
向AI转型的程序员都关注了这个号👇👇👇
机器学习AI算法工程 公众号:datayx
1. LR为什么是线性模型

2. LR如何解决低维不可分
特征映射:通过特征变换的方式把低维空间转换到高维空间,而在低维空间不可分的数据,到高维空间中线性可分的几率会高一些。具体方法:核函数,如:高斯核,多项式核等等。
3. 从图模型角度看LR(现在还不是很懂其他生成模型,以后补上)
LR模型可以看作是CRF模型的低配版,在完全不定义随机变量交互,只考虑P(Y|X)的情况下,得到的就是LR模型。
最大熵相比LR,可以提取多组特征(最大熵定义了多个特征函数),本质上等价的。CRF又是最大熵模型序列化的推广。
本质上,LR和softmax是等价的,而且也可证最大熵和softmax也等价,即可证LR和最大熵的等价性LR(最大熵模型)统计的是训练集中的各种数据满足特征函数的频数(conditional);贝叶斯模型统计的是训练集中的各种数据的频数;CRF统计的是训练集中相关数据 (比如说相邻的词,不相邻的词不统计) 满足特征函数的频数。
PS,最大熵模型和CRF的区别:最大熵模型在每个状态都有一个概率模型,在每个状态转移时都要进行归一化。如果某个状态只有一个后续 状态,那么该状态到后续状态的跳转概率即为1。这样,不管输入为任何内容,它都向该后续状态跳转。而CRFs是在所有的状态上建立一个统一的概率模型,这 样在进行归一化时,即使某个状态只有一个后续状态,它到该后续状态的跳转概率也不会为1,从而解决了“labelbias”问题。因此,从理论上 讲,CRFs非常适用于中文的词性标注。
参考链接:
https://zhuanlan.zhihu.com/p/34261803
https://www.cnblogs.com/ooon/p/5829341.html
4. LR的损失函数



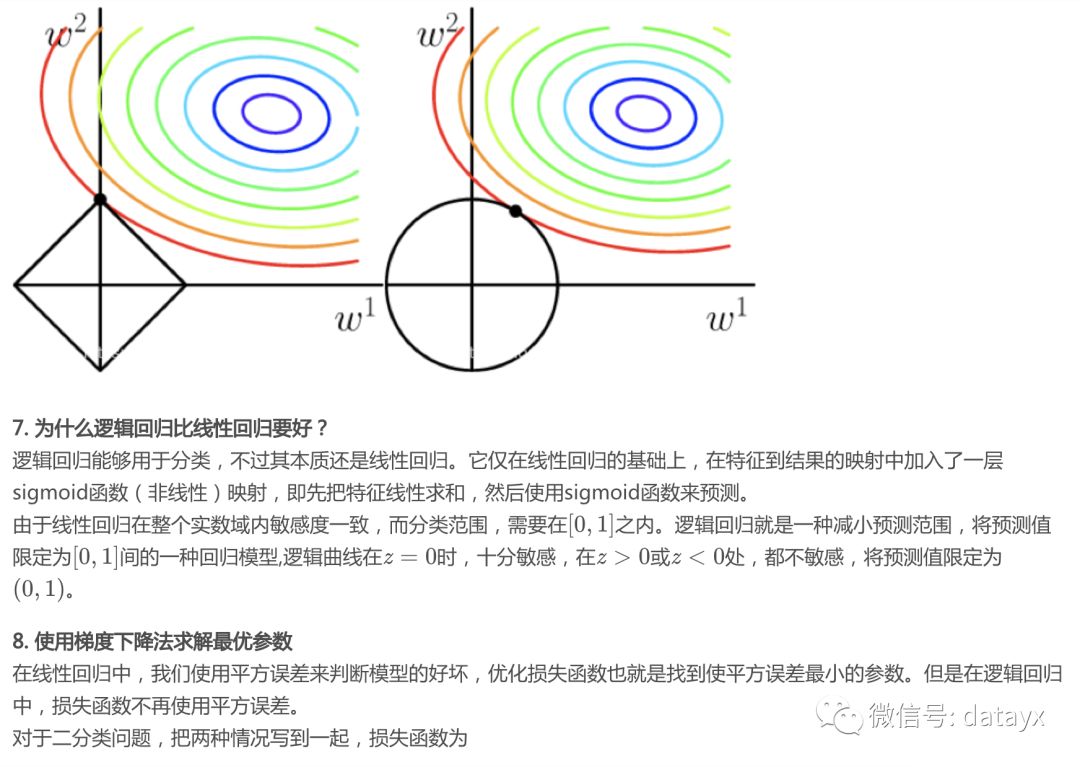

这里再强调一下,L2L2L2正则能够平滑损失函数,减少过拟合的可能。但是正则系数要选对,如果选得过大,或造成平滑过渡从而导致过拟合;如果选小了,小到与0差不多,那就相当于没有正则项,发生过拟合的可能性会增大。
对带正则项的损失求梯度:

9. LR 如何解决多分类问题
如果y不是在[0,1]中取值,而是在K个类别中取值,这时问题就变为一个多分类问题。有两种方式可以出处理该类问题:一种是我们对每个类别训练一个二元分类器(One-vs-all),当K个类别不是互斥的时候,比如用户会购买哪种品类,这种方法是合适的。如果K个类别是互斥的,即 y=i 的时候意味着 y 不能取其他的值,比如用户的年龄段,这种情况下 Softmax 回归更合适一些。Softmax 回归是直接对逻辑回归在多分类的推广,相应的模型也可以叫做多元逻辑回归(Multinomial Logistic Regression)。模型通过 softmax 函数来对概率建模,具体形式如下:

10. LR和SVM的区别
首先是两者的共同点:
LR和SVM都是分类算法
如果不考虑核函数,LR和SVM都是线性分类算法,即分类决策面都是线性的
LR和SVM都是有监督学习算法
LR和SVM都是判别模型
模型作为统计学习的三要素之一(模型,策略,算法)
模型:学习什么样的模型,模型就是所要学习的条件概率分布或者说是决策函数,ps有监督学习和无监督学习都要训练一个模型,然后泛化应用
策略:按照什么样的准则学习或者选择最优的模型,包括损失函数和风险函数,损失函数是一次的好坏,风险函数是平均的好坏
常用的损失函数有0-1损失函数,平方损失函数,绝对值损失函数和对数损失函数,认为损失函数值越小,模型就越好
经验风险就是模型关于联合分布的期望损失,经验风险最小化(ERM)策略就认为经验风险最小的模型为最优模型,最大似然估计就是经验风险最小化的一个例子
结构风险最小化就等价于正则化,加入正则化项或者惩罚项,往往对训练数据和测试数据都有很好的预测(避免对于训练数据的过拟合问题,具有较好的泛化能力),贝叶斯估计中的最大后验概率估计就是结构风险最小化的例子
算法:也就是指学习模型的具体计算方法,统计学习通常归结为最优化问题,如何保证找到全局最优解,并使求解过程非常高效,就需要好的最优化算法
判别模型主要有:K近邻,感知机(SVM),决策树,逻辑斯蒂回归(LR),最大熵模型,提升方法(boost)和条件随机场
与判别模型对应的是生成模型,比如朴素贝叶斯,隐马尔可夫模型
两者的区别是生成模型由数据求得联合概率分布P(X, Y),然后求出条件概率分布P(Y|X)作为预测
而判别模型由数据直接求得决策函数f(x),或者条件概率分布P(Y|X)
判别模型的特点:直接面对预测,准确率高;可以简化学习问题,对数据进行各种程度的抽象,定义特征等
生成模型的特点:可以还原出联合概率密度;收敛速度快,当样本容量增加时也能很快的收敛;存在隐变量时,仍可以使用
两者的不同点:
损失函数的不同,逻辑回归采用的是log loss(对数损失函数),svm采用的是hinge loss(合页损失函数)
分类原理的不同,LR基于概率理论,通过极大似然估计的方法估计出参数的值,而SVM基于几何间隔最大化原理,认为存在最大几何间隔的分类面为最优分类面,从最大间隔出发,转化为求对变量w和b的凸二次规划问题
由于分类原理的不同,也导致了LR是所有样本都有影响,而SVM只是少量样本有影响的(支持向量),在支持向量外添加样本点是没有影响的
正因为LR受数据影响较大,所以在数据不同类别时,要先对数据做balancing
同样的,由于SVM依赖数据表达的距离测度,所以要先对数据做normalization标准化
对于线性不可分的情况,SVM的核函数可以帮助将低维不可分的数据转换到高维,变成线性可分的,而LR很少用到核函数(并不是没有。。)假设我们在LR里也运用核函数的原理,那么每个样本点都必须参与核计算,这带来的计算复杂度是相当高的。所以,在具体应用时,LR很少运用核函数机制。
SVM的损失函数就自带正则(损失函数中的1/2||w||^2项),这就是为什么SVM是结构风险最小化算法的原因,而LR必须另外在损失函数上添加正则化
关于LR和SVM的选择:
如果Feature的数量很大,跟样本数量差不多,这时候选用LR或者是Linear Kernel的SVM
如果Feature的数量比较小,样本数量一般,不算大也不算小,选用SVM+Gaussian Kernel
如果Feature的数量比较小,而样本数量很多,需要手工添加一些feature变成第一种情况
11. LR的优化方法
逻辑回归本身是可以用公式求解的,但是因为需要求逆的复杂度太高,所以才引入了梯度下降算法。
一阶方法:梯度下降、随机梯度下降、mini 随机梯度下降降法。随机梯度下降不但速度上比原始梯度下降要快,局部最优化问题时可以一定程度上抑制局部最优解的发生。
二阶方法:牛顿法、拟牛顿法:
牛顿法其实就是通过切线与x轴的交点不断更新切线的位置,直到达到曲线与x轴的交点得到方程解。在实际应用中我们因为常常要求解凸优化问题,也就是要求解函数一阶导数为0的位置,而牛顿法恰好可以给这种问题提供解决方法。实际应用中牛顿法首先选择一个点作为起始点,并进行一次二阶泰勒展开得到导数为0的点进行一个更新,直到达到要求,这时牛顿法也就成了二阶求解问题,比一阶方法更快。我们常常看到的x通常为一个多维向量,这也就引出了Hessian矩阵的概念(就是x的二阶导数矩阵)。缺点:牛顿法是定长迭代,没有步长因子,所以不能保证函数值稳定的下降,严重时甚至会失败。还有就是牛顿法要求函数一定是二阶可导的。而且计算Hessian矩阵的逆复杂度很大。
拟牛顿法:不用二阶偏导而是构造出Hessian矩阵的近似正定对称矩阵的方法称为拟牛顿法。拟牛顿法的思路就是用一个特别的表达形式来模拟Hessian矩阵或者是他的逆使得表达式满足拟牛顿条件。主要有DFP法(逼近Hession的逆)、BFGS(直接逼近Hession矩阵)、 L-BFGS(可以减少BFGS所需的存储空间)
12.一元线性回归的基本假设有?
随机误差项是一个期望值或平均值为0的随机变量;
对于解释变量的所有观测值,随机误差项有相同的方差;
随机误差项彼此不相关;
解释变量是确定性变量,不是随机变量,与随机误差项彼此之间相互独立;
解释变量之间不存在精确的(完全的)线性关系,即解释变量的样本观测值矩阵是满秩矩阵;
随机误差项服从正态分布
违背基本假设的计量经济学模型还是可以估计的,只是不能使用普通最小二乘法进行估计。
当存在异方差时,普通最小二乘法估计存在以下问题:参数估计值虽然是无偏的,但不是最小方差线性无偏估计。
杜宾-瓦特森(DW)检验,计量经济,统计分析中常用的一种检验序列一阶 自相关 最常用的方法。
7. 完全共线性下参数估计量不存在
8. 近似共线性下OLS估计量非有效
多重共线性使参数估计值的方差增大,1/(1-r2)为方差膨胀因子(Variance Inflation Factor, VIF)
9. 参数估计量经济含义不合理
10. 变量的显著性检验失去意义,可能将重要的解释变量排除在模型之外
11. 模型的预测功能失效。变大的方差容易使区间预测的“区间”变大,使预测失去意义。
13. 线性回归中的多重共线性问题
所谓多重共线性(Multicollinearity)是指线性回归模型中的解释变量之间由于存在精确相关关系或高度相关关系而使模型估计失真或难以估计准确。
14. 关于逻辑回归,连续特征离散化的好处
在工业界,很少直接将连续值作为特征喂给逻辑回归模型,而是将连续特征离散化为一系列0、1特征交给逻辑回归模型,这样做的优势有以下几点:
稀疏向量内积乘法运算速度快,计算结果方便存储,容易scalable(扩展)。
离散化后的特征对异常数据有很强的鲁棒性:比如一个特征是年龄>30是1,否则0。如果特征没有离散化,一个异常数据“年龄300岁”会给模型造成很大的干扰。
逻辑回归属于广义线性模型,表达能力受限;单变量离散化为N个后,每个变量有单独的权重,相当于为模型引入了非线性,能够提升模型表达能力,加大拟合。
离散化后可以进行特征交叉,由M+N个变量变为M*N个变量,进一步引入非线性,提升表达能力。
特征离散化后,模型会更稳定,比如如果对用户年龄离散化,20-30作为一个区间,不会因为一个用户年龄长了一岁就变成一个完全不同的人。当然处于区间相邻处的样本会刚好相反,所以怎么划分区间是门学问。
大概的理解:1)计算简单;2)简化模型;3)增强模型的泛化能力,不易受噪声的影响。
Python机器学习:逻辑回归算法以及多类分类
原文地址 https://blog.csdn.net/weixin_44915167/article/details/89377022
阅读过本文的人还看了以下文章:
【全套视频课】最全的目标检测算法系列讲解,通俗易懂!
《美团机器学习实践》_美团算法团队.pdf
《深度学习入门:基于Python的理论与实现》高清中文PDF+源码
python就业班学习视频,从入门到实战项目
2019最新《PyTorch自然语言处理》英、中文版PDF+源码
《21个项目玩转深度学习:基于TensorFlow的实践详解》完整版PDF+附书代码
《深度学习之pytorch》pdf+附书源码
PyTorch深度学习快速实战入门《pytorch-handbook》
【下载】豆瓣评分8.1,《机器学习实战:基于Scikit-Learn和TensorFlow》
《Python数据分析与挖掘实战》PDF+完整源码
汽车行业完整知识图谱项目实战视频(全23课)
李沐大神开源《动手学深度学习》,加州伯克利深度学习(2019春)教材
笔记、代码清晰易懂!李航《统计学习方法》最新资源全套!
《神经网络与深度学习》最新2018版中英PDF+源码
将机器学习模型部署为REST API
FashionAI服装属性标签图像识别Top1-5方案分享
重要开源!CNN-RNN-CTC 实现手写汉字识别
yolo3 检测出图像中的不规则汉字
同样是机器学习算法工程师,你的面试为什么过不了?
前海征信大数据算法:风险概率预测
【Keras】完整实现‘交通标志’分类、‘票据’分类两个项目,让你掌握深度学习图像分类
VGG16迁移学习,实现医学图像识别分类工程项目
特征工程(一)
特征工程(二) :文本数据的展开、过滤和分块
特征工程(三):特征缩放,从词袋到 TF-IDF
特征工程(四): 类别特征
特征工程(五): PCA 降维
特征工程(六): 非线性特征提取和模型堆叠
特征工程(七):图像特征提取和深度学习
如何利用全新的决策树集成级联结构gcForest做特征工程并打分?
Machine Learning Yearning 中文翻译稿
蚂蚁金服2018秋招-算法工程师(共四面)通过
全球AI挑战-场景分类的比赛源码(多模型融合)
斯坦福CS230官方指南:CNN、RNN及使用技巧速查(打印收藏)
python+flask搭建CNN在线识别手写中文网站
中科院Kaggle全球文本匹配竞赛华人第1名团队-深度学习与特征工程
不断更新资源
深度学习、机器学习、数据分析、python
搜索公众号添加: datayx

长按图片,识别二维码,点关注
机器学习算法资源社群
不断上传电子版PDF资料
技术问题求解
QQ群号: 333972581
长按图片,识别二维码









