一、相关知识点回顾
1、需要使用的相关库
import numpy as np
import pandas as pd
import os
import xlsxwriter
import xlrd
2、os.walk(pwd):传入一个文件路径pwd。
1)作用如下

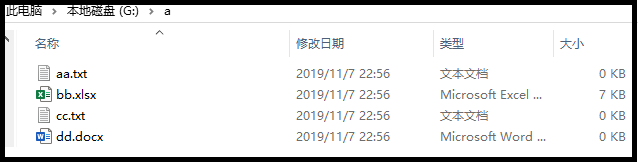
2)案例演示:以我电脑中“G:\a”文件夹下的文件为例,进行说明。
① 先来看看“G:\a”文件夹下有哪些东西。
② 代码实现
pwd = "G:\\a"
print(os.walk(pwd))
for i in os.walk(pwd):
print(i)
for path,dirs,files in os.walk(pwd):
print(files)```
结果如下:
<generator object walk at 0x0000029BB5AEAB88>
('G:\\a', [], ['aa.txt', 'bb.xlsx', 'cc.txt', 'dd.docx'])
['aa.txt', 'bb.xlsx', 'cc.txt', 'dd.docx']
结果分析:
首先,我们使用print直接打印os.walk(pwd)的结果,显示的是一个生成器generator,我们并不能查看到其中的内容,而是需要遍历获取其中的内容。
接着,我们写了一个for循环,并使用了一个变量,接收os.walk(pwd)的返回值,可以看到返回的结果是一个元组。在这个元组中,第一个元素返回的是传入的pwd路径;第二个元素,返回的是a目录下的子目录文件夹组成的列表,由于在a目录下没有其它的子文件夹,因此返回的是一个空列表;第三个元素,返回的是a目录下的子文件组成的列表。
最后,我们使用三个变量,分别接收os.walk(pwd)的返回值,并且只打印输出了files这个变量,可以看到,这是一个由a目录下所有子文件组成的列表。
注意一:上述所说的a目录下的子目录,指的是a目录下的直接子目录,不包括a子目录下的子目录。
注意二:上述所说的a目录下的子文件,指的是a目录下的直接子文件,不包括a子目录下的子文件。
3、os.path.join(path1,path2…)
1)作用如下:用于将多个路径组合后返回。
2)案例演示
path1 = 'G:\\a'
path2 = 'aa.txt'
print(os.path.join(path1,path2))
结果如下:
G:\a\aa.txt
结果分析
从上述结果中可以看出:利用os.path.join(path1,path2),是不是可以帮助我们获取到aa.txt的全路径。利用这种思想,假如某个目录下有多个excel,我们是不是可以结合使用os.walk和os.path.join,来得到每一个excel文件的全路径,之后依据这个全路径对excel进行操作,是不是显得很方便。
4、os.walk和os.path.join使用的综合案例
1)需求如下
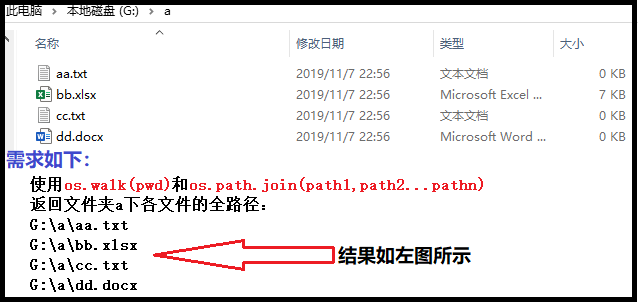
2)实现如下
file_path_list = []
for path,dirs,files in os.walk(pwd):
for file in files:
file_path_list.append(os.path.join(path,file))
print(file_path_list)
结果如下:
[
'G:\\a\\aa.txt','G:\\a\\bb.xlsx','G:\\a\\cc.txt','G:\\a\\dd.docx']
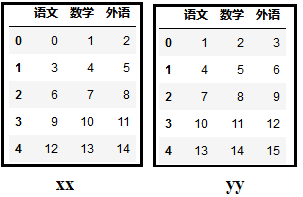
5、如何将多个Dataframe进行纵向拼接?
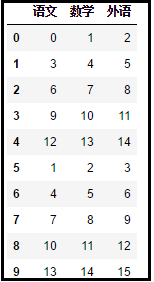
1)创建两个dataframe数据框xx和yy。
import numpy as np
xx = np.arange(15).reshape(5,3)
yy = np.arange(1,16).reshape(5,3)
xx = pd.DataFrame(xx,columns=["语文","数学","外语"])
yy = pd.DataFrame(yy,columns=["语文","数学","外语"])
print(xx)
print(yy)
效果如下:
2)将上述两个dataframe进行横纵向拼接。
concat_list = []
concat_list.append(xx)
concat_list.append(yy)
z = pd.concat(concat_list,ignore_list=True)
print(z)
效果如下:
二、多工作簿合并(一)
1、将多个Excel合并到一个Excel中(每个Excel中只有一个sheet表)
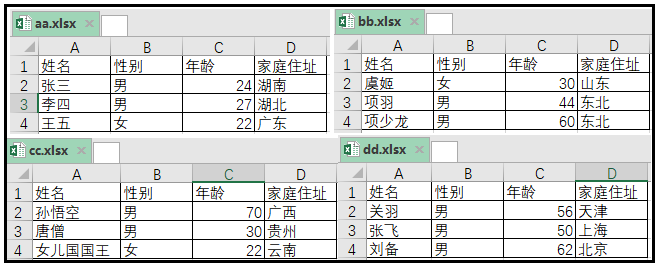
实现代码如下:
import pandas as pd
import os
pwd = "G:\\b"
df_list = []
for path,dirs,files in os.walk(pwd):
for file in files:
file_path = os.path.join(path,file)
df = pd.read_excel(file_path)
df_list.append(df)
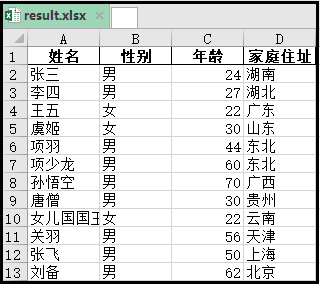
result = pd.concat(df_list)
print(result)
result.to_excel('G:\\b\\result.xlsx',index=False)
结果如下:
三、多工作簿合并(二)
1、xlsxwrite的用法讲解
1)创建一个"工作簿"。
import xlsxwriter
workbook = xlsxwriter.Workbook("demo.xlsx")
workbook.
close()
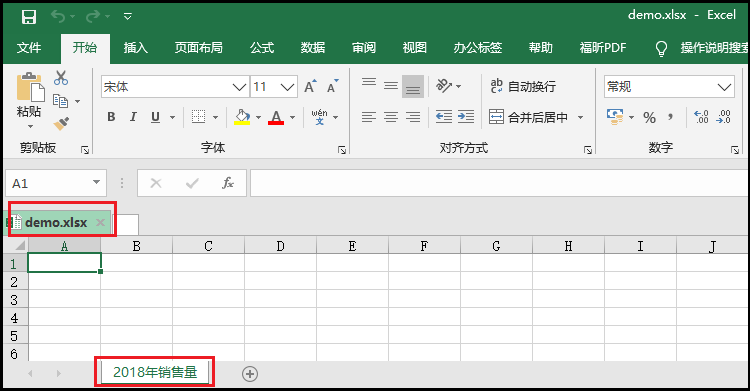
2)创建一个"工作簿",并给工作表命名为"2018年销量"。
import xlsxwriter
workbook = xlsxwriter.Workbook("cc.xlsx")
worksheet = workbook.add_worksheet("2018年销售量")
workbook.close()
效果如下:
3)在第二步的基础上,给"2018年销售量"工作表添加一个表头,并向其中插入一条数据。
import xlsxwriter
workbook = xlsxwriter.Workbook("demo.xlsx")
worksheet = workbook.add_worksheet("2018年销售量")
headings = ['产品','销量',"单价"]
worksheet.write_row('A1',headings)
data = ["苹果",500,8.9]
for i in range(len(headings)):
worksheet.write(1,i,data[i])
workbook.close()
效果如下:
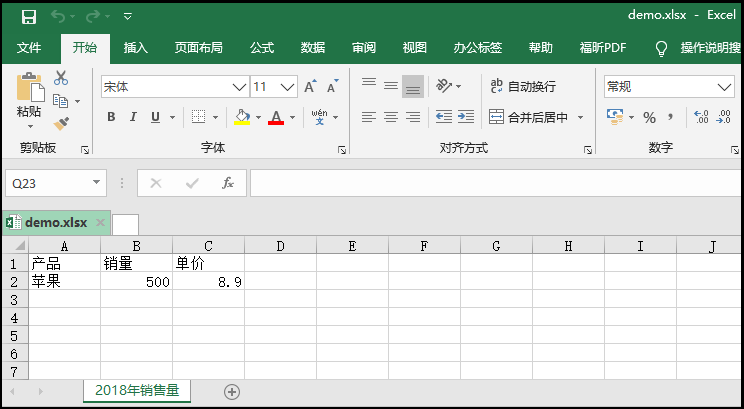
2、xlrd的用法讲解
1)利用test.xlsx工作簿讲解xlrd的使用原理
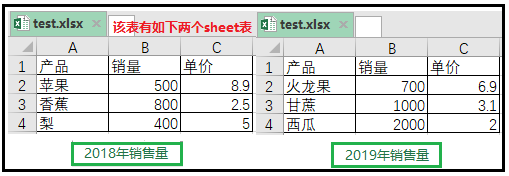
上述图展示的是一个工作簿test.xlsx下面,有两张sheet表。一张sheet表,命名为“2018年销售量”,一张sheet表,命名为“2019年销售量”。
2)open_workbook(file):使用该方法帮助我们打开一个excel文件,返回给我们"xlrd.book.Book"工作簿对象;
import xlrd
file = r"G:\Jupyter\test.xlsx"
xlrd.open_workbook(file)
<xlrd.book.Book at 0x29bb8e4eda0>
3)sheet_names():获取某个工作簿下,所有sheet表的表名。假如有多个sheet表,返回表名组成的一个列表;
import xlrd
file = r"G:\Jupyter\test.xlsx"
fh = xlrd.open_workbook(file)
fh.sheet_names()
['2018年销售量', '2019年销售量']
4)sheets()方法:返回的是sheet表的对象列表。
import xlrd
file = r"G:\Jupyter\test.xlsx"
fh = xlrd.open_workbook(file)
fh.sheets()
[<xlrd.sheet.Sheet at 0x29bb8f07a90>, <xlrd.sheet.Sheet at 0x29bb8ef1390>]
fh.
sheets()[0]
<xlrd.sheet.Sheet at 0x29bb8f07a90>
fh.sheets()[1]
<xlrd.sheet.Sheet at 0x29bb8ef1390>
5)nrows和ncols属性:返回每一个sheet表的行数(nrows) 和 列数(ncols);
import xlrd
file = r"G:\Jupyter\test.xlsx"
fh = xlrd.open_workbook(file)
fh.sheets()
fh.sheets()[0].nrows
fh.sheets()[0].ncols
fh.sheets()[1].nrows
fh.sheets()[1].ncols
6)row_values(行数):传入行数,获取sheet表中该行的数据;
(这个用处很大)
import xlrd
file = r"G:\Jupyter\test.xlsx"
fh = xlrd.open_workbook(file)
sheet1 = fh.sheets()[0]
for row in range(fh.sheets()[0].nrows):
value = sheet1.row_values(row)
print(value)
效果如下:

7)col_values(列数):传入列数,获取sheet表中该列的数据;
(这个用处不大)
import xlrd
file = r"G:\Jupyter\test.xlsx"
fh = xlrd.open_workbook(file)
sheet1 = fh.sheets()[0]
for col in range(fh.sheets()[0].ncols):
value = sheet1.col_values(col)
print(value)
效果如下:

3、将多个Excel表合并到一个Excel中(每个Excel中不只一个sheet表)
1)源数据
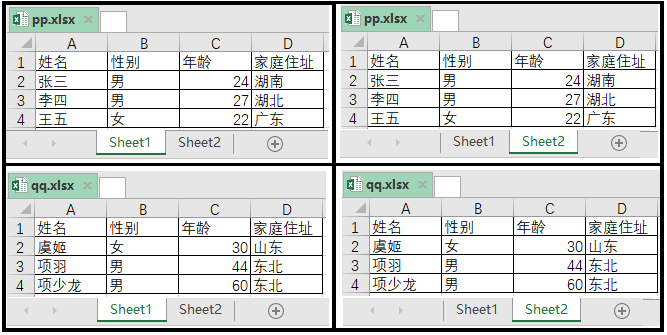
上述图展示的有两个工作簿,一个工作簿是pp.xlsx,一个工作簿是qq.xlsx。
工作簿pp.xlsx下,有两个工作表sheet1和sheet2。工作簿qq.xlsx下,也有两个工作表sheet1和sheet2。
2)使用面向过程实现上述表中数据合并
import xlrd
import xlsxwriter
import os
def open_xlsx(file):
fh=xlrd.open_workbook(
file)
return fh
def get_sheet_num(fh):
x = len(fh.sheets())
return x
def get_file_content(file,shnum):
fh=open_xlsx(file)
table=fh.sheets()[shnum]
num=table.nrows
for row in range(num):
rdata=table.row_values(row)
datavalue.append(rdata)
return datavalue
def get_allxls(pwd):
allxls = []
for path,dirs,files in os.walk(pwd):
for file in files:
allxls.append(os.path.join(path,file))
return allxls
datavalue = []
pwd = "G:\\d"
for fl in get_allxls(pwd):
fh = open_xlsx(fl)
x = get_sheet_num(fh)
for shnum in range(x):
print("正在读取文件:"+str(fl)+"的第"+str(shnum)+"个sheet表的内容...")
rvalue = get_file_content(fl,shnum)
endfile = "G:\\d\\concat.xlsx"
wb1=xlsxwriter.Workbook(endfile)
ws=wb1.add_worksheet()
for a in range(len(rvalue)):
for b in range(len(rvalue[a])):
c=rvalue[a][b]
ws.write(a,b,c)
wb1.close()
print("文件合并完成")
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
3)将上述代码封装后的效果如下
import xlrd
import xlsxwriter
import os
class Xlrd():
def __init__(self,pwd):
self.datavalue = []
self.pwd = pwd
def open_xlsx(self,fl):
fh=xlrd.open_workbook(fl)
return fh
def get_sheet_num(self,fh):
x = len(fh.sheets())
return x
def get_file_content(self,file,shnum):
fh = self.open_xlsx(file)
table=fh.sheets()[shnum]
num=table.nrows
for row in range(num):
rdata=table.row_values(row)
if rdata == ['姓名','性别','年龄','家庭住址']:
pass
else:
self.datavalue.append(rdata)
return self.datavalue
def get_allxls(self):
allxls = []
for path,dirs,files in os.walk(self.pwd):
for file in files:
allxls.append(os.path.join(path,file))
return allxls
def return_rvalue(self):
for fl in self.get_allxls():
fh = self.open_xlsx(fl)
x = self.get_sheet_num(fh)
for shnum in range(x):
print("正在读取文件:"+str(fl)+"的第"+str(shnum)+"个sheet表的内容...")
rvalue = self.get_file_content(fl,shnum)
return rvalue
class Xlsxwriter():
def __init__(self,endfile,rvalue):
self.endfile = endfile
self.rvalue = rvalue
def save_data(self):
wb1 = xlsxwriter.Workbook(endfile)
ws = wb1.add_worksheet("一年级(7)班")
ws = wb1.add_worksheet("2018年销售量")
headings = ['姓名','性别','年龄','家庭住址']
for a in range(len(self.rvalue)):
for b in range(len(self.rvalue[a])):
c = self.rvalue[a][b]
ws.write(a+1,b,c)
wb1.close()
print("文件合并完成")
pwd = "G:\\d"
xl = Xlrd(pwd)
rvalue = xl.return_rvalue()
endfile = "G:\\d\\concat.xlsx"
write = Xlsxwriter(endfile,rvalue)
write.save_data();
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
效果如下:
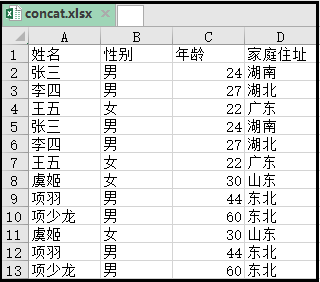
四、一个工作簿多sheet表合并。
1、将一个Excel表中的多个sheet表合并,并保存到同一个excel。
1)数据源
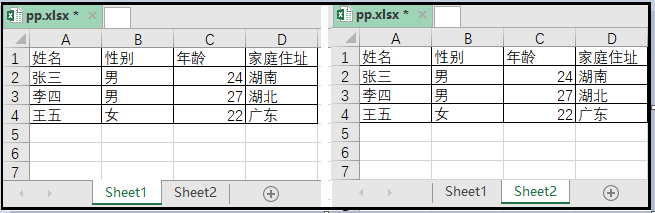
2)实现代码如下
import xlrd
import pandas as pd
from pandas import DataFrame
from openpyxl import load_workbook
excel_name = r"D:\pp.xlsx"
wb = xlrd.open_workbook(excel_name)
sheets = wb.sheet_names()
alldata = DataFrame()
for i in range(len(sheets)):
df = pd.read_excel(excel_name, sheet_name=i, index=False, encoding='utf8')
alldata = alldata.append(df)
writer = pd.ExcelWriter(r"C:\Users\Administrator\Desktop\score.xlsx",
engine='openpyxl')
book = load_workbook(writer.path)
writer.book = book
alldata.to_excel(excel_writer=writer,sheet_name="ALLDATA")
writer.save()
writer.close()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
效果如下:
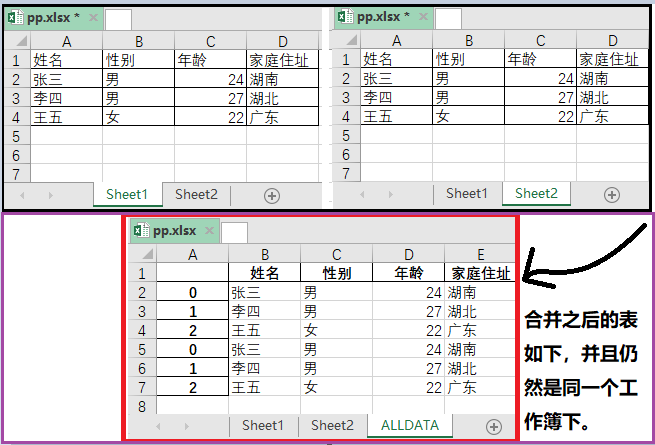
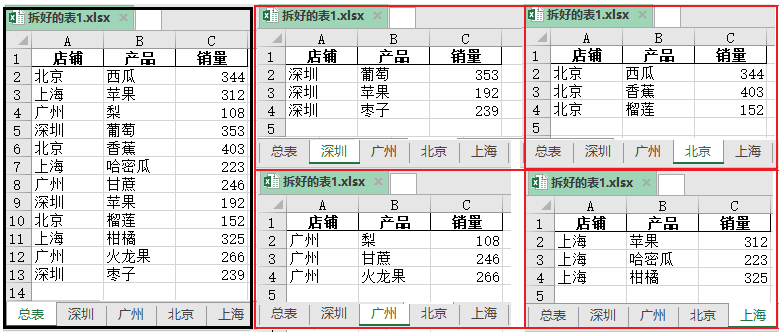
五、一表拆分(按照表中某一列进行拆分)
1、将一个Excel表,按某一列拆分成多张表。
1)数据源
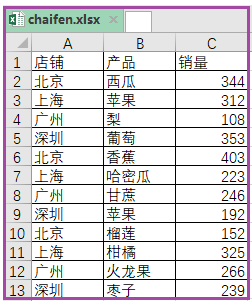
2)实现代码如下
import pandas as pd
import xlsxwriter
data=pd.read_excel(r"C:\Users\Administrator\Desktop\chaifen.xlsx",encoding='gbk')
area_list=list(set(data['店铺']))
writer=pd.ExcelWriter(r"C:\Users\Administrator\Desktop\拆好的表1.xlsx",engine='xlsxwriter')
data.to_excel(writer,sheet_name="总表",index=False)
for j in area_list:
df=data[data['店铺']==j]
df.to_excel(writer,sheet_name=j,index=False)
writer.save()
效果如下: