学爬虫有什么用
网络爬虫是一个非常注重实践性而且实用性很强的编程技能,它不是程序员的专属技能,任何具有一定编程基础的人都可以学习爬虫,写爬虫分析股票走势,上链家爬房源分析房价趋势,爬知乎、爬豆瓣、爬新浪微博、爬影评,等等
马云说:数据是新一轮技术革命最重要的生产资料。
人工智能时代,对数据的依赖越来越重要,数据主要的来源就是通过爬虫获取,通过爬取获取数据可以进行市场调研和数据分析,作为机器学习和数据挖掘的原始数据。
爬虫技术有一条清晰的进阶成长路线,从爬虫到数据分析再到数据挖掘,最后可进阶为人工智能机器学习等方向。
而我们今天要讨论的微信公众号爬虫则可以为新媒体内容提供运营策略。
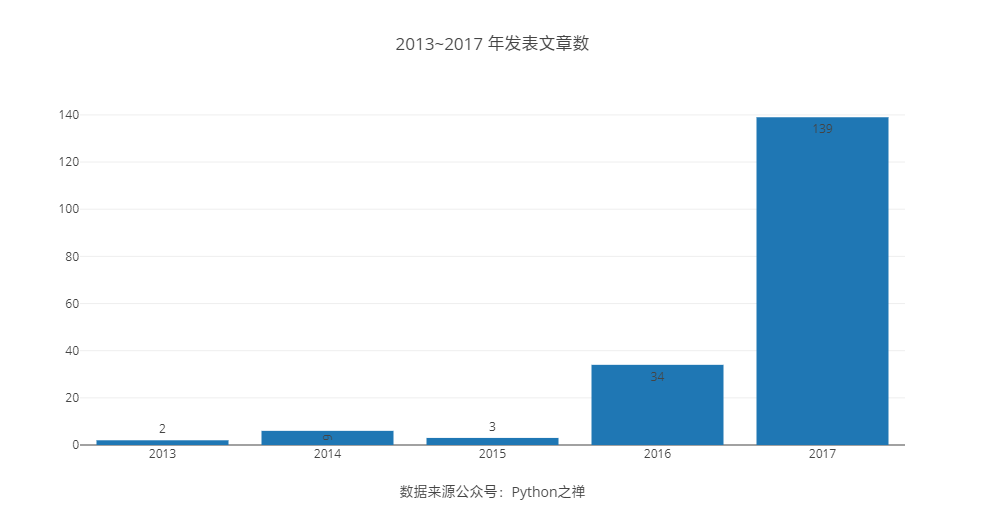
通过爬虫分析,发现前4年我在公众号基本没写什么文章,直到 2016 才开始有点内容,写得最多的是 2017年,一共写了 139 篇文章。
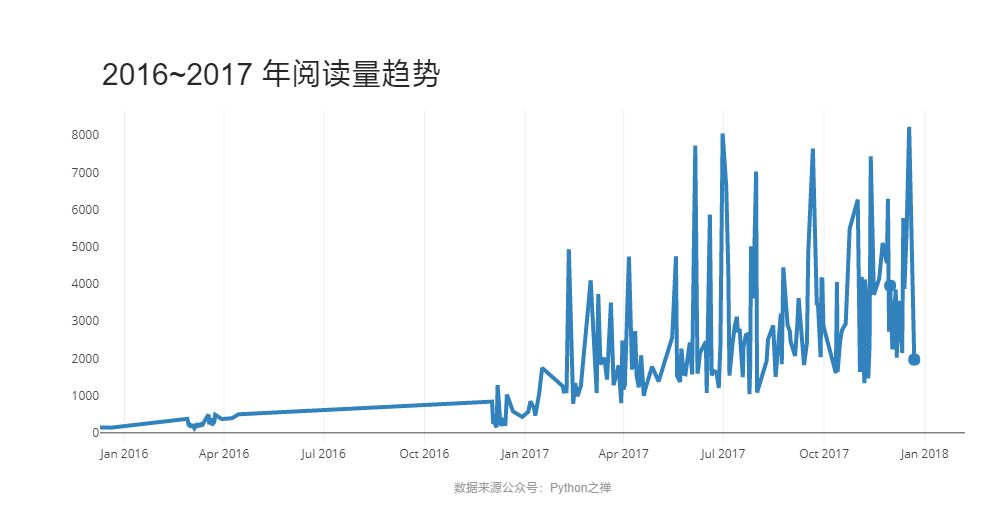
进而看到近两年的阅读量趋势在逐步上升,从2017年初开始,最低阅读量大概只有 800 噌噌地增长到了7000~8000,遗憾的是至今没一篇文章的阅读数超过1万,10万+更是望而止步。
通过爬虫统计分析刷选出阅读量最高的5篇文章是:
微软考虑将 Python 作为 Excel 官方脚本语言 8229
Python是怎么火起来的 8045
如何快速入门Python 7726
Python爬虫知识点梳理 7641
推荐几个公众号 7438
发现自己的辛苦写的干货技术文章没一篇进前5名(^_^^_^),这是娱乐至上的时代,真正在学习的人只是少数,所以,你应该知道为什么半年还入不了门的原因
此外,从数据中还可以挖掘出更多有价值的信息,比如哪个时间段发文阅读量会高,什么样的标题会影响阅读数等等。
如何爬虫微信公众号文章?
微信是封闭的平台,公众号没有对外的统一 Web 平台开放给大众,我们只能另辟蹊径,从微信客户端入手,要想从微信中获取这些数据,就需要通过抓包来分析数据请求,使用 Fiddler、Charles 等代理工具来抓包分析请求的构造原理,再用 Requests 等网络请求模块模拟微信向服务器发起请求获得响应数据,数据经过过滤、清洗就可以用 Pandas 来进行数据分析,进而做数据可视化展示。
以上是用Python爬微信公众号文章的一个基本的思路,其中一定有很多实现细节,只有你真正去实践尝试之后才知道里面有哪些坑,采坑填坑是一个程序员的必经之路。
我会把整个爬虫的思路和实践过程将整理成一本小册,目前已经预发布在掘金平台上。
小册共分为10个章节,只为解决一个问题,就是通过网络获取微信公众号做数据分析,个人认为还算是个比较有趣的实战项目,你将从这本小册中学习到如下知识:
爬虫基本原理
爬虫工具 Requests 的基本使用
数据抓包分析工具 Fiddler 的使用
使用 MongoDB 数据库存储数据
使用 Pandas 进行数据分析
数据可视化展示
目前已经有超过220人购买了该小册,小册的价格是 19.9,不到一个快餐的钱让你接触到最有趣的爬虫实战项目。
福利
给大家准备了20枚5折优惠码,长按下图二维码购买时输入优惠码「lzjun」即可享用5折优惠,先到先得。

点击「阅读原文」购买











