作者丨纪厚业
单位丨北京邮电大学博士生
研究方向丨异质图神经网络及其应用
引言
推荐系统尤其是深度推荐系统已经在工业界得到了广泛应用,尤其是在电商场景下(如淘宝和京东的商品推荐)。一个好的工业级推荐系统可以推动业务增长带来大量的经济效益。那么,工业级推荐系统的最佳实践是怎样的呢?Facebook 的推荐团队在本文给出了他们的答案。
本文详细介绍了 Facebook 最新的推荐系统实践包括特征处理、算法建模、代码实现和平台介绍。如此详细清楚的论文,可以说是工业界推荐系统的必读论文之一。作者也开源了代码和最优超参数供大家学习:
https://github.com/facebookresearch/dlrm

模型架构
本文所设计的推荐系统架构如 Fig 1 所示。整个模型主要包含:特征工程(包含 spare 和 dense 特征),用于特征建模 Embedding 和 Embedding Lookup,用于特征转换的 NNs,用于特征交互的 Interactions 以及最后的预测 NNs。
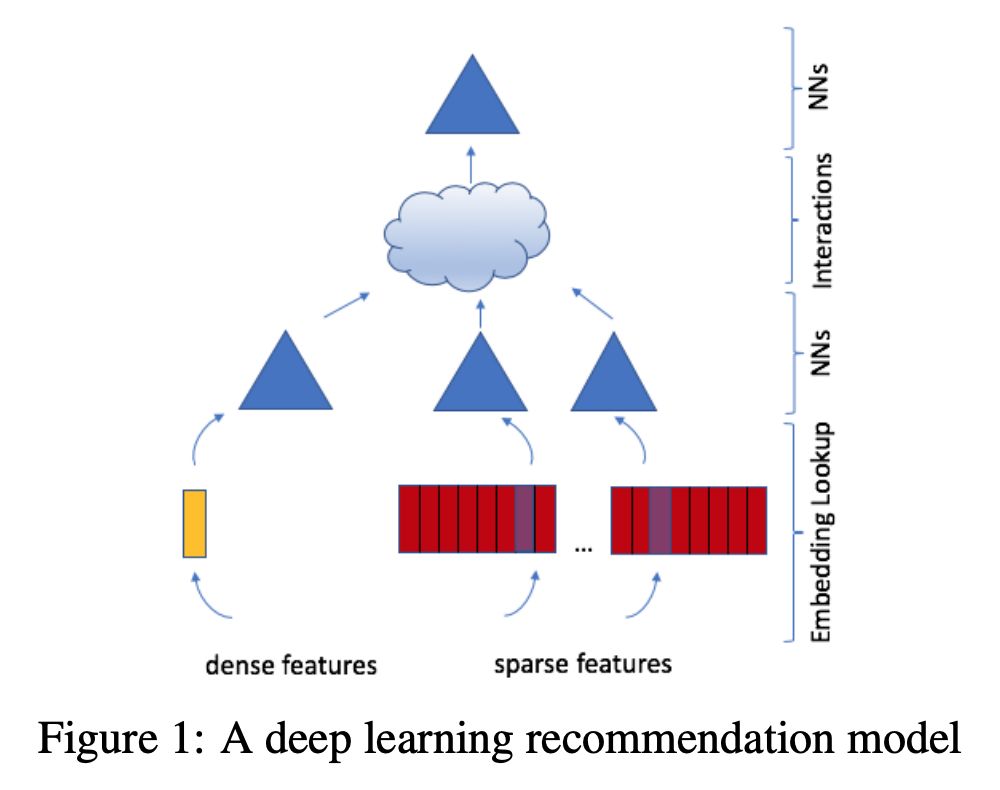
特征表示 Embedding
在实际的推荐场景中,用户和商品通常都有丰富的特征信息。用户的特征通常用性别,年龄,居住地等。如何将这些类别特征转为模型可以处理的向量呢。本文的做法是将这些类别特征编码为 one-hot 的向量,然后通过 embedding lookup 来得到其表示。
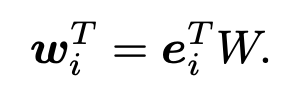
以用户的性别为例,性别男的 one-hot 编码为 [1, 0] 性别女的 one-hot 编码为 [0,1]。然后,我们针对性别初始化一个关于性别的 embedding matrix,该矩阵大小为 2*d,2 代表性别的可能取值,d 代表 embedding 的维度。那么通过 embedding lookup,性别男的 embedding 其实就是 embedding matrix的第一行,性别女的 embedding 就是 embedding matrix 的第二行。通过上述操作,我们就将难以处理的类别特征转化为了神经网络方便处理的向量。
上述过程得到是类别特征的初始 embedding,我们可以通过 MLP 对其进行非线性转换。初始的特征 embedding 会在模型优化过程中学习到具有区分度的特征表示。
特征交互 Interaction
在得到特征的表示后,我们通过内积等简单操作实现模型的预测:
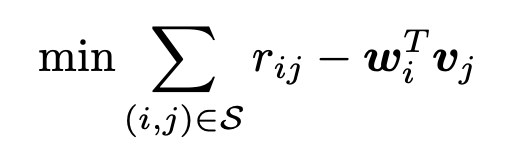
但是,如果我们能够抓住的描述特征关联性,那么模型的预测能力可能会进一步提升。例如,经典的 FM:
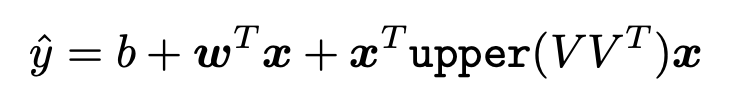
特征交叉的好处到底在哪呢?这里给一个形象的例子:经度和纬度分开看并不能精准定位某个地区,但是当经纬度结合起来就可以精准定位地区,该地区的每一部分拥有的类似的特性。
模型预测 NNs
有了特征的表示及其交互之后,我们可以将其送入到 MLP 中,并利用 Sigmoid 函数预测最终的点击概率。
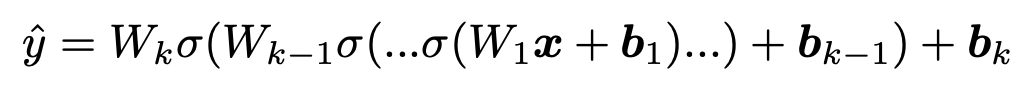
可以看出,本文所提出的 DLRM 模型其实并没有很复杂,但是却将工业界的一些实践方法给出了清晰的介绍。
模型实现
DLRM 实现所需要的相关接口在 PyTorch 和 Caffe2 中都有实现,见 Table 1。

模型并行
在工业界的大规模数据下,模型并行是必不可少的一个步骤。DLRM 模型的主要参数来自于特征的 embedding,后面特征交互和模型预测部分的参数其实很少。假设我们有一亿个用户,如果对其 ID 进行 embedding,那么 embedding matrix 就会有一亿行,这是一个非常大的参数矩阵。
对于特征 embedding 部分,这里采用的是模型并行,将一个大的embedding 矩阵放到多个设备上,然后更新相应的特征 embedding。
对于特征交互和模型预测部分,这里的参数量相对较少而且用户/商品的数量无关,本文采用的是数据并行的方式。在多个设备上计算梯度,然后将梯度合并来更新模型。
实验
本文在随机数据,合成数据和公开数据上进行了实验。对比算法主要是Deep cross network。整个实验运行在 Facebook 的 Big Basin platform 上。

具体实验结果如下:
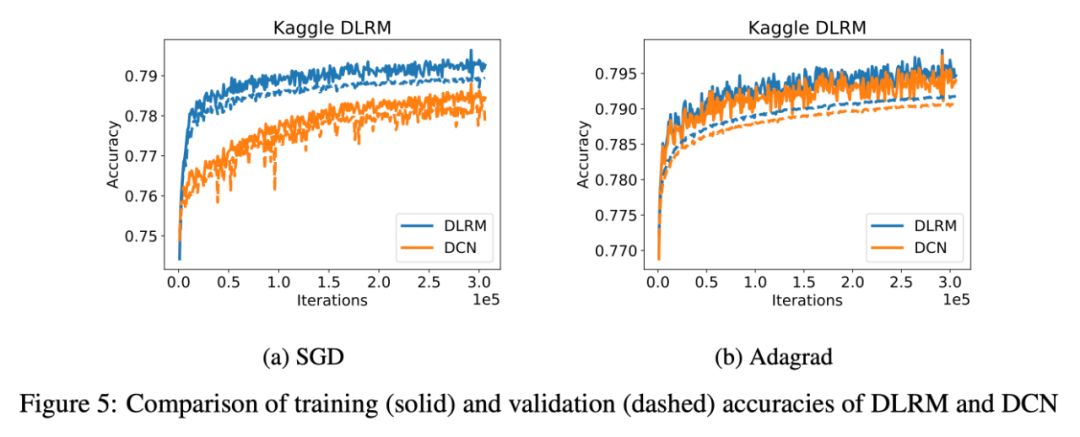
可以看出,本文所提出的 DLRM 算法明显超越谷歌的 DCN。
总结
本文提出了一种工业级推荐系统 DLRM 并实验验证了其优越性。同时,作者也给出了工业界推荐系统的最佳实践,相关代码和超参数设置也进行了开源。可以说,本文是在工业界做推荐系统的必读论文之一。










