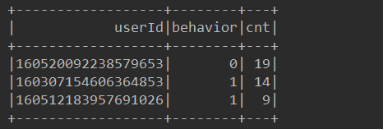
5、根据userId进行分组,将behavior列数据进行旋转作为列标数值为cnt。并将behavior的0和1替换为“browse”和”click”。
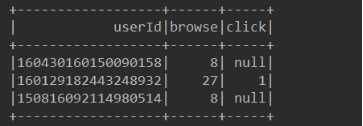

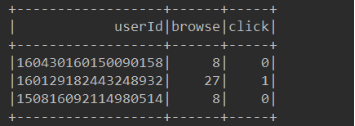

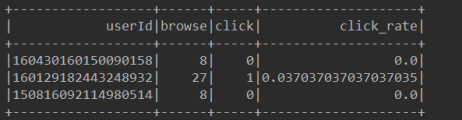
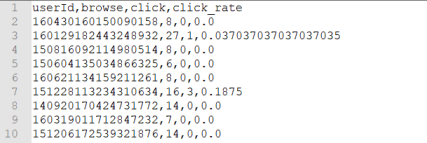
8、将最后处理的数据保存到本地,关闭SparkSession
最后保存到本地的数据为多个文件,每个文件的格式如下:
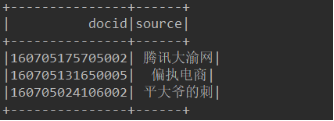
1、读取docunment.txt,获取docid、source两列,即文档编码和主题(细类)两列
2、读取action.txt,只获取具有点击行为的userid和docid数据,即behavior为1的数据。
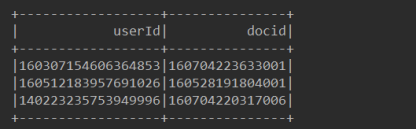


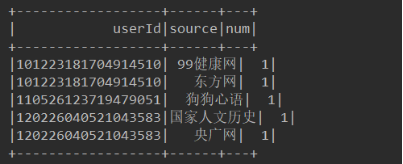
5、将最后处理的数据保存到本地,关闭SparkSession

1、代码开发时,可以每个操作跟一个action,方便查看数据,跑批的时候不需要每个都跟,只需要最后一个action,否则会给机器增加很多工作量。2、中间过程生成的DataFrame必须先建立临时视图,后面才能使用,否则会报错。赞 赏 作 者

Python中文社区作为一个去中心化的全球技术社区,以成为全球20万Python中文开发者的精神部落为愿景,目前覆盖各大主流媒体和协作平台,与阿里、腾讯、百度、微软、亚马逊、开源中国、CSDN等业界知名公司和技术社区建立了广泛的联系,拥有来自十多个国家和地区数万名登记会员,会员来自以工信部、清华大学、北京大学、北京邮电大学、中国人民银行、中科院、中金、华为、BAT、谷歌、微软等为代表的政府机关、科研单位、金融机构以及海内外知名公司,全平台近20万开发者关注。

▼ 点击成为社区注册会员 「在看」一下,一起PY










