一般来说我们会遇到网站反爬虫策略下面几点:
限制IP访问频率,超过频率就断开连接。(这种方法解决办法就是,降低爬虫的速度在每个请求前面加上time.sleep;或者不停的更换代理IP,这样就绕过反爬虫机制啦!)
后台对访问进行统计,如果单个userAgent访问超过阈值,予以封锁。(效果出奇的棒!不过误伤也超级大,一般站点不会使用,不过我们也考虑进去
还有针对于cookies的 (这个解决办法更简单,一般网站不会用)
我们今天就来针对1、2两点来写个下载模块、别害怕真的很简单。
首先,这次我们需要用到Python中的 re模块来提取内容
首先照常我们需要下面这些模块:
requests
re(Python的正则表达式模块)
random(一个随机选择的模块)
都是上一篇文章装过的哦!re 和random是Python自带的模块,不需要安装
首先按照惯例我们导入模块:
import requests
import re
import random
我们的思路是先找一个发布代理IP的网站(百度一下很多的!)从这个网站爬取出代理IP 用来访问网页;当本地IP失效时,开始使用代理IP,代理IP失败六次后取消代理IP。下面我们开整
首先我们写一个基本的请求网页并返回response的函数:

哈哈 简单吧!
这只是基本的,上面说过啦,很多网站都都会拒绝非浏览器的请求的、怎么区分的呢?就是你发起的请求是否包含正常的User-Agent 这玩意儿长啥样儿?就下面这样(如果不一样 请按一下F5)

requests的请求的User-Agent 大概是这样 python-requests/2.3.0 CPython/2.6.6 Windows/7 这个不是正常的User-Agent、所以我们得自己造一个来欺骗服务器(requests又一个headers参数能帮助我们伪装成浏览器哦!不知道的 一定是没有看官方文档!这样很不好诶!o(一︿一+)o),让他以为我们是真的浏览器。
上面讲过有的网站会限制相同的User-Agent的访问频率,那我们就给他随机来一个User-Agent好了!去百度一下User-Agent,我找到了下面这些:
 下面我们来改改上面的代码成这样:
下面我们来改改上面的代码成这样:
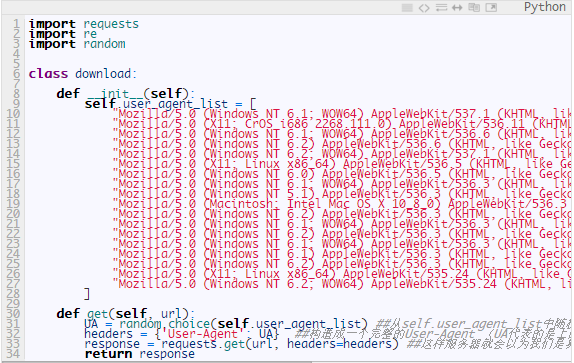 各位可以自己实例化测试一下,headers会不会变哦ε=ε=ε=(~ ̄▽ ̄)~
各位可以自己实例化测试一下,headers会不会变哦ε=ε=ε=(~ ̄▽ ̄)~
好啦下面我们继续还有一个点没有处理:那就是限制IP频率的反爬虫。
首先是需要获取代理IP的网站,我找到了这个站点 http://haoip.cc/tiqu.htm(这儿本来我是准备教大家自己维护一个IP代理池的,不过有点麻烦啊!还好发现这个代理站,还是这么好心的站长。我就可以光明正大的偷懒啦!ヾ(≧O≦)〃嗷~)
我们先把这写IP爬取下来吧!本来想让大家自己写,不过有用到正则表达式的,虽然简单,不过有些怕是不会使。我也写出来啦.
 我们来打印一下看看
我们来打印一下看看
 下面[————–]中的内容就我们添加进iplist这个初始化的list中的内容哦!
下面[————–]中的内容就我们添加进iplist这个初始化的list中的内容哦!
完美!!好啦现在我们把这段代码加到之前写的代码里面去;并判断是否使用了代理:
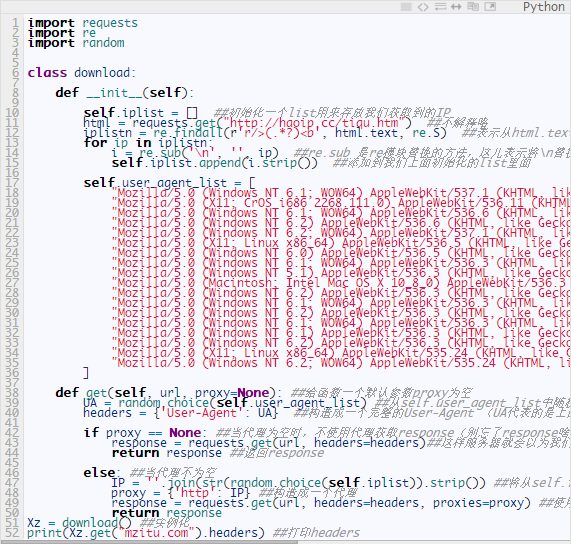 需要测试的,可以自行测试哦。
需要测试的,可以自行测试哦。
下面我开始判断什么时候需要 !需要使用代理,而且还得规定一下多少次切换成代理爬取,多少次取消代理啊!我们改改代码,成下面这样:
 上面代码添加了一个timeout (防止超时)、一个num_retries=6(限制次数,6次过后使用代理)。
上面代码添加了一个timeout (防止超时)、一个num_retries=6(限制次数,6次过后使用代理)。
下面我们让使用代理失败6次后,取消代理,直接上代码:
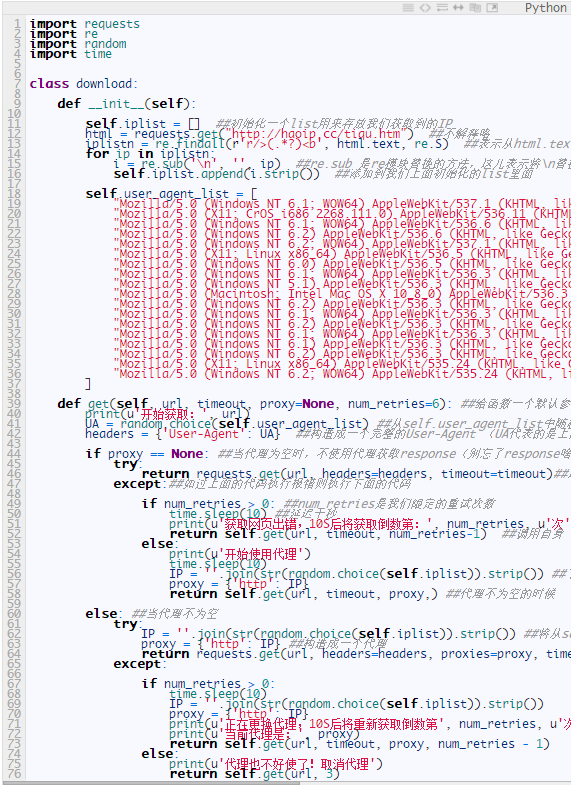 收工一个较为健壮的下载模块搞定(当然一个健壮的模块还应该有其它的内容,比如判断地址是否是robots.txt文件禁止获取的;错误状态判断是否是服务器出错,限制爬虫深度防止掉入爬虫陷进之类的····)
收工一个较为健壮的下载模块搞定(当然一个健壮的模块还应该有其它的内容,比如判断地址是否是robots.txt文件禁止获取的;错误状态判断是否是服务器出错,限制爬虫深度防止掉入爬虫陷进之类的····)
不过我怕太多大家消化不了,而且我们一般遇到的网站基本不会碰到爬虫陷阱(有也不怕啊,反正规模不大,自己也就注意到了。)
下面我们来把这个下载模块使用到我们上一篇博文的爬出红里面去!
用法很简单!ヾ(´▽‘)ノ将这个py文件放在和上一篇博文爬虫相同的文件夹里面;并新建一个init.py的文件。像这样:
 在爬虫里面导入下载模块即可,class继承一下下载模块;然后替换掉上一篇爬虫里面的全部requests.get,为download.get即可!还必须加上timeout参数哦!废话不多说直接上代码:
在爬虫里面导入下载模块即可,class继承一下下载模块;然后替换掉上一篇爬虫里面的全部requests.get,为download.get即可!还必须加上timeout参数哦!废话不多说直接上代码:
 好了!搞完收工!大家可以看一下和上一次我们写的爬虫有哪些变化就知道我们做了什么啦!
好了!搞完收工!大家可以看一下和上一次我们写的爬虫有哪些变化就知道我们做了什么啦!
更新:今天做教程的时候发现我忽略了一个问题,上面的写法,属于子类继承父类,这种写法 子类没法用init;所以我改了一下写法,(其余都没变,不用担心。)直接贴代码了:
首先是下载模块(Download.py):
 这个模块就多了 request = download()
这个模块就多了 request = download()
第二个(def mzitu.py):
改动的地方我都有明确标注哦!仔细看看有什么不同吧。











