原作:Kasper Fredenslund
林鳞 编译自 Data Science Central
量子位 出品 | 公众号 QbitAI
分类器是数据挖掘中对样本进行分类的方法的统称,也是入坑机器学习的一项必备技能。这篇文章中,作者简要介绍了用Python中的机器学习工具scikit-learn(sklearn)创建机器学习分类器的步骤与注意事项。
读完这篇文章,你将学到:
导入和转换.csv文件,开启sklearn之旅
检查数据集并选择相关特征
用sklearn训练不同的数据分类器
分析结果,进一步改造模型
第一步:导入数据
找到合适的数据下载完成后,我们不难猜到,要做的第一件事肯定是加载并且检查数据的结构。这里我推荐大家使用Pandas。

Pandas是一个Python库,里面包含一个叫DataFrame的数据处理界面。DataFrame本质上是一个具有行和列的excel表格,UI也相对做得朴素简洁。不同的是,我们需要也编程的方式进行所有数据操作。
除了excel表格外,Pandas还支持其他不同的格式,比如csv文件和HTML文件等。
第二步:选择特征
假设你想从一系列特征中预测一套房子的价格,我们应该选择哪些特征?
房子中灯和插座的数量重要吗?不重要。几乎没有买房者会将房子和插座的数量作为首要考虑因素。所以在这种情况下,这个特征就是不那么相关的特征。
在机器学习中,添加过多特征但不包含重要信息会导致模型不必要地变慢,并且会增加模型过度拟合的风险。
一般来说,你需要用尽可能少的特征,提供尽可能多的信息。
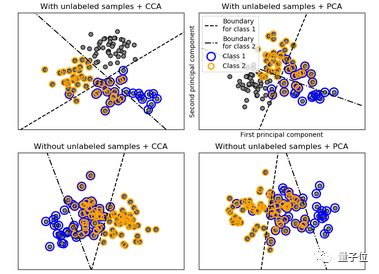
或者,我们还可以将相关特性(如房间数量、居住面积和窗户数量)与上面的示例合并成更高级别的主成分,再使用主成分分析(PCA)等技术分析。
通过绘图可视化这些特征之间的关系也是决定特征相关性的实用方法。下面,我们将使用plot.scatter()子方法绘制这个关系坐标轴。
第三步:准备训练数据
选择了想要用到的特征(PetalLengthCm和PetalWidthCm)后,还需要对它们进行一些处理。
一般来说,很多数据都是在Pandas中的DataFrame中编码的,但DataFrames并不适用于sklearn,所以我们需要提取特征和标签并将它们转换成numpy数组。
分割这些标签很简单,可以在一行中使用np.asarray()。
第四步:选择分类器
我建议在一开始大家都选择随机森林分类器。随机森林简单灵活,它能处理很多类型的数据,也不容易过拟合,所以我认为选择随机森林是个好起点。
不过,随机森林的一个明显缺点是它具有不确定性。因此每次训练时,都能得到不同的结果。
虽然随机森林是个好起点,但在实际操作中,我们经常会用多种分类器的组合看看能得到哪些好结果。
孰能生巧,渐渐地你会了解哪种算法适合哪些问题,对数学表达式做个原理剖析也能帮助你解决这个问题。
第五步:训练分类器
选择了分类器后,我们要去准备实现它了。
用sklearn实现分类器通常分三步走:导入、初始化和训练。
第六步:结果评估
即使分类的准确率可能高达98%,那么仍有2%情况会导致分类器犯错。那么,分类器到底是如何犯错的?
分类器的错误有两种,即假阳性和假阴性。假阳性指的是当某些东西为假时被认为是真的,假阴性相反。在机器学习中,我们经常用准确率(precision)和召回率(recall)评定精度。
这两个值均为小数或分数,在0和1之间,越高越好。
第七步:调整分类器
目前,我们的随机森林分类器只能使用默认的参数值。为了更好使用,我们可以改变了一些甚至所有的值。
min_samples_split是个有趣的参数。这个参数表示分割决策树的最小样本。
一般来说,模型捕捉的细节越少,过拟合的风险就越大。然而当将这个参数设置的过高时,你要注意在忽略细节的同时如何更好地记录趋势。
想用sklearn创建机器学习分类器?看完这篇文章后是不是有了更多的了解?如果想更详细地了解文章中每一步的具体操作,可以查看作者博客中的原文:
https://kasperfred.com/posts/creating-your-first-machine-learning-classification-model-in-sklearn
量子位AI社群13群开始招募啦,欢迎对AI感兴趣的同学,加小助手微信qbitbot5入群;
此外,量子位专业细分群(自动驾驶、CV、NLP、机器学习等)正在招募,面向正在从事相关领域的工程师及研究人员。
进群请加小助手微信号qbitbot5,并务必备注相应群的关键词~通过审核后我们将邀请进群。(专业群审核较严,敬请谅解)
量子位正在招募编辑/记者,工作地点在北京中关村。期待有才气、有热情的同学加入我们!相关细节,请在量子位公众号(QbitAI)对话界面,回复“招聘”两个字。











