
文 | 标点符
出处 | biaodianfu.com
Prophet是Facebook开源的预测工具,相比ARIMA模型,Prophet真的是非常的简单。只要读入两列数据即可完成预测。且在某些环境下预测的准确性不输ARIMA。Prophet提供了R语言版本和Python版本,这里主要讲解的是Python版本。更多信息可产看官方链接。
Prophet的安装
fbprophet为Prophet在Python环境下的包,想要使用fbprohhet并没有想象中的那么简单,特别是在Windows系统上可能发生错误。主要原因是fbprophet基于pystan,pystan基于cython。问题会卡在pystan的安装上。
即正确的安装流程为:
pip install cython
pip install pystan
pip install fbprophet
在安装pystan时会报如下错误:WARNING:pystan:MSVC compiler is not supported 。具体原因可在官方说明中找到:
PyStan is partially supported under Windows with the following caveats:
Python 2.7: Doesn’t support parallel sampling. When drawing samples n_jobs=1 must be used)
Python 3.5 or higher: Parallel sampling is supported
MSVC compiler is not supported.
PyStan requires a working C++ compiler. Configuring such a compiler is typically the most challenging step in getting PyStan running.
PyStan is tested against the MingW-w64 compiler which works on both Python versions (2.7, 3.x) and supports x86 and x64.
Due to problems with MSVC template deduction, functions with Eigen library are failing. Until this and other bugs are fixed no support is provided for Windows + MSVC. Currently, no fix is known for this problem, other than to change the compiler to GCC or clang-cl.
解决方案为:将Python编译环境更改为MingW-w64。
下载MingW-w64,并进行安装,下载地址:https://osdn.net/projects/mingw/releases/
将mingw的路径添加到环境变量的PATH中,示例路径:C:\mingw-w64\x86_64-7.1.0-posix-seh-rt_v5-rev0\mingw64\bin
验证编译环境是否OK,验证方式为在cmd中执行如下命名 gcc –dumpversion、ld –v、dllwrap –version
修改Python内部编译设置,方法为在Python安装目录下(示例:C:\Python36\Lib\distutils),新建distutils.cfg文件,文件内容为
[build]
compiler = mingw32
完后后再执行安装即可。如果是Anaconda环境,除了上述步骤外,还需执行:
conda update conda
conda install libpython m2w64-toolchain -c msys2
Prophet的使用
数据集:https://pan.baidu.com/s/1Pw8ZSQgD8vLJjiQUhIJv_A 提取码: taav
import pandas as pd
from fbprophet import Prophet
import matplotlib.pyplot as plt
data = pd.read_csv('AirPassengers.csv', parse_dates=['Month'])
print(data.head())
Month AirPassengers
0 1949-01-01 112
1 1949-02-01 118
2 1949-03-01 132
3 1949-04-01 129
4 1949-05-01
121
Prophet 的输入量必须包含两列的数据框:ds 和 y 。ds 列为时间格式。y 列必须是数值变量,表示我们希望去预测的量。属于拿到数据后需要修改列名:
data = data.rename(columns={'Month': 'ds', 'AirPassengers': 'y'})
print(data.head())
ds y
0 1949-01-01 112
1 1949-02-01 118
2
1949-03-01 132
3 1949-04-01 129
4 1949-05-01 121
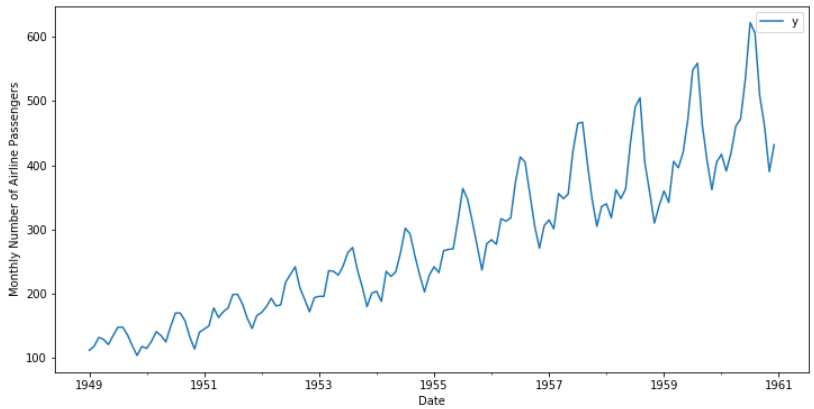
观察数据:
ax = data.set_index('ds').plot(figsize=(12, 6))
ax.set_ylabel('Monthly Number of Airline Passengers')
ax.
set_xlabel('Date')
plt.show()
Prophet 遵循 sklearn 库建模的应用程序接口。我们创建了一个 Prophet 类的实例,其中使用了“拟合模型” fit 和“预测” predict 方法。默认情况下, Prophet 的返回结果中会包括预测值 yhat 的预测区间。当然,预测区间的估计需建立在一些重要的假设前提下。在预测时,不确定性主要来源于三个部分:趋势中的不确定性、季节效应估计中的不确定性和观测值的噪声影响。
趋势中的不确定性
预测中,不确定性最大的来源就在于未来趋势改变的不确定性。在之前教程中的时间序列实例中,我们可以发现历史数据具有明显的趋势性。Prophet 能够监测并去拟合它,但是我们期望得到的趋势改变究竟会如何走向呢?或许这是无解的,因此我们尽可能地做出最合理的推断,假定 “未来将会和历史具有相似的趋势” 。
尤其重要的是,我们假定未来趋势的平均变动频率和幅度和我们观测到的历史值是一样的,从而预测趋势的变化并通过计算,最终得到预测区间。这种衡量不确定性的方法具有以下性质:变化速率灵活性更大时,预测的不确定性也会随之增大。原因在于如果将历史数据中更多的变化速率加入了模型,也就代表我们认为未来也会变化得更多,就会使得预测区间成为反映过拟合的标志。预测区间的宽度(默认下,是 80% )可以通过设置 interval_width 参数来控制:
my_model = Prophet(interval_width=0.95) #设置置信空间为95%(如果不设置的话默认80%)
my_model.fit(data)
由于预测区间估计时假定未来将会和过去保持一样的变化频率和幅度,而这个假定可能并不正确,所以预测区间的估计不可能完全准确。
季节效应估计中的不确定性
默认情况下, Prophet 只会返回趋势中的不确定性和观测值噪声的影响。你必须使用贝叶斯取样的方法来得到季节效应的不确定性,可通过设置 mcmc.samples 参数(默认下取 0 )来实现。
my_model = Prophet(interval_width=
0.95, mcmc_samples=500) #设置置信空间为95%(如果不设置的话默认80%)
my_model.fit(data)
上述代码将最大后验估计(MAP)取代为马尔科夫蒙特卡洛取样(MCMC)。执行后可通过绘图的方式直观的观测到季节效应的不确定性。
观测值的噪声影响
处理异常值最好的方法是移除它们,而 Prophet 使能够处理缺失数据的。如果在历史数据中某行的值为空(NA),但是在待预测日期数据框 future 中仍保留这个日期,那么 Prophet 依旧可以给出该行的预测值。
预测将会建立在一列包含日期 ds 的数据框基础上来预测指定日期的数据。make_future_dataframe 函数使用模型对象和一段待预测的时期去构建一个相应的包含待预测日期的数据框。默认情况下,该函数将会自动包含历史数据的日期,因此可用来分析训练集的拟合效果。
future_dates = my_model.make_future_dataframe(periods=36, freq='MS')
print(future_dates.head())
ds
0 1949-01-01
1 1949-02-01
2 1949-03-01
3 1949-04-01
4 1949-05-01
在Prophet中使用通用的 predict 函数来预测数据。预测结果 forecast 对象是包含了预测值 yhat 的数据框,此外,还有其余的列用来储存估计的置信区间和季节因子。
forecast = my_model.predict(future_dates)
forecast[['ds', 'yhat', 'yhat_lower', 'yhat_upper']].
tail()
ds yhat yhat_lower yhat_upper
175 1963-08-01 659.473243 592.176200 726.973325
176 1963-09-01 613.132606 542.378855 677.590035
177 1963-10-01 576.340290 505.417141 642.690391
178 1963-11-01 545.832790 478.427462 610.037598
179 1963-12-01 575.599488 501.734482 649.450637
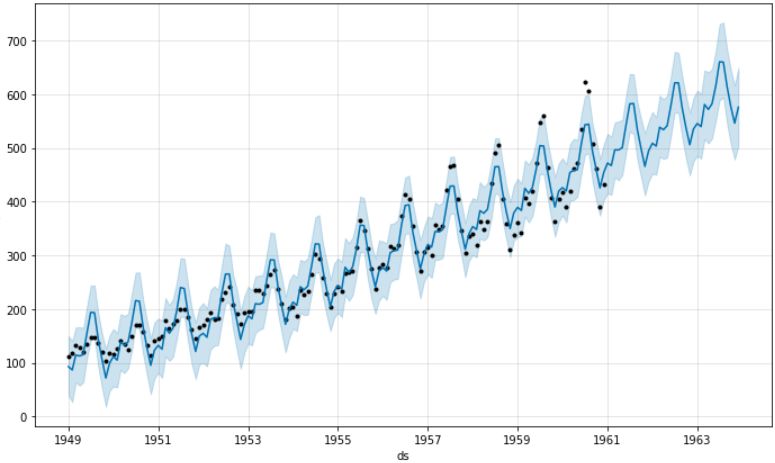
查看预测效果:my_model.plot(forecast, uncertainty\=True)
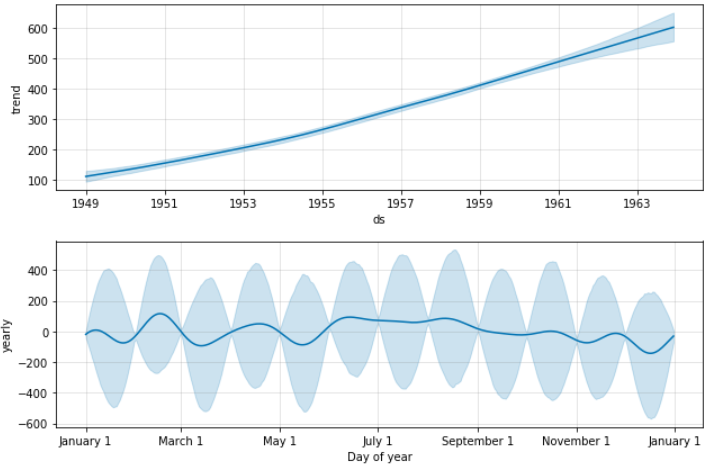
查看分解效果:my_model.plot_components(forecast)
更多参考:https://facebook.github.io/prophet/
原文:https://www.biaodianfu.com/fbprophet.html
(都看到这里了,给文章点个‘在看’呗!)
推荐阅读:










