
出品 | AI科技大本营(ID:rgznai100)
【导读】人工智能时代,机器学习已经渗透进每个领域,改变了这些领域的业务模式、技术架构以及方法论。随着深度学习技术近年来快速发展,高效、易用的机器学习平台对于互联网公司愈发重要,一个高效的机器学习平台可以为公司提供更好的人工智能算法研发方面的支持,减少内部重复性、提升资源利用率、提高整体研发效率。
在2019 AI开发者大会上,滴滴出行资深软件工程师唐博在机器学习技术分论坛上分享了kubernetes调度系统在滴滴在机器学习平台中的落地与二次开发。
本次演讲从滴滴机器学习平台的特点开始探讨,分享了滴滴机器学习场景下的 k8s 落地实践与二次开发的技术实践与经验,包括平台稳定性、易用性、利用率、平台 k8s 版本升级与二次开发等内容。此外,唐博还介绍了滴滴机器学习平台是如何从 YARN 迁移到 k8s,以及 YARN 的二次开发与 k8s 的对比等。最后,唐博还分享了滴滴机器学习平台正在研发中的功能以及对未来的展望。
2019 AI开发者大会是由中国IT社区 CSDN 主办的 AI 技术与产业年度盛会,2019 年 9 月 6-7 日,近百位中美顶尖 AI 专家、知名企业代表以及千余名 AI 开发者齐聚北京,进行技术解读和产业论证。
以下为唐博演讲实录,AI科技大本营(ID:rgznai100)整理:
我叫唐博,来自滴滴出行机器学习平台,负责调度系统,今天分享的题目《是滴滴机器学习平台kubernetes落地与实践》,大概分四个部分:
一、滴滴机器学习平台简介
二、平台调度系统的演进
三、机器学习场景下的k8s落地实践与二次开发
四、平台正在开发的功能及未来展望
机器学习平台介绍
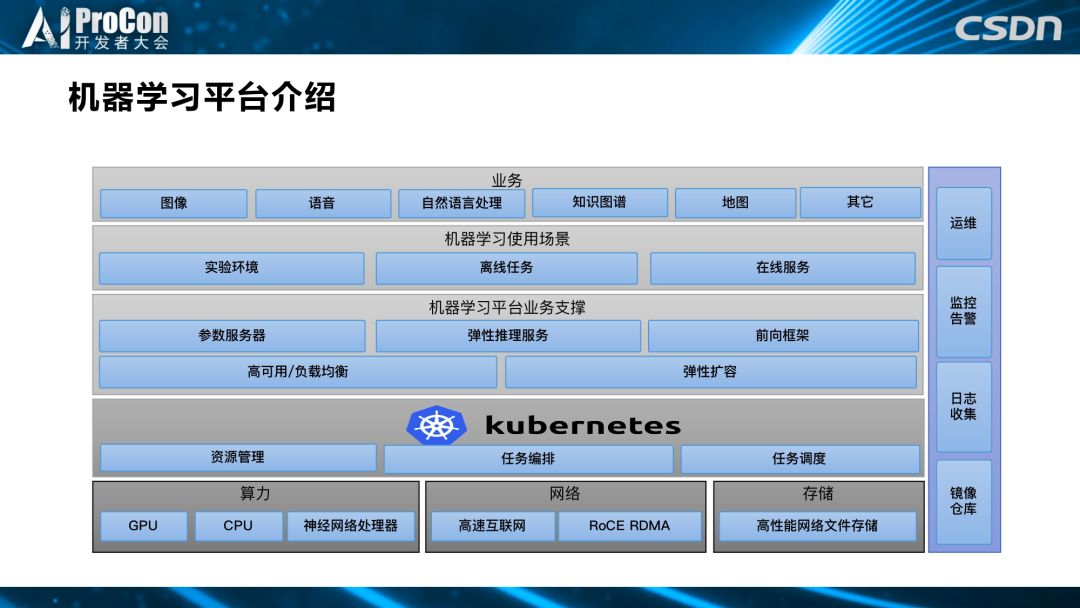
上图最下方是滴滴学习平台整体提供的算力、网络和存储三个方面,其中算力包括 GPU、CPU,也有第三方合作厂商所提供的专用神经网络处理器;网络方面我们内部有一个高速网络;存储方面我们提供了分布式高性能网络存储。基于算力、网络和存储这三个硬件层面的基础设施,我们在上面用 kubernetes 调度系统来进行资源管理。
我们选择 kubernetes 的原因很多,首先是 kubernetes 的扩展性较好,它可以适配各种不同的网络和存储,且在其他方面,如调度、自定义资源、容器运行时等方面都有很好的扩展能力。其次,因为 kubernetes 本身给社区的红利非常好,基于它的设计理念和提供的服务,可以更好地适用于机器学习不同的训练和预测场景。
基于调度层,我们平台提供了各种对机器学习的支撑,比如高可用/负载均衡;对于不同的训练,滴滴自研了环状参数服务器,实现是环状算法。为了提高推理服务的性能,我们自己研发了弹性推理服务和前向框架。
当用户在实验环境里进行代码开发,代码调试到一定程度时,可以把比较成熟的代码放到我们的离线任务里进行批量调参,或者进行自动调参,生成一个满足他们业务需求的模型,并把生成的模型通过我们的前向框架和弹性推理服务,以在线的方式进行推理。
基于这些服务,我们提供不同的深度学习和机器学习业务,包括图像、语音、自然语言处理、知识图谱、地图和 AR、VR 等业务。
侧面这四个是其它部门提供的对于平台建设的支持类业务,比如智能运维、监控告警服务、日志收集和镜像仓库等,这些合起来构成我们的机器学习平台架构。
平台调度系统演进
下面我们来看第二部分,滴滴机器学习平台调度系统的演进。

最开始我们选择了 YARN,并对社区的 Application Master进行了改造,以适合自己的机器学习场景。我们修改了 DockerContainerExecutor以更好地支持 docker 调度,并去除了其中的docker rm命令,从调度层面 100% 保证数据的可靠性。此外,修改了调度器,以支持 GPU 调度,并扩展了 YARN API,让管控系统和调度系统更好地结合,管控系统可以获取更多调度方面的信息。然而,随着业务的逐渐发展,以及业务线和业务形态的多样化,我们发现 YARN无法满足我们的需求,于是,我们从 2017 年开始向 kubernetes 迁移。
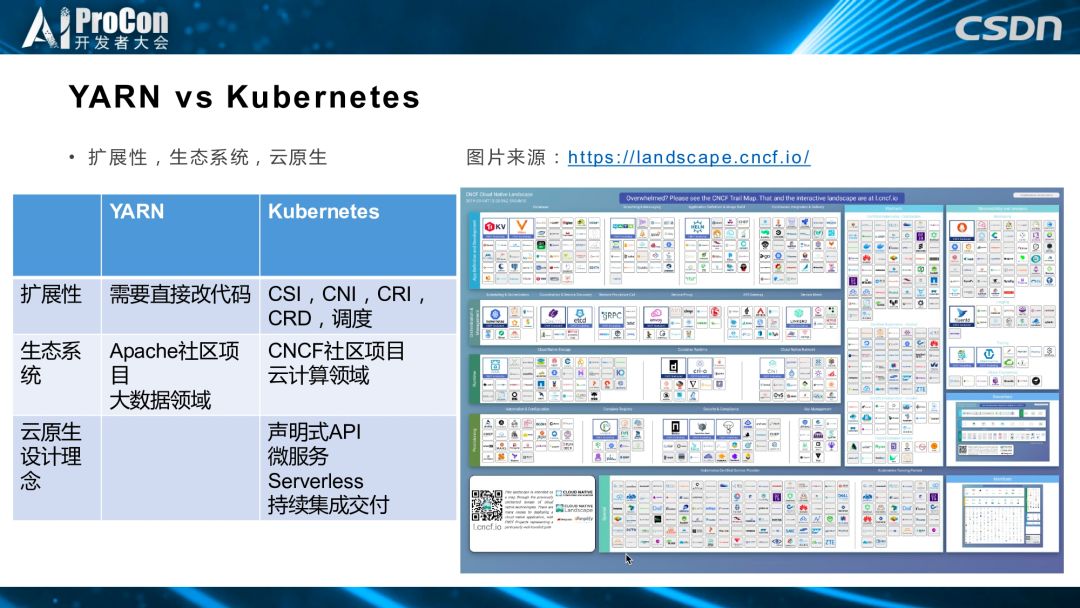
对于我们来说,kubernetes 相比于 YARN,在扩展性、CSI、CNI、CRI、CRD、调度等许多其他可以扩展的接口上有很大的提升。从生态系统上来讲,kubernetes 依托 CNCF 社区,专注于云计算领域,更加契合我们的场景。而 YARN 依托 Apache 社区,主要是大数据领域。云原生设计理念方面,kubernetes 以声明式 API为根本,向上在微服务、serverless、持续集成交付等方面可以做更好的集成,这也是我们从YARN 向 kubernetes 迁移的重要原因。
右图是 CNCF 项目全景图,包括存储、网络、容器进行时、调度、监控等诸多方面,云计算领域应该有的开源项目都包含在其中,包括 Spark 这一子项目。大势所趋,我们决定从 YARN 向kubernetes 迁移。
机器学习场景下的k8s落地实践与二次开发
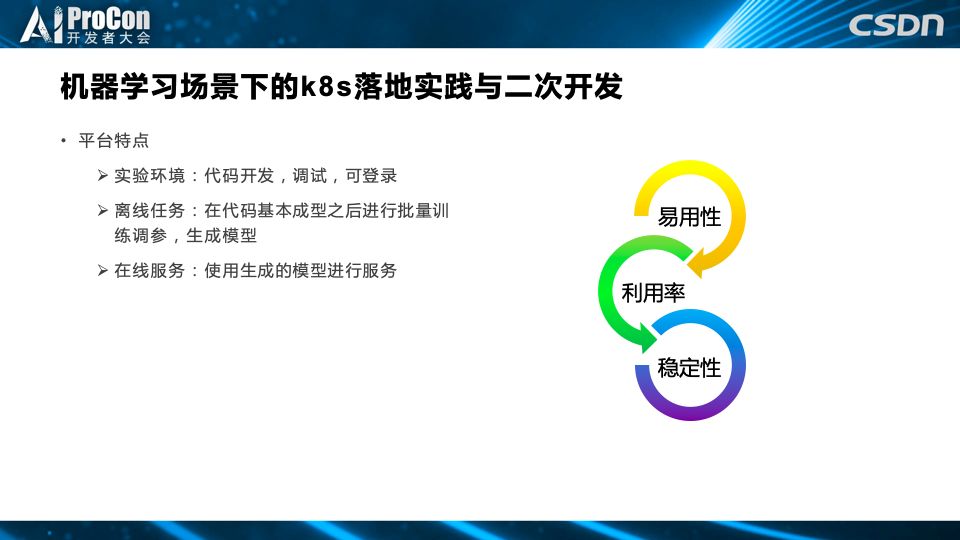
第三点,是关于滴滴机器学习场景下的 k8s 落地实践与二次开发。
滴滴机器学习平台的主要特点是给用户提供三种环境,实验环境、离线任务、在线服务。实验环境主要是用户可以登陆里面,进行代码开发、调试、修改版本等。离线服务是在代码基本成型之后进行批量训练调参,并生成模型。在线服务是使用生成的模型进行预测。
下面将就平台要考虑易用性、利用率、稳定性这三个方面进行 k8s 落地实践与二次开发的相关介绍。
易用性
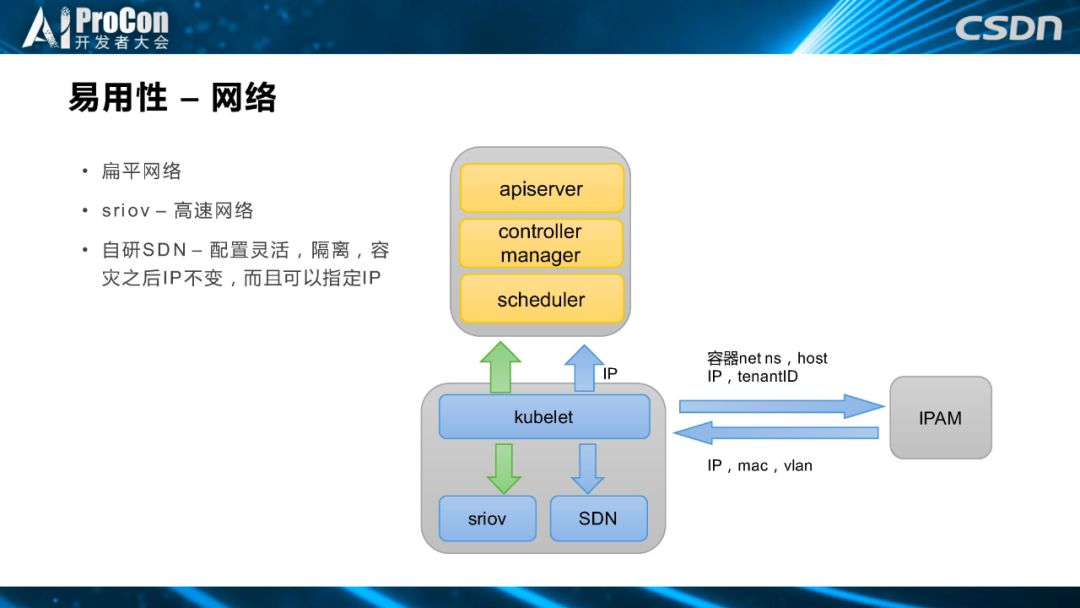
首先是易用性,平台给用户提供了扁平网络,最开始是使用的是sriov 网络,给用户环境分配一个 IP,用户通过管控系统页面登陆实验环境。但是,后来随着公司整体网络架构演进,一方面需要更加灵活的网络配置,另一方面需要更强的隔离性,平台改为使用公司内部的SDN,使得配置更灵活,隔离更强,容灾之后 IP 不变,且可以指定 IP。这一方面是为了给用户更好的用户体验,另一方面是如果将内部调度系统和其他系统,如数据库、分布式缓存系统等进行打通,我们需要有一个白名单功能,而 IP 不变会方便我们进行白名单打通。
这是网络方面调度易用性的相关介绍。接下来是存储方面。
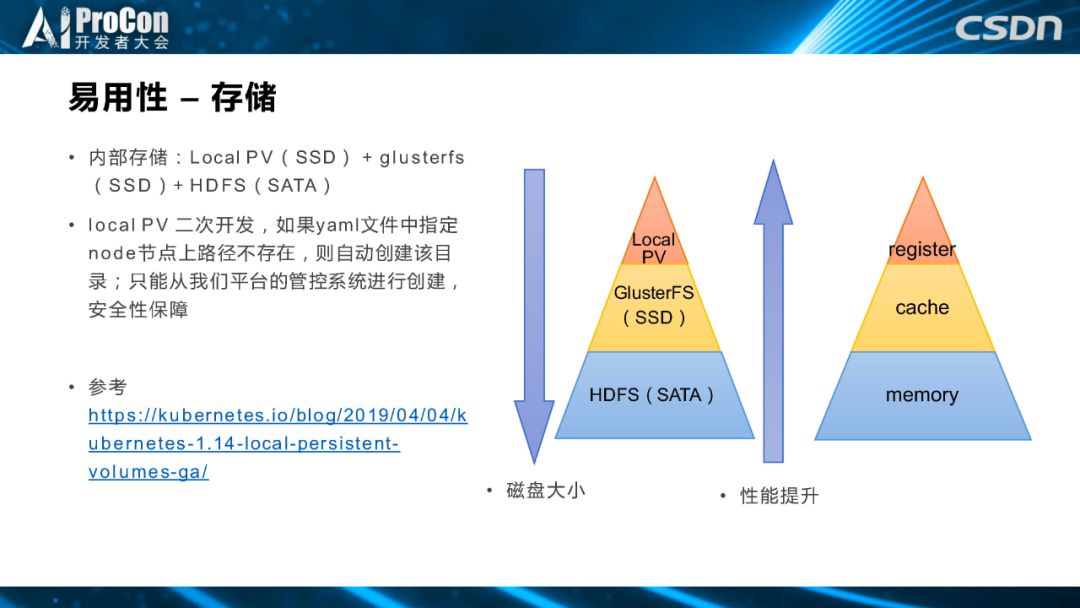
最主要的是中间黄色部分,我们给用户提供了一个分布式的基于 SSD 盘的 GlusterFS 分布式存储系统,用户可以用他们的项目和个人 IP 访问存储空间。但是因为 GlusterFS 空间不大,我们还提供了 HDFS,用户可以把一些较冷的数据放到 HDFS 里,可以多存储一些。除此之外,用户在使用过程中,如果想编译一些小文件较多的框架,网络存储的性能并不能满足他们的需求,所以,基于用户需求和硬件环境,我们提供第三种存储方式,在本机节点上隔出来一块盘,基于local PV提供本机缓存。
local PV本身有两个特点,一是适用高吞吐场景,二是只存在于一个node 节点上,不保证数据的可靠性。关于 local PV 比较典型的使用样例是 Uber 提出来的,Uber的M3DB 把数据进行分片,每一个分片复制三份,每一份是一个 local PV,相当于把数据可靠性功能做到分布式数据系统这一层,所以缓解了 local PV 本身数据不可靠的缺陷。
但是对于我们来说,提供 local PV 功能是为了让用户可以更好地编译而提供缓存,并不需要保证可靠性,只是提供为了高速存储。
我们对 local PV 的代码进行了修改,如果在K8S的yaml文件里面写了一个 node 节点上不存在的目录,它会自动创建该目录,因为我们的调度系统只能从管控系统来进行 PV 创建,所以安全性可以得到保障。
总的来说,如右图中所示,我们提供了三种不同存储,从上到下磁盘空间越来越大,从下到上性能逐渐提升。

接下来是易用性方面的辅助性功能。我们修改了调度的代码, 对docker根目录大小进行了限制。最开始docker存储区驱动是devicemapper,后来随着版本升级变成了overlay2,物理机我们是 xfs 系统,我们用xfs quota功能限制 docker 根目录大小,保证物理机磁盘足够用,以及 harbor 磁盘不被占满。
第二个辅助性功能是增加正在使用的 GPU,APIserver 返回 GPU,kubelet 获取 container 正在使用的 GPU,返回给 apiserver。
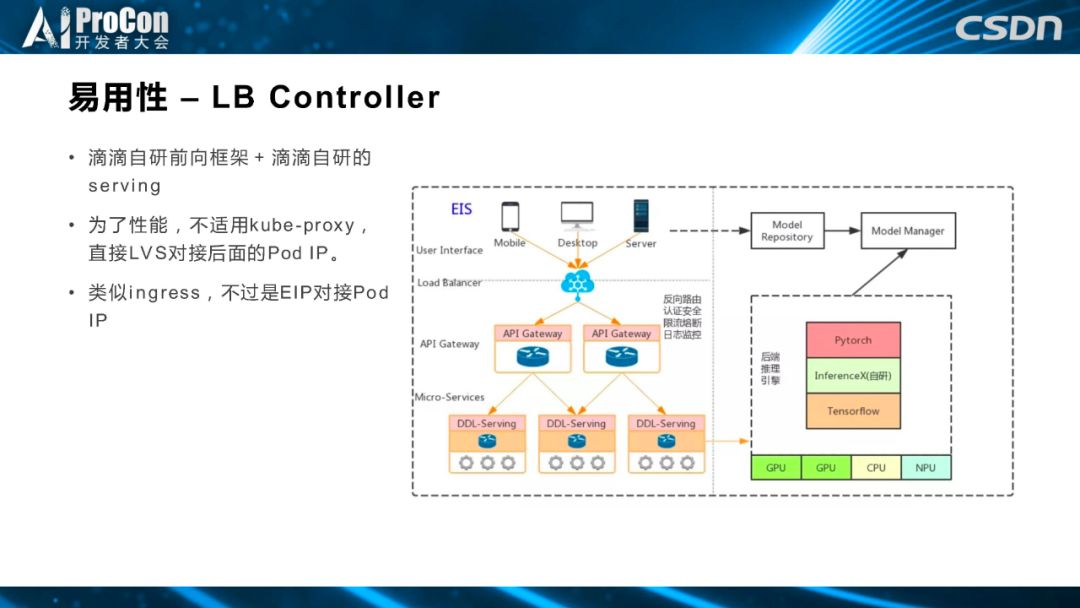
这是滴滴自研前向框架加上滴滴自研的 serving框架,是为了提高inference的性能。kube-proxy在这个场景下会增加一层额外的iptables或者ipvs,我们直接使用了 LVS 对接后面的 Pod IP,类似 ingress,不过是 EIP 对接 Pod IP。我们的目的是为了可以给用户提供更好的前向预测性能。
利用率
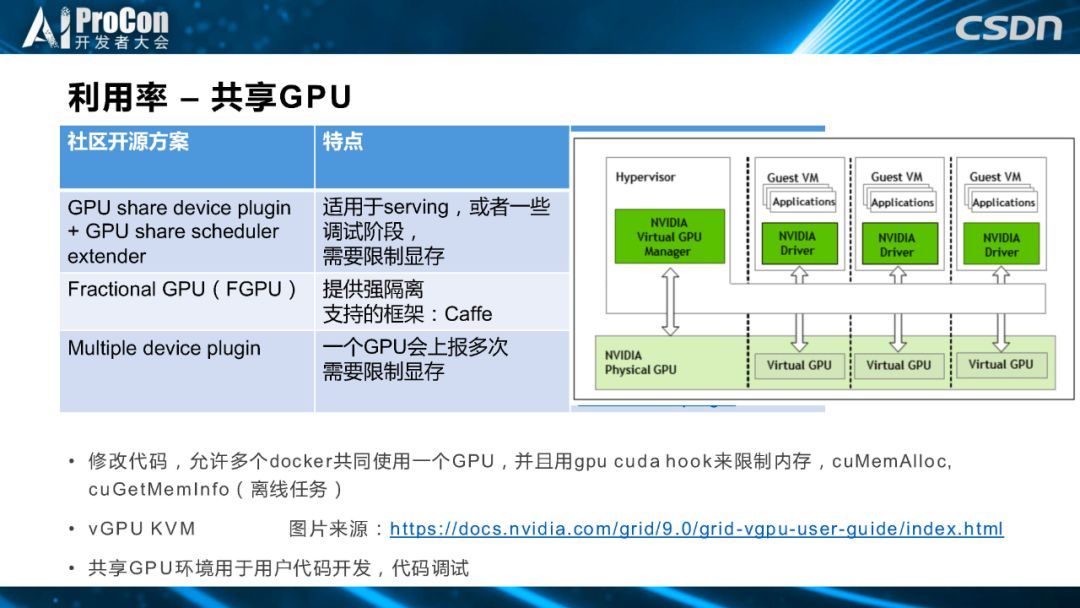
利用率方面,首先介绍共享 GPU。目前我们了解到,社区和友商也提出了一些共享 GPU 的方案,其中可能比较著名的是 GPU share device plugin,加上 GPU 共享的 scheduler extender解决方案,这种解决方案的特点是,它更适合于 serving 前向推理步骤或者代码调试,同时需要限制显存。第二个开源方案是 Fractional GPU,提供强隔离,目前还处于研发阶段,只支持 Caffe 一种框架,如果要适配更加普适性的框架,还需要自己对接开发。第三个是社区同学提供的 Multiple device plugin 方案,一个 GPU 会上报多次,也是需要限制显存。
我们的机器学习平台提供的方法与以上友商和社区的方法有很多相似之处,比如共享 GPU 的方案,我们修改了代码,允许多个 docker 共同使用一个 GPU,并且hook 了cuMemAlloc 等一系列函数进行显存限制。后来,随着业务的演进,我们的实验环境让用户可以进行任何实验,这时有些用户会偶尔做一些破坏性的工作,docker 这种软隔离对他们的限制作用有限,所以我们就采用了英伟达最新提出的 vGPU KVM 供用户使用。
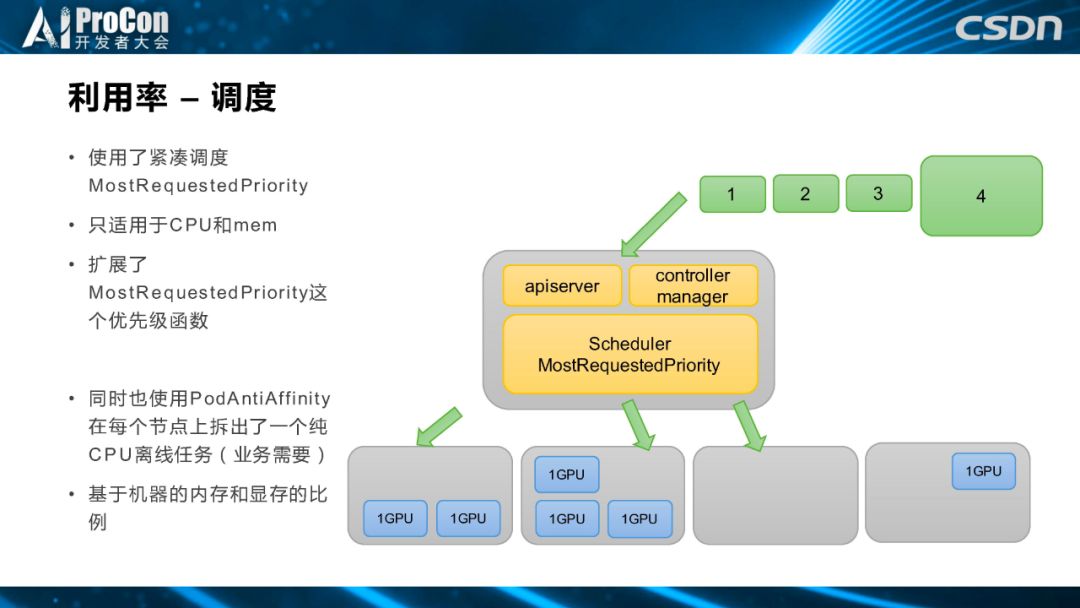
接下来是调度方面,我们根据用户的使用习惯提供了不同套餐的离线任务和实验环境,比如只有一个 GPU 的一卡离线任务和有四个 GPU 的四卡离线任务,在这种套餐化的场景下,会产生一个问题,即资源的碎片化,所以我们用了调度策略,通过配置优先级函数,实现紧凑调度。如右图所示,下面四个是节点,分别运行了两个1卡 GPU,还有三个。第二个和第三个1卡离线任务也是同样调度到第一个节点上,第一个节点 GPU 目前使用率是集群中使用的第二个,这时通过紧凑调度,我们会把第三个节点的离线任务分配给四卡,充分调度空闲机器。
除此之外,根据用户的使用情况,滴滴机器学习平台里除了有 GPU 的任务,也有不使用 GPU 的纯 CPU 离线任务,结合物理机内存和显存的比例情况,除了提供 GPU 离线任务之外,我们把每台物理机隔出一块资源提供给 CPU 离线任务,把 CPU 任务尽量打散,避免影响重要的GPU 任务。另外一点是紧凑调度函数,社区自带的MostRequestedPriority函数只适用于 CPU 和内存,不支持其他的扩展资源,比如 GPU,所以我们对紧凑调度优先级函数进行修改,让它可以支持扩展资源。
为了提升用户体验和进一步提高利用率,我们对k8s 在调度上进行了改进。
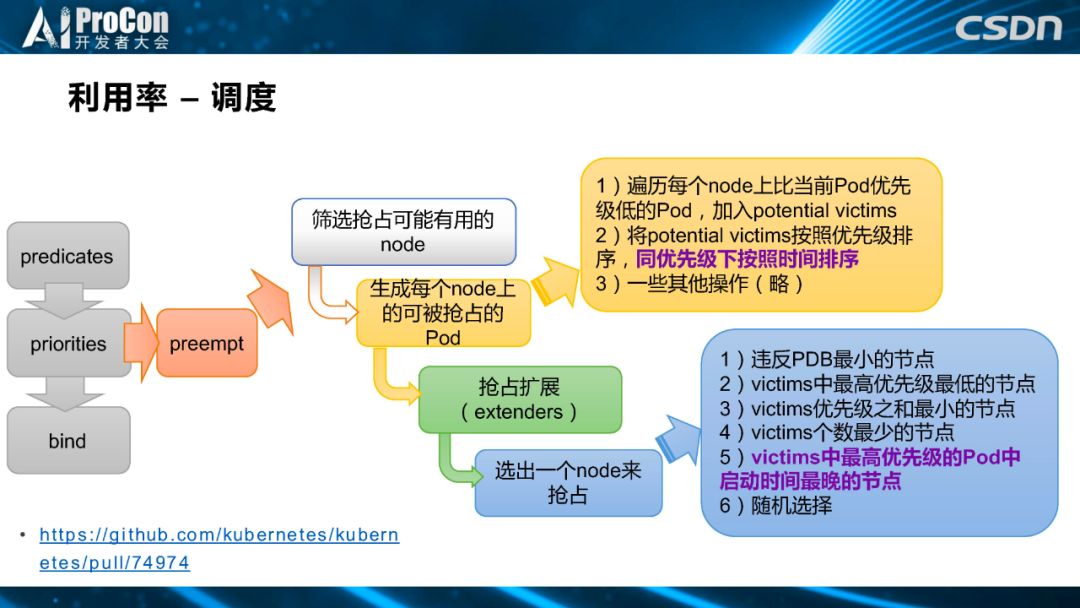
当资源占有率非常高时,如果用户还没有高优先级的任务,就只能让一些紧急任务抢占资源。但是在抢占的同时,我们也希望高优先级的任务到来时,对集群现有任务所造成的伤害和影响最小,所以,我们为抢占的过程加入了一个按照离线任务和 Pod 启动时间先后顺序来进行排序的功能。我们在第二步生成每个 node 上可以被抢占的 Pod进行了改进,加入了启动时间。在第四步,社区的算法是遍历每个 node 上比当前 Pod 优先级低的 Pod,加入 potential victims。将 potential victims 按照优先级排序,同优先级下按照时间排序。如果第一条不能选出最合适的 node 就进行下一条,依次进行。
首先选择违反 PDB 最小的节点。如果第一条就选不出来,第二条从所有可以被抢占的最高优先级Pod中选出优先级最低那个Pod所在的节点,接着是优先级之和最小的节点,个数最少的节点,最高优先级的 Pod 中启动时间最晚的节点。我们发现友商也有这个需求,后来我们和友商一起把这个方案贡献给社区。
稳定性

下面我们来看看稳定性方面。因为稳定性对于任何一个平台级的产品和应用来说都是必不可少的,针对稳定性我们也做了或大或小的参数调整和二次开发,我将分别从运行稳定性、数据稳定性和升级稳定性三个方面来讲解。
运行稳定性,我们调大 pod 驱逐时间和节点监控时间,一方面是为了更好地应对内部网络抖动,超时调大之后可以扛住更大的抖动;另一方面也是为了便于运维操作,如果一个机器挂掉,运维组的同学有足够的时间来恢复脚本,把集群恢复到之前的状态,并把这些 pod 的 IP 也配置成之前的状态,让用户感觉除了重启之外没有其他变化。
数据稳定性,我们去除了 docker rm 命令,防止异常情况下数据丢失,在调度层面确保数据不丢。
升级稳定性,去除了 container hash 检查,去除了 kubelet 创建环境变量时对 pod.Spec.Enable service Links 的检查,使Pod在升级时不会重启。社区相关PR从1.16起升级才管用。
同时我们关闭了TaintBasedEviction,使pod 在升级时不会被驱逐。
平台正在开发的功能及未来展望

最后是关于平台正在开发的功能以及机器学习相关的未来展望。
我们正在进行中的功能开发主要有调度器、再调度器,以及我们自己的 device plugin。
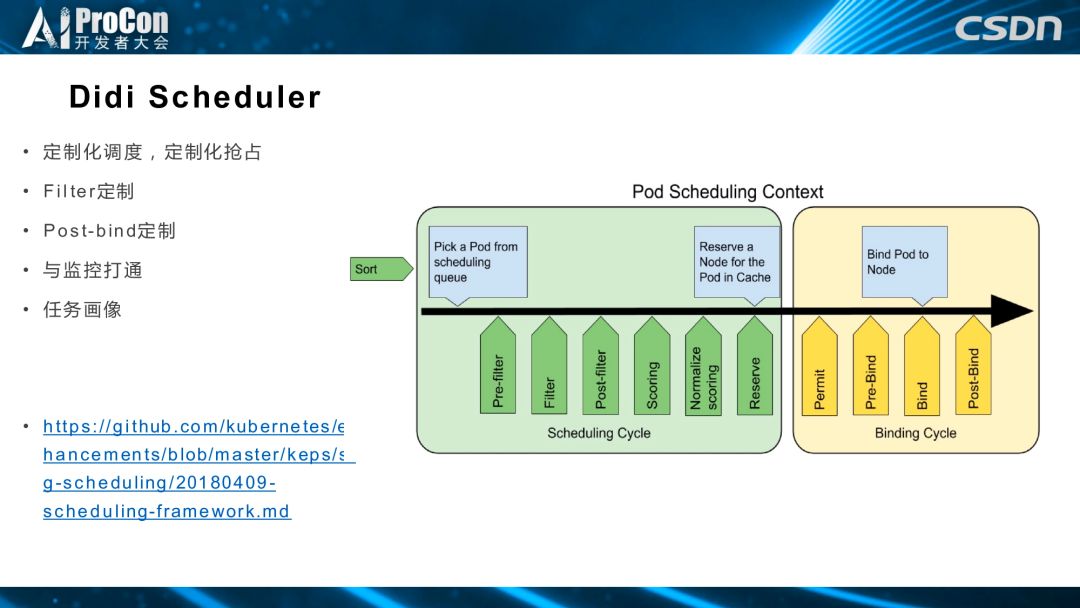
首先是调度器,基于社区的新的调度框架,调度分为不同的阶段,每个阶段都是一个扩展点,用户可以在这些扩展点实现自己的插件和需要的功能。我们正在做的是 Filter 定制,Post-bind定制,并且与监控打通和任务画像。
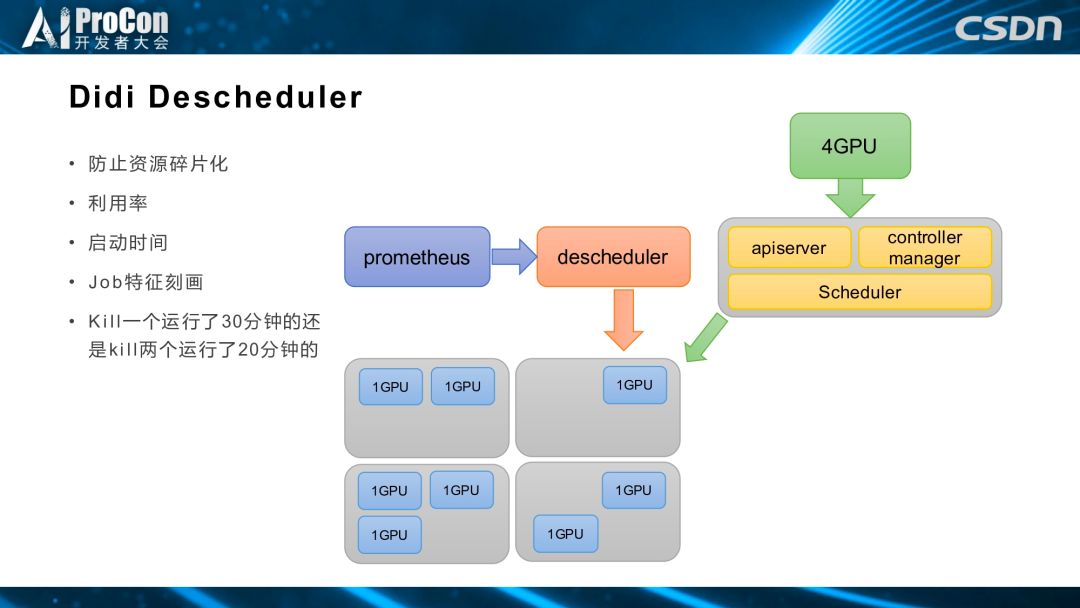
再调度器的主要目的是防止集群中的资源碎片化,比如上图的集群中分别有一、二、三不同个数一卡离线任务,如果有四卡离线任务到来,会对这个节点形成抢占,一卡离线任务之前运行的一些流程就被迫中断了,或者如果模型没有保存就没用了。我们做再调度器是为了提前发现这种状况,和监控系统打通,通过再调度器来驱逐一卡离线任务,让它重新通过调度器的紧凑调度,调度到这台机器上,这样就可以提前空出机器,供后续的四卡离线任务使用。但是,这也涉及到当前正在运行的异卡离线任务启动时间,以及任务的特征刻画。举例来说,驱逐一个卡运行 30 分钟还是驱逐两个卡运行 20 分钟,都是我们需要考虑的问题。

此外,我们也在开发 device plugin,以实现实验环境和离线任务的混合调度,但暂时不便透露太多信息。

未来,我们希望借助 k8s 提供多机多卡服务,现在多机多卡是在管控这一层实现的,我们希望放到调度这一层,以更好地利用 k8s 的调度能力,为用户提供更好的体验,打造一站式机器学习平台。同时也把更多大数据任务放到这个平台上,比如 Spark等。以及提供更好的在离线混合调度,来进一步提高集群的资源分配率和利用率。
目前,滴滴机器学习平台着力发展公有云,让机器学习平台不但在内部使用,也可以提供给更多外部同行使用。

再细一点讲,希望可以为从硬件选型到基础设施,到整个上层软件栈,提供一个内外统一的架构,减少内外两部分的重复性工作。比如针对上图中底部的 IaaS 和Paas层,我们希望提供内外统一的资源,如机器学习平台简枢、算法市场、模型市场、数据市场等,基于这些底层服务,在 SaaS 层提供人脸、语音、自然语言处理和智能视频识别和其他图像、地图服务。
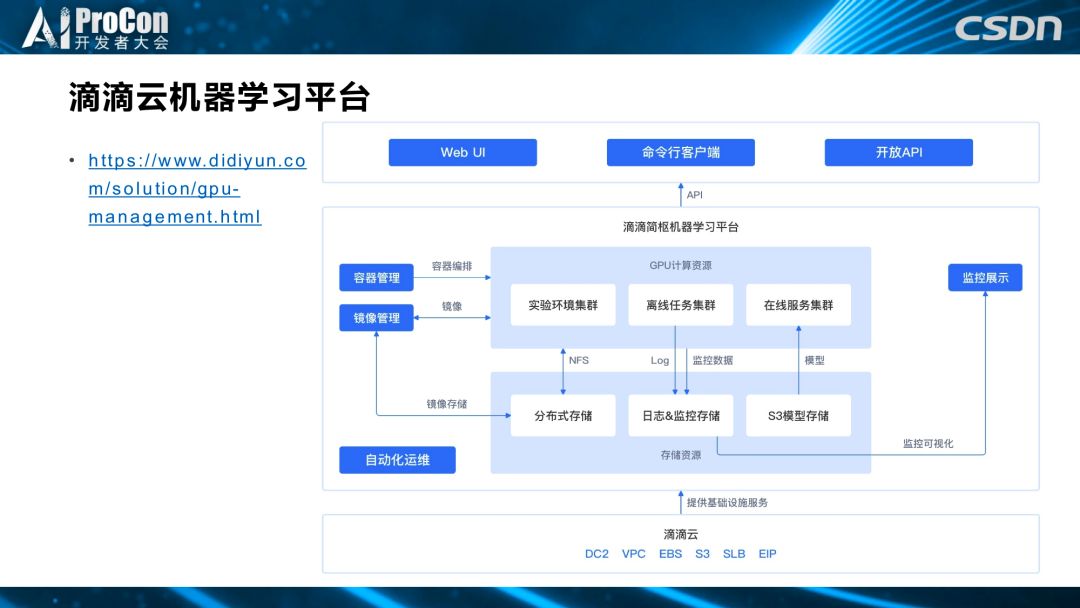
现在,滴滴机器学习平台已经在滴滴公有云平台上,上图为架构图,如果想了解详细内容可以访问网站。
演讲嘉宾:
唐博,滴滴出行资深软件工程师,曾就职于高盛美国、高盛香港,现就职于滴滴出行,负责机器学习平台调度系统,是kubernetes, istio, kubeflow, alluxio等开源项目的代码贡献者。
(*本文为AI科技大本营整理文章,转载请微信联系 1092722531)
开幕倒计时5天|2019 中国大数据技术大会(BDTC)即将震撼来袭!豪华主席阵容及百位技术专家齐聚,十余场精选专题技术和行业论坛,超强干货+技术剖析+行业实践立体解读。6.6 折票限时特惠(立减1400元)倒计时 2 天,学生票仅 599 元!











