今年的第92届奥斯卡可谓是大片云集,入围的影片不仅艺术性极高,而且市场口碑都极佳。当中有黑帮片《爱尔兰人》,经典IP《小妇人》,昆汀的《好莱坞往事》,战争片《1917》,另类超级英雄片《小丑》等等,真正称得上是神仙打架。
可谁也没想到,当中韩国电影《寄生虫》爆冷成为了最大的赢家。
这部由韩国导演奉俊昊自编自导的影片,一举拿下最佳影片、最佳导演、最佳原创剧本和最佳国际电影四座奥斯卡奖杯,创造历史成为奥斯卡史上首部非英语最佳影片。

作为曾经战斗在与韩国争夺端午节到底是谁发明的一线键盘侠,C君一下子吃了一筐柠檬,酸到不行。今天我们就来聊聊韩国的这筐柠檬,不对,这部电影《寄生虫》。

Show me data,用数据说话
今天我们聊聊《寄生虫》
点击下方视频,先睹为快:
说到《寄生虫》横扫本届奥斯卡,你可能会说我们有李安啊,不是也拿奖过吗?要知道作为奥斯卡的宠儿,李安导演在2001年凭借《卧虎藏龙》获得奥斯卡外语片,在2006年和2013年各凭借《断背山》和《少年派的奇幻漂流》收获最佳导演奖,而还未获得最佳影片的殊荣。
这次韩国导演奉俊昊凭借《寄生虫》拿下四座大奖,直接超越了李安导演的记录。
无论我们怎么说,李安拿最佳导演的那两部电影都是属于好莱坞电影,李安甚至都该归为好莱坞的导演,英语说的贼溜。
但反观《寄生虫》,扎扎实实的一部韩国电影,韩国人拍韩国事儿,从导演到演员,从主演到配角,爱喝酒的奉俊昊导演甚至连英语都不会说(颁奖词还得要现场翻译帮忙),而他之前的作品也都是韩国本土的电影。
他自己也在台上发表领奖感言的时候说:“我要感谢昆汀把我的电影放到他的观影表单里面,让全世界更多人知道了我的作品。”
但就是这样一个韩国本土导演,在今年大片云集的情况下拿走份量最重的4个奥斯卡小金人,尤其是历史上首次囊括最佳外语片和最佳电影,也为韩国第一次拿到了奥斯卡,绝对的硬实力。
回顾这几年,韩国电影就像开挂一样,每年都会出爆款。比如警匪片《恶人传》;根据村上春树小说改编的《燃烧》;揭露残酷社会现实的《熔炉》几乎部部口碑炸裂,在口味苛刻的豆瓣上都在7.7分以上。
奉俊昊导演其实在韩国早已家喻户晓,除了《寄生虫》,他的这些作品也都耳熟能详。
2006年的《汉江怪物》(豆瓣7.4分)是当时韩国少见的科幻电影,票房自上映以来整整保持了六年韩国票房冠军之位直至2012年才被《盗贼同盟》赶超。
2013年的《雪国列车》(豆瓣7.4分)该片的故事发生在一个被气候变化毁掉的未来世界,所有的生物都挤在一列环球行驶的火车上。该片首日在韩国上映就刷新了单日最高票房纪录。
而2003年的《杀人回忆》更是在豆瓣评分高达8.8分,是许多影迷的必刷片,也影响了之火许多同类型影片。同时,这部影片改编自真实事件华城连环杀人案,公映时引起了强烈的社会探讨,令人欣慰的是在2019年9月《杀人回忆》的杀手原型也被缉拿归案。
让我们回到《寄生虫》这部影片,荣获这么多大奖,这部电影到底好在哪儿?
《寄生虫》主要讲述的是,住在廉价的半地下室出租房里的一家四口,原本全都是无业游民。在长子基宇隐瞒真实学历,去一户住着豪宅的富有家庭担任家教,之后他更是想方设法把父亲、母亲和妹妹全都弄到这户人家工作,过上了“寄生”一般的生活…
《寄生虫》表面上反映的是韩国社会的真实情景,内核上却展现了所有社会都存在的阶级矛盾这一主题。从剧本设定上,穷人一家混进富人一家寄生于此,然后发现早有另一家寄居篱下,两家穷人为了争夺寄生权你死我活,整个故事从开始的搞笑到最后的惨剧,冲突与转折中充满了黑色幽默。即使是韩语的故事,也能几乎让所有的观影者都产生理解和共鸣,这不是一部电影,这就是一部涵盖了社会道德和人与人关系的文学作品。
当我们在深刻分析,一本正经地写影评的时候,爱喝酒的奉俊昊导演,是这么调侃:
当然这种说法没错,但我认为主要原因是电影开头两个年轻人,拿着手机到处找wifi,全世界的人不都是这样吗?很多观众从开头就找到了共鸣。”
我们爬取了《寄生虫》在豆瓣上的影评数据。整个数据分析的过程分为三步:
以下是具体的步骤和代码实现:
豆瓣从2017.10月开始全面限制爬取数据,非登录状态下最多获取200条,登录状态下最多为500条,本次我们共获取数据521条。
为了解决登录的问题,本次使用Selenium框架发起网页请求,然后使用xpath进行数据的提取。
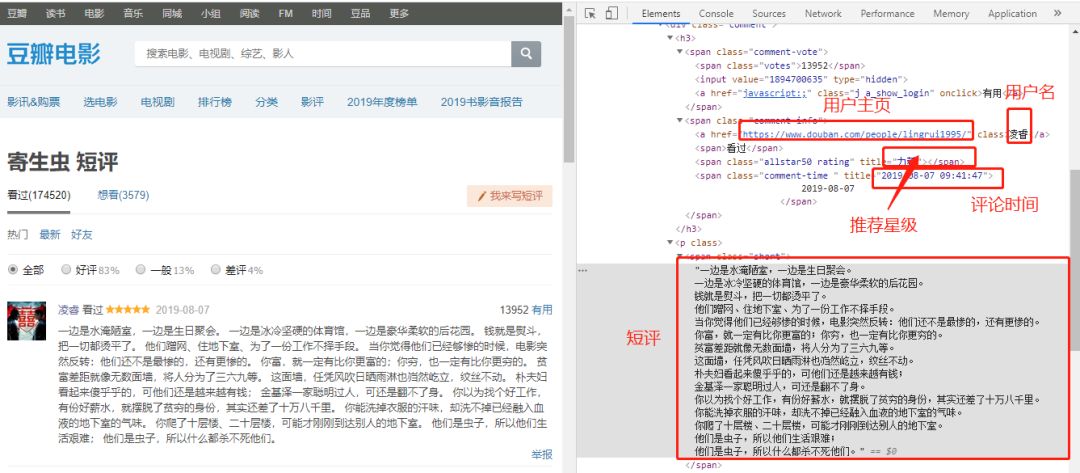
如下图所示,本此数据爬取主要获取的内容有:
评论用户ID
评论用户主页
评论内容
评分星级
评论日期
用户所在城市
代码实现:
import numpy as npimport pandas as pd import timeimport requestsimport re from lxml import etreefrom selenium import webdriverfrom selenium.webdriver.common.by import Byfrom selenium.webdriver.common.keys import Keysfrom selenium.webdriver.chrome.options import Options
def login_douban(): '''功能:自动登录豆瓣网站''' global browser browser = webdriver.Chrome()
login_url = 'https://accounts.douban.com/passport/login?source=movie' browser.get(login_url)
browser.find_element_by_class_name('account-tab-account').click()
username = browser.find_element_by_id('username') username.send_keys('你的用户名') password = browser.find_element_by_id('password') password.send_keys('你的密码')
browser.find_element_by_class_name('btn-account').click()
def get_one_page(url): '''功能:传入url,豆瓣电影一页的短评信息''' browser.get(url)
browser.get(url)
html = etree.HTML(browser.page_source)
user_name = html.xpath('//div/div[2]/h3/span[2]/a/text()') user_url = html.xpath('//div/div[2]/h3/span[2]/a/@href') star = html.xpath('//div/div[2]/h3/span[2]/span[2]/@title') comment_time = html.xpath('//div/div[2]/h3/span[2]/span[3]/@title')
star_dealed = []
for i in range(len(user_name)): if re.compile(r'(\d)').match(star[i]) is not None: star_dealed.append('还行') comment_time.insert(i, star[i]) else: star_dealed.append(star[i])
short_comment = html.xpath('//div/div[2]/p/span/text()') votes = html.xpath('//div/div[2]/h3/span[1]/span/text()')
df = pd.DataFrame({'user_name': user_name, 'user_url': user_url, 'star': star_dealed, 'comment_time': comment_time, 'short_comment': short_comment, 'votes': votes}) return df
def get_25_page(movie_id): '''功能:传入电影ID,获取豆瓣电影25页的短评信息(目前所能获取的最大页数)''' df_all = pd.DataFrame() for i in range(25): url = "https://movie.douban.com/subject/{}/comments?start={}&limit=20&sort=new_score&status=P".format(movie_id,i*20) print('我正在抓取第{}页'.format(i+1), end='\r') df_one = get_one_page(url) df_all = df_all.append(df_one, ignore_index=True) time.sleep(1) return df_all
if __name__ == '__main__': login_douban() time.sleep(2) movie_id = 27010768 df_all = get_25_page(movie_id)
爬取出来的数据以数据框的形式存储,结果如下所示:
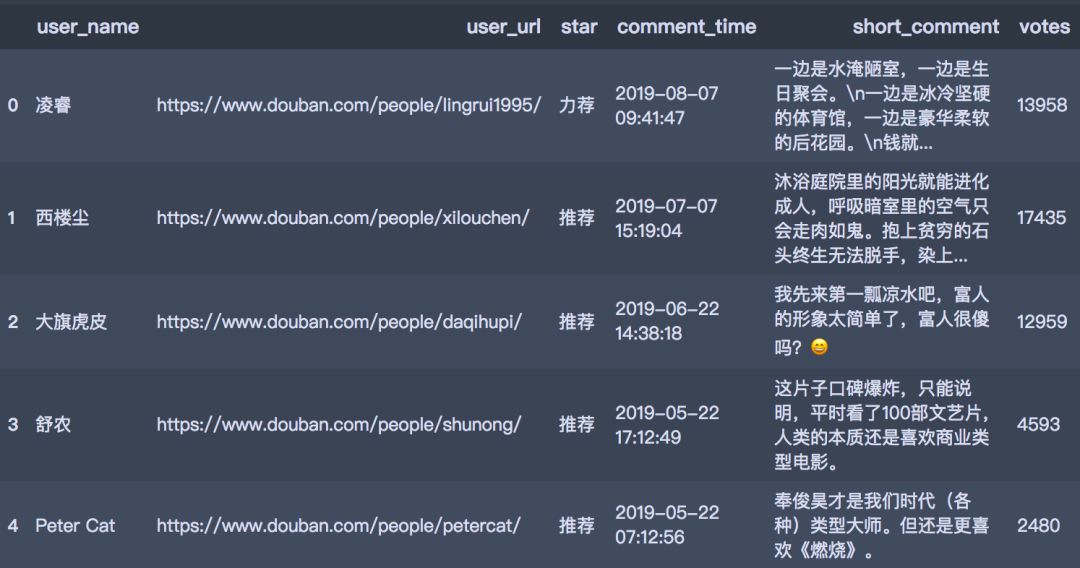
从用户主页的地址可以获取到用户的城市信息,这一步比较简单,此处的代码省略。
对于获取到的数据,我们需要进行以下的处理以方便后续分析:
代码实现:
def transform_star(x): if x == '力荐': return 5 elif x == '推荐': return 4 elif x == '还行': return 3 elif x == '较差': return 2 else: return 1
df_all['star'] = df_all.star.map(lambda x:transform_star(x))
df_all['comment_time'] = pd.to_datetime(df_all.comment_time)
def get_comment_word(df): '''功能:传入df,提取短评信息关键词''' import jieba.analyse import os stop_words = set()
cwd = os.getcwd() stop_words_path = cwd + '\\stop_words.txt'
with open(stop_words_path, 'r', encoding='utf-8') as sw: for line in sw.readlines(): stop_words.add(line.strip())
stop_words.add('6.3') stop_words.add('一张') stop_words.add('这部') stop_words.add('一部') stop_words.add('寄生虫') stop_words.add('一家') stop_words.add('一家人') stop_words.add('电影') stop_words.add('只能') stop_words.add('感觉') stop_words.add('全片') stop_words.add('表达') stop_words.add('真的') stop_words.add('本片') stop_words.add('剧作')
df_comment_all = df['short_comment'].str.cat()
word_num = jieba.analyse.extract_tags(df_comment_all, topK=100, withWeight=True, allowPOS=()) word_num_selected = []
for i in word_num: if i[0] not in stop_words: word_num_selected.append(i)
else: pass
return word_num_selected
key_words = get_comment_word(df_all)key_words = pd.DataFrame(key_words, columns=['words','num'])
用Python做可视化分析的工具很多,目前比较好用可以实现动态可视化的是pyecharts。我们主要对以下几个方面信息进行可视化分析:
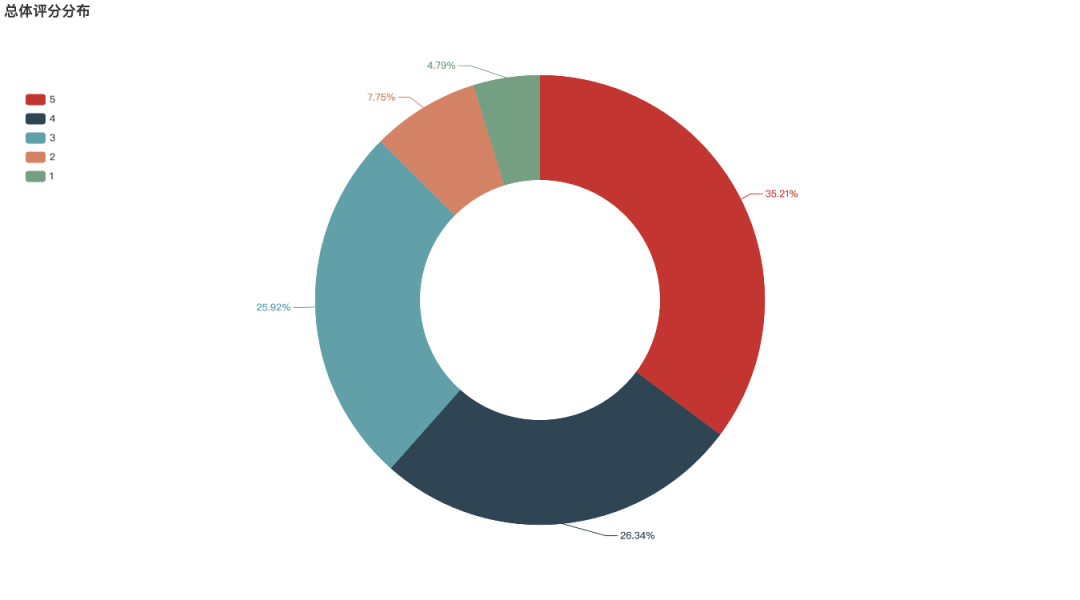
截止到目前为止,《寄生虫》在豆瓣电影上有超过63万人评价,网站上的总体评分为8.7分,这个分数无疑是非常高的。好于97% 喜剧片,好于94% 剧情片。

从评分星级来看,5星的占比最高,占总数的35.21%,4星以上的比重占到50%以上,給到3星以下的比重比较少,仅10%不到。
代码实现:
score_perc = df_all.star.value_counts() / df_all.star.value_counts().sum()score_perc = np.round(score_perc*100,2)
from pyecharts.faker import Fakerfrom pyecharts import options as optsfrom pyecharts.charts import Pie, Page
pie1 = Pie(init_opts=opts.InitOpts(width='1350px', height='750px')) pie1.add("", [*zip(score_perc.index, score_perc.values)], radius=["40%","75%"]) pie1.set_global_opts(title_opts=opts.TitleOpts(title='总体评分分布'), legend_opts=opts.LegendOpts(orient="vertical", pos_top="15%", pos_left="2%"), toolbox_opts=opts.ToolboxOpts()) pie1.set_series_opts(label_opts=opts.LabelOpts(formatter="{c}%")) pie1.render('总体评分分布.html')
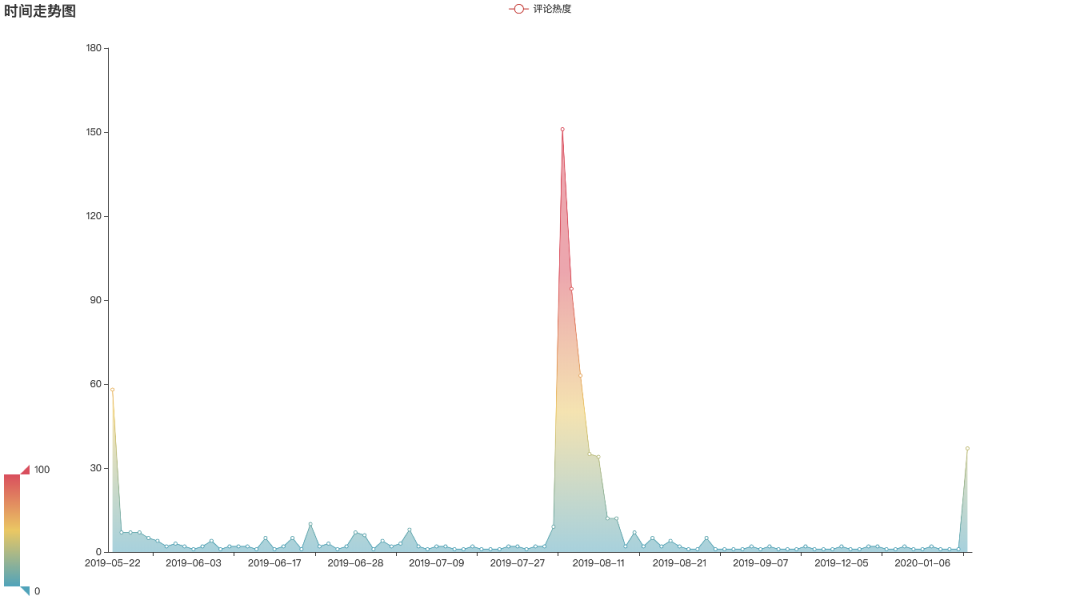
评论的热度在2019年8月份最高。可能是出网上资源的时候吧...
代码实现:
time = df_all.comment_date.value_counts() time.sort_index(inplace=True)
from pyecharts.charts import Line
line1 = Line(init_opts=opts.InitOpts(width='1350px', height='750px'))line1.add_xaxis(time.index.tolist())line1.add_yaxis('评论热度', time.values.tolist(), areastyle_opts=opts.AreaStyleOpts(opacity=0.5), label_opts=opts.LabelOpts(is_show=False))line1.set_global_opts(title_opts=opts.TitleOpts(title="时间走势图"), toolbox_opts=opts.ToolboxOpts(), visualmap_opts=opts.VisualMapOpts()) line1.render('评论时间走势图.html')
从观影评价城市来看,北京占到绝大多数,其次是上海。这跟微博统计的数据基本一致。
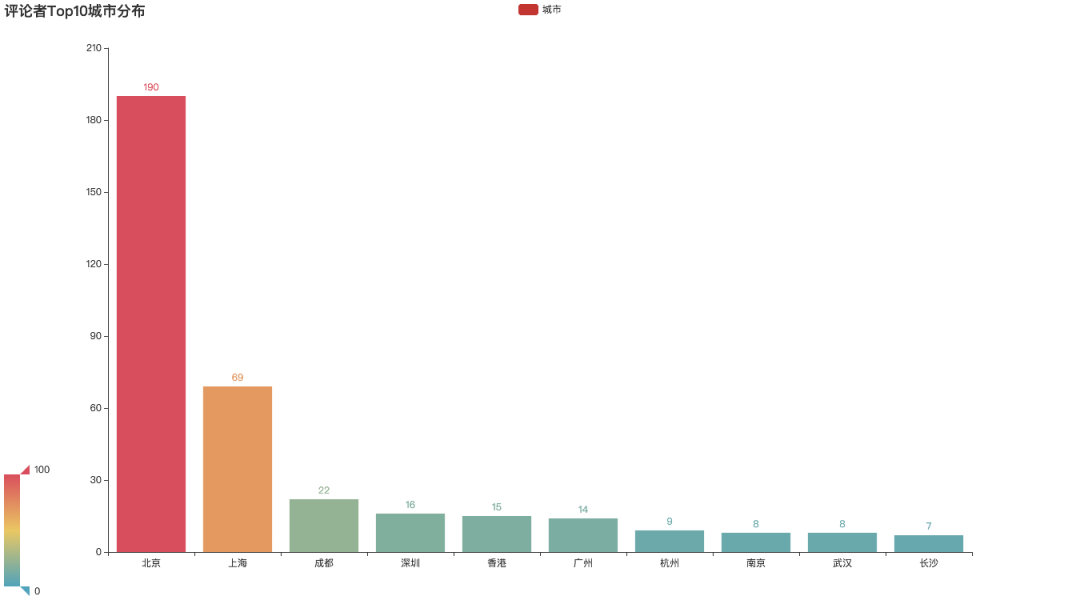
代码实现:
city_top10 = df_all.city_dealed.value_counts()[:12] city_top10.drop('国外', inplace=True)city_top10.drop('未知', inplace=True)
from pyecharts.charts import Bar
bar1 = Bar(init_opts=opts.InitOpts(width='1350px', height='750px')) bar1.add_xaxis(city_top10.index.tolist())bar1.add_yaxis("城市", city_top10.values.tolist()) bar1.set_global_opts(title_opts=opts.TitleOpts(title="评论者Top10城市分布"), toolbox_opts=opts.ToolboxOpts(), visualmap_opts=opts.VisualMapOpts()) bar1.render('评论者Top10城市分布条形图.html')
代码实现:
from pyecharts.charts import WordCloudfrom pyecharts.globals import SymbolType, ThemeType
word = WordCloud(init_opts=opts.InitOpts(width='1350px', height='750px'))word.add("", [*zip(key_words.words, key_words.num)], word_size_range=[20, 200], shape='diamond') word.set_global_opts(title_opts=opts.TitleOpts(title="寄生虫电影评论词云图"), toolbox_opts=opts.ToolboxOpts()) word.render('寄生虫电影评论词云图.html')
从电影短评的分词来看,主要集中对“奉俊昊”导演的探讨上。毕竟在此之前,让大家说出一个韩国导演的名字,大家还是有点摸不着头脑的,就知道杀人回忆、汉江怪物挺好看。
其次关于“穷人”“富人”“阶级”等影片故事内核的关注度也很高。
这里面就有一句大家最常提及的台词,引人深思:不是“有钱却很善良”,是“有钱所以善良”,懂吗?如果我有这些钱的话,我也会很善良,超级善良。
与此同时针对影片的剧情“反转”,“镜头”等拍摄手法也是观众的焦点。
很有意思的是,看本片时观众还会跟《燃烧》等韩国电影进行比较。
这里也推荐大家可以去看看《燃烧》,也是非常不错的一部作品。
最后,被柠檬酸到不行的我们,可以继续当个键盘侠去羡慕一下韩国的电影审查制度。但最根本的还是年轻的键盘侠们真正长大到要去拍电影、审查电影的时候,能不能真正如自己所说的那般带来改变。当然也可以学学中国足球,我们是不是可以归化一个韩国导演?
如果对这一期的数据感兴趣,可以访问data.cda.cn下载,自己分析了试试。
最后附上本届奥斯卡的完整获奖名单~











