0 前言
在数据分析过程中,不同的软件通常对数据格式有一定的要求,例如R语言中希望导入的数据最好是长格式数据而不是宽格式数据,而SPSS软件经常使用宽格式数据。平时数据分析的时候,无法保证导入的数据一定是什么格式,因此需要了解长宽格式数据之间如何相互转换。
1 何为长宽格式数据
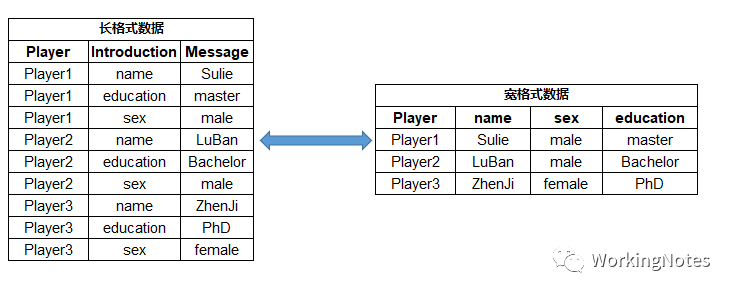
长格式数据:每一行数据记录的是ID(Player)的一个属性,形式为key:value,例如上图左表中,第一行数据记录Player1选手的name信息,name为key,Sulie为value;
宽格式数据:每一行数据为是一条完整的记录,记录着ID(Player)的各种属性;例如上图右表中,第一行就是一条完整的记录,分别记录Player1选手的name叫Sulie,sex为male,education为master。
2 解决方案
特别说明:不要将长宽格数据转换为宽格式数据理解为数据透视表,长转宽只是数据存储形式发生变化,并不对操作对象进行计算,而数据透视表一般对操作对象进行某种操作计算(计数、求和、平均等)。
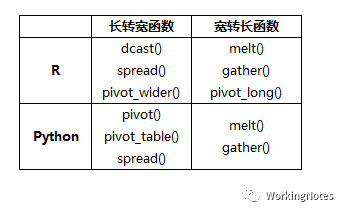
Python中pivot()、pivot_table()和melt位于pandas库中,pivot_table()是数据透视函数,会对操作对象进行处理,故操作对象不能是字符串型,下面举例中会特别说明;spread()和gather()位于dfply库中;
R中的dcast()和melt()位于reshape2包中;spread()、gather()、pivot_wide()和pivot_long()位于tidyr包中,其中pivot_wide()和pivot_long()两个函数要求tidyr从0.8.3版本升级到1.0.0版本,才有这两个函数。R语言中,主要介绍pivot_wide()和pivot_long()这两个函数,另外4个函数可以参考【R语言】长宽格式数据相互转换这篇文章。
3 长转宽函数
Python实现
两种方法:
1 pandas库中的pivot()和privot_table()函数;
2 dfply库中的spread()函数;
方法一:
# long_data = pd.DataFrame({ 'Player':['Player1']*3 + ['Player2']*3 + ['Player3']*3, 'Introduction':['name','education', 'sex']*3, 'Message': ['Sulie', 'master', 'male', 'LuBan', 'Bachelor', 'male', 'ZhenJi', 'PhD', 'female'] })long_data >>= select(X.Player, X.Introduction, X.Message)long_data

#import pandas as pdimport numpy as npfrom dfply import *
#from pandas import *long_data.pivot(index = 'Player', columns = 'Introduction', values = 'Message')
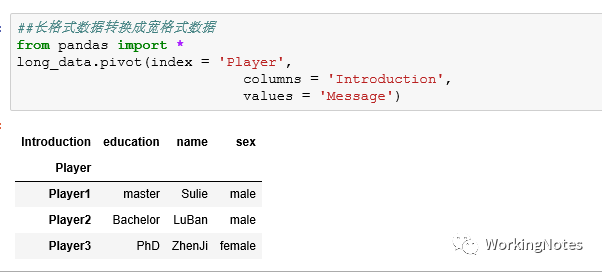
参数columns是长格式数据中的key键对应的列名;参数values是长格式数据中的value对应的列。这里不能使用透视表pivot_table()函数,因为pivot_table()函数对value进行计算(求和、平均等),但这里Message列都是字符型的,无法进行计算;若value为数值型数据,可以使用pivot_table()函数,例如:
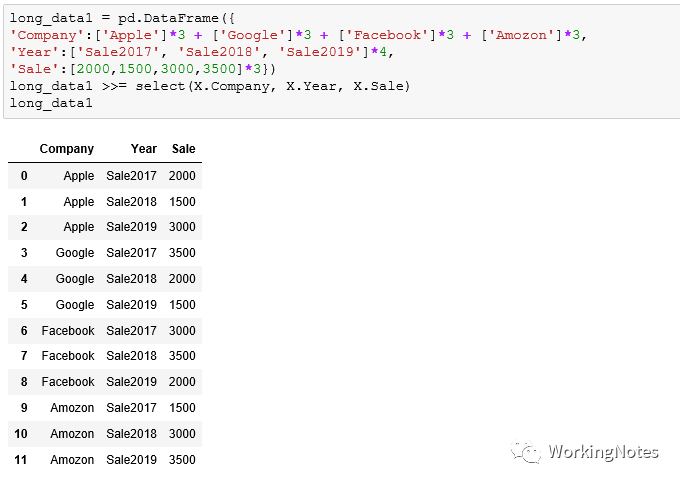
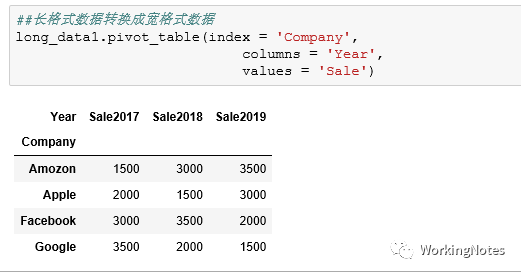
long_data1 = pd.DataFrame({'Company':['Apple']*3 + ['Google']*3 + ['Facebook']*3 + ['Amozon']*3,'Year':['Sale2017', 'Sale2018', 'Sale2019']*4,'Sale':[2000,1500,3000,3500]*3})long_data1 >>= select(X.Company, X.Year, X.Sale)long_data1
long_data1.pivot_table(index = 'Company', columns = 'Year', values = 'Sale')long_data1.pivot(index = 'Company',
columns = 'Year', values = 'Sale')
方法二:
#long_data >> spread(X.Introduction, X.Message)

R实现
##构造数据long_data Player = rep(c("Player1", "Player2", "Player3"), each = 3), Introduction = rep(c("name", "education", "sex"), times = 3), Message = c("Sulie", "master", "male", "LuBan", "Bachelor", "male", "ZhenJi", "PhD", "female"))
long_data = long_data %>% arrange(Player, Introduction)
###使用pivot_wider()library(tidyverse)library(dplyr)library(tidyr)long_data %>% pivot_wider(id_cols = Player, names_from = Introduction, values_from = Message)
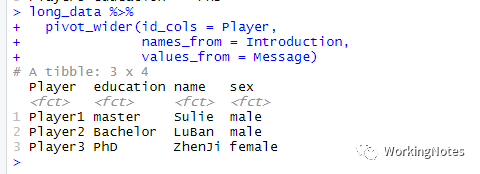
参数names_from对应长格式数据key键对应的列;values_from对应长格式数据value值对应的列。
4 宽转长函数
Python实现
Python中两种方法:
1 pandas库中的melt()函数;
2 dfply库中的gather()函数;
wide_data = pd.DataFrame({ 'Player':['Player1', 'Player2', 'Player3'], 'name':['SuLie', 'LuBan', 'ZhenJI'], 'sex':['male', 'male', 'female'], 'education':['master','Bachelor', 'PhD']
})wide_data >>= select(X.Player, X.name, X.sex, X.education)wide_data

方法一:
wide_data.melt(id_vars='Player', var_name='Introduction', value_name = 'Message')

方法二:
wide_data >> gather('Introduction', 'Message', ['name', 'sex'
, 'education'])

R实现
wide_data
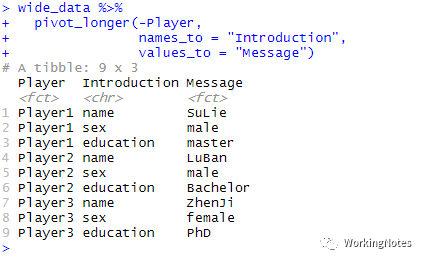
Player = c("Player1", "Player2", "Player3"), name = c("SuLie", "LuBan", "ZhenJi"), sex = c("male", "male", "female"), education = c("master", "Bachelor", "PhD"))wide_datawide_data %>% pivot_longer(-Player, names_to = "Introduction", values_to = "Message")
5 总结
Python中pandas库和dfply库中的函数都可以实现长宽格式数据相互转换;R语言中reshape2包和tidyr包中的函数都可以实现长宽格式数据之间相互转换,建议Python中使用dfply库中函数,R中使用tidyr包中函数,因为key键和value值比较明确。








