
来源:授权自AI科技大本营(ID:rgznai100)
本文约4900字,建议阅读10分钟。
本文我们将探讨不同的机器学习模型,以及每个模型合理的使用场景。
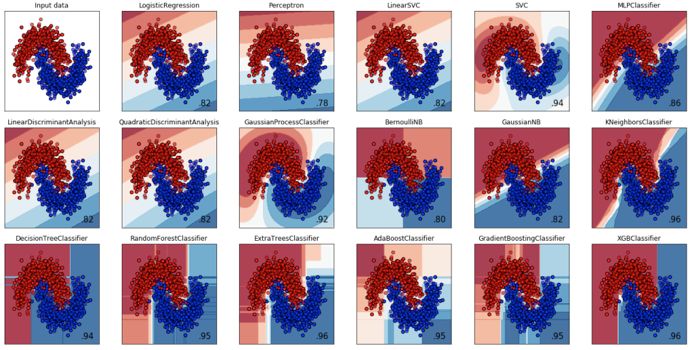
[ 导读 ] 一般来说,基于树形结构的模型在Kaggle竞赛中是表现最好的,而其它的模型可以用于融合模型。对于计算机视觉领域的挑战,CNNs (Convolutional Neural Network, 卷积神经网络)是最适合不过的。而对于NLP(Natural Language Processing,自然语言处理),LSTMs或GRUs是最好的选择。下面是一个不完全模型细目清单,同时列出了每个模型的一些优缺点。
A. 线性回归(Linear Regression)
善于获取数据集中的线性关系;
- 适用于在已有了一些预先定义好的变量并且需要一个简单的预测模型的情况下使用;
- 不需要进行参数调整(下面的正则化线性模型需要调整正则化参数);
- 不需要特征缩放(下面的正则化线性模型需要特征缩放);
- 如果数据集具有冗余的特征,那么线性回归可能是不稳定的;
这些模型是正则化的线性回归模型;
有助于防止过度拟合;
这些模型更善于正则化,因为它们更简单;
适用于当我们只关心几个特征的时候;
训练速度和预测速度较快;
善于获取数据集中的非线性关系;
了解数据集中的特征交互;
善于处理数据集中出现的异常值;
善于在数据集中找到最重要的特征;
不需要特征缩放;
结果可解释,并易于说明;
预测精确度较低;
需要一些参数的调整;
不适用于小型数据集;
分离信号和噪声的效果不理想;
当新增数据时,不易更新模型;
在实践中很少使用,而是更多地使用集合树;
可能会出现过度拟合(见下面的融合模型);
- II.融合模型(RandomForest,XGBoost, CatBoost, LightGBM)
多重树结构整理预测;
具有较高的预测精确度,在实践中表现很好;
是Kaggle竞赛中推荐的算法;
善于处理数据集中出现的异常值;
善于在数据集中获取非线性关系;
善于在数据集中找到最重要的特征;
能够分离信号和噪声;
不需要特征缩放;
特别适用于高维度的数据;
训练速度较慢;
具有较高的预测速度;
结果不易解释或说明;
当新增数据时,不易更新模型;
需要调整参数,但调整较为复杂;
不适用于小型数据集;
D. 基于距离的K近邻算法(K Nearest Neighbors – Distance Based)
训练速度较快;
不需要太多的参数调整;
结果可解释,并易于说明;
适用于小型数据集(小于10万个训练集)
A. 逻辑回归算法(Logistic Regression)
B. 基于距离的支持向量机算法(Support Vector Machines – Distance based)当新增数据时,不易更新模型;
属于内存高度密集型算法;
不适用于大型数据集;
需要选择正确的内核;
线性内核对线性数据建模,运行速度快;
非线性内核可以模拟非线性边界,运行速度慢;
用Boosting代替!
C. 基于概率的朴素贝叶斯算法(Naive Bayes — Probability based)
D. 基于距离的K近邻算法( K Nearest Neighbors — Distance Based)具有较高的训练速度;
无需太多参数调整;
结果可解释,并易于说明;
适用于小型数据集(小于10万个训练集);
E. 分类树(Classification Tree)
具有较高的训练速度和预测速度;
善于获取数据集中的非线性关系;
了解数据集中的特征交互;
善于处理数据集中出现的异常值;
善于在数据集中找到最重要的特征;
可以同时进行2个类和多个类的分类任务;
不需要特征缩放;
结果可解释,并易于说明;
预测速度较慢;
需要进行参数的调整;
在小型数据集上表现不好;
分离信号和噪声的效果不理想;
在实践中很少使用,而是更多地使用集合树;
当新增数据时,不易更新模型;
- II.融合(RandomForest, XGBoost, CatBoost, LightGBM)
多重树结构整理预测;
具有较高的预测精确度,在实践中表现很好;
是Kaggle竞赛中推荐的算法;
善于获取数据集中的非线性关系;
善于处理数据集中出现的异常值;
善于在数据集中找到最重要的特征;
能够分离信号和噪声;
无需特征缩放;
特别适用于高维度的数据;
训练速度较慢;
预测速度较快;
结果不易解释或说明;
当新增数据时,不易更新模型;
需要调整参数,但调整较为复杂;
在小型数据集上表现不好;
A. DBSCAN聚类算法(Density-Based Spatial Clustering of Applications with Noise)
特别适于获取底层数据集的结构;
算法简单,易于解释;
适于预先知道聚类的数量;
- 降维算法(Dimensionality Reduction Algorithms);
聚类算法(Clustering algorithms);
高斯混合模型(Gaussian Mixture Model);
分层聚类(Hierarchical clustering);
- 强化学习(Reinforcement Learning)
融合模型是一种非常强大的技术,有助于减少过度拟合,并通过组合来自不同模型的输出以做出更稳定的预测。融合模型是赢得Kaggle竞赛的一个重要工具,在选择模型进行融合时,我们希望选择不同类型的模型,以确保它们具有不同的优势和劣势,从而在数据集中获取不同的模式。这种更明显的多样性特点使得偏差降低。我们还希望确保它们的性能是可以对比的,这样就能确保预测的稳定性。我们在这里可以看到,这些模型的融合实际上比任何单一的模型生成的损失都要低得多。部分的原因是,尽管所有的这些模型都非常擅长预测,但它们都能得到不同的正确预测结果,通过把它们组合在一起,我们能够根据它们所有不同的优势组合成一个超级模型。# in order to make the final predictions more robust to overfittingdef blended_predictions(X): return ((0.1 * ridge_model_full_data.predict(X)) + \\ (0.2 * svr_model_full_data.predict(X)) + \\ (0.1 * gbr_model_full_data.predict(X)) + \\ (0.1 * xgb_model_full_data.predict(X)) + \\ (0.1 * lgb_model_full_data.predict(X)) + \\ (0.05 * rf_model_full_data.predict(X)) + \\ (0.35 * stack_gen_model.predict(np.array(X))))
- Bagging:使用随机选择的不同数据子集训练多个基础模型,并进行替换。让基础模型对最终的预测进行投票。常用于随机森林算法(RandomForests);
- Boosting:迭代地训练模型,并且在每次迭代之后更新获得每个训练示例的重要程度。常用于梯度增强算法(GradientBoosting);
- Blending:训练许多不同类型的基础模型,并在一个holdout set上进行预测。从它们的预测结果中再训练一个新的模型,并在测试集上进行预测(用一个holdout set堆叠);
- Stacking:训练多种不同类型的基础模型,并对数据集的k-folds进行预测。从它们的预测结果中再训练一个新的模型,并在测试集上进行预测;
权重和偏差让我们可以用一行代码来跟踪和比较模型的性能表现。选择要测试的模型后,对其进行训练并添加wandb.log({‘score’: cv_score})来记录模型的运行状态。完成训练之后,你就可以在一个简单的控制台中对比模型的性能了!
import wandbimport tensorflow.kerasfrom wandb.keras import WandbCallbackfrom sklearn.model_selection import cross_val_scorefrom sklearn import svmfrom sklearn.linear_model import Ridge, RidgeCVfrom xgboost import XGBRegressor
wandb.init(anonymous='allow', project="pick-a-model")
clf = svm.SVR(C= 20, epsilon= 0.008, gamma=0.0003)
cv_scores = cross_val_score(clf, X_train, train_labels, cv=5)
for cv_score in cv_scores: wandb.log({'score': cv_score})
wandb.init(anonymous='allow', project="pick-a-model")
clf = XGBRegressor(learning_rate=0.01, n_estimators=6000, max_depth=4, min_child_weight=0, gamma=0.6, subsample=0.7, colsample_bytree=0.7, objective='reg:linear', nthread=-1, scale_pos_weight=1, seed=27, reg_alpha=0.00006, random_state=42)
cv_scores = cross_val_score(clf, X_train, train_labels, cv=5)
for cv_score in cv_scores: wandb.log({'score': cv_score})
wandb.init(anonymous='allow', project="pick-a-model")
ridge_alphas = [1e-15, 1e-10, 1e-8, 9e-4, 7e-4, 5e-4, 3e-4, 1e-4, 1e-3, 5e-2, 1e-2, 0.1, 0.3, 1, 3, 5, 10, 15, 18, 20, 30, 50, 75, 100]clf = Ridge(alphas=ridge_alphas)
cv_scores = cross_val_score(clf, X_train, train_labels, cv=5)
for cv_score in cv_scores: wandb.log({'score': cv_score})
就这样,在有了所有的工具和算法之后,就可以为你的问题选择正确的模型了!模型的选择可能是非常复杂的,但我希望本指南能给你带来一些启发,让你找到模型选择的好方法。原文链接:
https://lavanya.ai/2019/09/18/part-ii-whirlwind-tour-of-machine-learning-models/
编辑:于腾凯
校对:林亦霖







