关注“SIGAI公众号”,选择“星标”或“置顶”
原创技术文章,第一时间获取
本文是机器学习和深度学习习题集答案的第2部分,也是《机器学习-原理、算法与应用》一书的配套产品。此习题集可用于高校的机器学习与深度学习教学,以及在职人员面试准备时使用。
1.解释LDA的原理。
LDA是有监督的降维算法,它将数据向量向最大化类间差异,最小化类内差异的方向投影。
2.推导两个类和二维时LDA的投影矩阵计算公式。
假设有n个样本,它们的特征向量为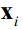 ,这些样本属于两个类。属于类
,这些样本属于两个类。属于类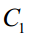 的样本集为
的样本集为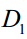 ,有
,有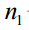 个样本;属于类
个样本;属于类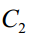 的样本集为
的样本集为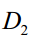 ,有
,有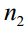 个样本。投影向量为w,所有向量对该向量做投影可以得到一个标量
个样本。投影向量为w,所有向量对该向量做投影可以得到一个标量
类内差异由每个类的类内散布之和而定义,类内散布定义为
LDA寻找投影方向的目标是使得类间差异与类内差异的比值最大化
这个最优化问题的解不唯一,如果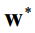 是最优解,将它乘上一个非零系数k之后,
是最优解,将它乘上一个非零系数k之后,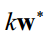 还是最优解。可以加上一个约束条件消掉冗余,同时简化问题。为w加上如下约束
还是最优解。可以加上一个约束条件消掉冗余,同时简化问题。为w加上如下约束
这里的目标是要让该比值最大化,因此最大的特征值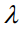 及其对应的特征向量是最优解。
及其对应的特征向量是最优解。
3.解释LDA降维算法的流程。
首先计算投影矩阵,流程为:
1.计算各个类的均值向量与总均值向量。
2.计算类间散布矩阵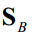 ,类内散布矩阵
,类内散布矩阵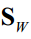 。
。
3.计算矩阵乘法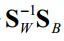 。
。
4.对进行特征值分解,得到特征值和特征向量。
5.对特征值从大到小排序,截取部分特征值和特征向量构成投影矩阵。
接下来进行降维,流程为:
1.将样本减掉均值向量。
2.左乘投影矩阵,得到降维后的向量。
4.解释LDA重构算法的流程。
1.输入向量左乘投影矩阵的转置矩阵。
2.加上均值向量,得到重构后的结果。
5.LDA是有监督学习还是无监督学习?
LDA利用了每个样本的类别标签,是有监督学习算法。
1.神经网络为什么需要激活函数?
保证神经网络的映射是非线性的,如果不使用激活函数,无论神经网络有多少层,其所表示的复合函数还是一个线性函数。
2.推导sigmoid函数的导数计算公式。
sigmoid函数定义为
3.激活函数需要满足什么数学条件?
激活函数需要满足:
1.非线性。保证神经网络实现的映射是非线性的。
2.几乎处处可导。保证可以用梯度下降法等基于导数的算法进行训练。
3.单调递增或者递减。保证满足万能逼近定理的要求,且目标函数有较好的特性。
4.为什么激活函数只要求几乎处处可导而不需要在所有点处可导?
如果将激活函数的输入值看作连续型随机变量,如果激活函数几乎处处可导,则在训练时激活函数的输入值落在不可导点处的概率为0。
5.什么是梯度消失问题,为什么会出现梯度消失问题?
在用反向传播算法计算误差项时每一层都要乘以本层激活函数的导数
如果激活函数导数的绝对值小于1,多次连乘之后误差项很快会衰减到接近于0,参数的梯度值由误差项计算得到,从而导致前面层的权重梯度接近于0,参数无法有效的更新,称为梯度消失问题。
6.如果特征向量中有类别型特征,使用神经网络时应该如何处理?
通常采用one hot编码,而不直接将类别编号整数值作为神经网络的输入。
7.对于多分类问题,神经网络的输出值应该如何设计?
类别标签通常采用one hot编码,输出层的神经元个数等于类别数。
8.神经网络参数的初始值如何设定?
一般用随机数进行初始化。
9.如果采用欧氏距离损失函数,推导输出层的梯度值。推导隐含层参数梯度的计算公式。
使用均方误差,则优化的目标为:
下面对单个样本的损失进行推导。神经网络每一层的变换为
对单个样本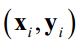 的损失函数为
的损失函数为
如果第l层是输出层,损失函数对输出层的临时变量的梯度为
假设梯度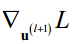 已经求出,有
已经求出,有
从输出层开始,利用上面的递推公式可以计算出每一层的误差项。根据每一层的误差项可以计算出损失函数对该层权重矩阵以及偏置项的梯度。对权重矩阵的梯度为
计算出损失函数对每一层参数的梯度值之后,可以用梯度下降法进行参数更新。
10.如果采用softmax+交叉熵的方案,推导损失函数对softmax输入变量的梯度值。
softmax变换为
其中x是本层的输入向量,
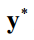 是概率估计向量,y是样本的真实标签值。交叉熵损失函数定义为
是概率估计向量,y是样本的真实标签值。交叉熵损失函数定义为
样本的类别标签中只有一个分量为1,其他都是0,这在第11.4节中已经介绍过。假设标签向量的第j个分量为1,该函数的导数为:
下面分两种情况讨论。如果i=j即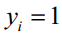 ,有:
,有:
此时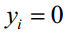 。将两种情况合并起来写成向量形式为:
。将两种情况合并起来写成向量形式为:
11.解释动量项的原理。
动量项累积了之前的权重更新值,加上此项之后的参数更新公式为
其中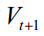 是动量项,计算公式为
是动量项,计算公式为
它是上一时刻的动量项与本次梯度值的加权平均值,其中α是学习率,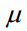 是动量项系数。如果按照时间t进行展开,则第t次迭代时使用了从1到t次迭代时的所有梯度值,且老的梯度值安
是动量项系数。如果按照时间t进行展开,则第t次迭代时使用了从1到t次迭代时的所有梯度值,且老的梯度值安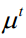 的系数指数级衰减。动量项是为了加快梯度下降法的收敛,它使用历史信息对当前梯度值进行修正,以抵消在病态条件问题上的来回震荡。
的系数指数级衰减。动量项是为了加快梯度下降法的收敛,它使用历史信息对当前梯度值进行修正,以抵消在病态条件问题上的来回震荡。
12.列举神经网络的正则化技术。
典型的正则化技术包括:
L1,L2或者谱正则化
Dropout
提前终止
13.推导ReLU函数导数计算公式。
ReLU函数定义为
14.神经网络训练时的目标函数是否为凸函数?
一般情况下不是凸函数。因此面临局部极小值和鞍点问题。
假设训练样本集有l个样本,特征向量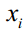 是n维向量,类别标签
是n维向量,类别标签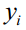 取值为+1或者-1,分别对应正样本和负样本。支持向量机预测函数的超平面方程为
取值为+1或者-1,分别对应正样本和负样本。支持向量机预测函数的超平面方程为
由于正样本的的类别标签为+1,负样本的类别标签为-1,可以统一写成
第二个要求是超平面离两类样本的距离要尽可能大。根据点到平面的距离公式,每个样本离分类超平面的距离为
上面的超平面方程有冗余,将方程两边都乘以不等于0的常数,还是同一个超平面,利用这个特点可以简化求解的问题。对w和b加上如下约束
目标是使得这个间隔最大化,这等价于最小化下面的目标函数
加上前面定义的约束条件之后,求解的优化问题可以写成
2.证明线性可分时SVM的原问题是凸优化问题且Slater条件成立
目标函数的Hessian矩阵是n阶单位矩阵,是严格正定矩阵,因此目标函数是严格凸函数。可行域是由线性不等式围成的区域,是一个凸集。因此这个优化问题是一个凸优化问题。
由于假设数据是线性可分的,因此一定存在w和b使得不等式约束严格满足。如果w和b是一个可行解
Slater条件成立。
3.推导线性可分时SVM的对偶问题
约束条件为
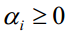 。
。
先固定住拉格朗日乘子α,调整w和b,使得拉格朗日函数取极小值。把α看成常数,对w和b求偏导数并令它们为0,得到如下方程组
4.证明加入松弛变量和惩罚因子之后,SVM的原问题是凸优化问题且Slater条件成立:
目标函数的前半部分是凸函数,后半部分是线性函数显然也是凸函数,两个凸函数的非负线性组合还是凸函数。上面优化问题的不等式约束都是线性约束,构成的可行域显然是凸集。因此该优化问题是凸优化问题。
如果令w=0,b=0,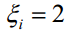 这是一组可行解,且有
这是一组可行解,且有
不等式条件严格满足,因此上述问题满足Slater条件。
5.推导线性不可分时SVM的对偶问题:
首先固定住乘子变量α和β,对w,b,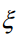 求偏导数并令它们为0,得到如下方程组
求偏导数并令它们为0,得到如下方程组
将上面的解代入拉格朗日函数中,得到关于α和β的函数
6.证明线性不可分时SVM的对偶问题是凸优化问题:
为了简化表述,定义矩阵Q,其元素为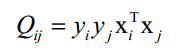
其中e是分量全为1的向量,y是样本的类别标签向量。Q可以写成一个矩阵和其自身转置的乘积
矩阵X为所有样本的特征向量分别乘以该样本的标签值组成的矩阵:
因此矩阵Q半正定,它就是目标函数的Hessian矩阵,目标函数是凸函数。上面问题的等式和不等式约束条件都是线性的,可行域是凸集,故对偶问题也是凸优化问题。
7.用KKT条件证明SVM所有样本满足如下条件:
将KKT条件其应用于原问题,对于原问题中的两组不等式约束,必须满足
对于第一个方程,如果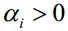 ,则必须有
,则必须有
而由于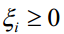 ,因此必定有
,因此必定有
再看第二种情况。如果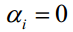 ,则对
,则对
,而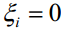 ,因此有
,因此有
将三种情况合并起来,在最优点处,所有的样本都必须要满足下面的条件
根据第二种情况可以计算出b的值。任意满足第二种情况的训练样本均可以计算出此值。
9.解释核函数的原理,列举常用的核函数。
如果样本线性不可分,可以对特征向量进行映射将它转化到更高维的空间,使得在该空间中线性可分。核映射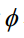 将特征向量变换到更高维的空间
将特征向量变换到更高维的空间
在对偶问题中计算的是两个样本向量之间的内积,映射后的向量在对偶问题中为
直接计算这个映射效率太低,而且不容易构造映射函数。如果映射函数选取得当,存在函数k,使得下面等式成立
这样只需先对向量用函数k进行计算,这等价于先对向量做核映射然后再做内积,这将能有效的简化问题的求解。
线性核:
10.什么样的函数可以作为核函数?
一个对称函数k(x,y)是核函数的条件是对任意的有限个样本的样本集,核矩阵半正定。核矩阵的元素是由样本集中任意两个样本的内积构造的一个数
11.解释SMO算法的原理。
SMO算法是一种分治法,每次挑选出两个变量进行优化,这个子问题可以得到解析解,而一个带等式和不等式约束的二次函数极值问题。
12.SMO算法如何挑选子问题的优化变量?
第一个变量的选择方法是在训练样本中选取违反KKT条件最严重的那个样本。首先遍历所有满足约束条件
的样本点,检查它们是否满足KKT条件。如果都满足KKT条件,则遍历整个训练样本集,判断它们是否满足KKT条件,直到找到一个违反KKT条件的变量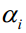 。
。
13.证明SMO算法中子问题是凸优化问题。
两个变量的目标函数的Hessian为
如果是线性核,这个矩阵也可以写成一个矩阵和它的转置的乘积形式
矩阵A为训练样本特征向量乘上类别标签形成的矩阵。显然这个Hessian矩阵是半正定的,因此必定有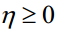 。如果是非线性核,因为核函数相当于对两个核映射之后的向量做内积,因此上面的结论同样成立。
。如果是非线性核,因为核函数相当于对两个核映射之后的向量做内积,因此上面的结论同样成立。
14.证明SMO算法能够收敛。
无论本次迭代时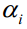 和
和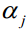 的初始值是多少,通过上面的子问题求解算法得到是在可行域里的最小值,因此每次求解更新这两个变量的值之后,都能保证目标函数值小于或者等于初始值,即函数值下降,所以SMO算法能保证收敛。
的初始值是多少,通过上面的子问题求解算法得到是在可行域里的最小值,因此每次求解更新这两个变量的值之后,都能保证目标函数值小于或者等于初始值,即函数值下降,所以SMO算法能保证收敛。
15.SVM如何解决多分类问题?
对于多分类问题,可以用二分类器的组合来解决,有以下几种方案:
1对剩余方案。对于有k个类的分类问题,训练k个二分类器。训练时第i个分类器的正样本是第i类样本,负样本是除第类之外其他类型的样本,这个分类器的作用是判断样本是否属于第i类。在进行分类时,对于待预测样本,用每个分类器计算输出值,取输出值最大那个作为预测结果。对于3个类的分类问题,这种方案如下图所示
其中黑色样本为待预测样本,三条线分别为此方案的3个分类器。
1对1方案。如果有k个类,训练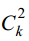 个二分类器,即这些类两两组合。训练时将第i类作为正样本,其他各个类依次作为负样本,总共有
个二分类器,即这些类两两组合。训练时将第i类作为正样本,其他各个类依次作为负样本,总共有
种组合。每个分类器的作用是判断样本是属于第i类还是第j类。对样本进行分类时采用投票的方法,依次用每个二分类器进行预测,如果判定为第m类,则m类的投票数加1,得票最多的那个类作为最终的判定结果。对于3个类的分类问题,这种方案如下图所示
其中黑色样本为待预测样本,三条线分别为此方案的3个分类器。












