
作者:沂水寒城,CSDN博客专家,个人研究方向:机器学习、深度学习、NLP、CV
Blog: http://yishuihancheng.blog.csdn.net
词云是一种非常漂亮的可视化展示方式,正所谓一图胜过千言万语,词云在之前的项目中我也有过很多的使用,可能对于我来说,一种很好的自我介绍方式就是词云吧,就像下面这样的:

个人觉还是会比枯燥的文字语言描述性的介绍会更吸引人一点吧。
今天不是说要怎么用词云来做个人介绍,而是对工作中使用到比较多的词云计较做了一下总结,主要是包括三个方面:
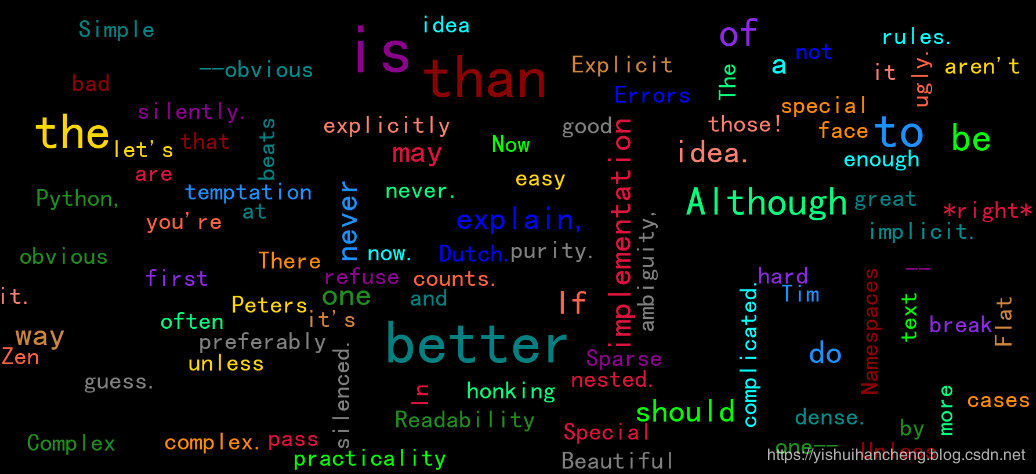
1、诸如上面的简单形式矩形词云
2、基于背景图片数据来构建词云数据
3、某些场景下不想使用类似上面的默认的字体颜色,这里可以自定义词云的字体颜色
接下来对上面三种类型的词云可视化方法进行demo实现与展示,具体如下,这里我们使用到的测试数据如下:
The Zen of Python, by Tim Peters
Beautiful is better than ugly.
Explicit is better than implicit.
Simple is better than complex.
Complex is better than complicated.
Flat is better than nested.
Sparse is
better than dense.
Readability counts.
Special cases aren't special enough to break the rules.
Although practicality beats purity.
Errors should never pass silently.
Unless explicitly silenced.
In the face of ambiguity, refuse the temptation to guess.
There should be one-- and preferably text one --obvious way to do it.
Although that way may not be obvious at first unless you're Dutch.
Now is better than never.
Although never is often better than *right* now.
If the implementation is hard to explain, it's a bad idea.
If the implementation is easy to explain, it may be a good idea.
Namespaces are one honking great idea -- let's do more of those!
1、简单形式矩形词云实现如下:
def simpleWC1(sep=' ',back='black',freDictpath='data_fre.json',savepath='res.png'):
'''
词云可视化Demo
'''
try:
with open(freDictpath) as f:
data=f.readlines()
data_list=[one.strip().split(sep) for one in data if one]
fre_dict={}
for one_list in data_list:
fre_dict[unicode(one_list[0])]=int(one_list[1])
except:
fre_dict=freDictpath
wc=WordCloud(font_path='font/simhei.ttf',#设置字体 #simhei
background_color=back, #背景颜色
max_words=1300,# 词云显示的最大词数
max_font_size=120, #字体最大值
margin=3, #词云图边距
width=1800, #词云图宽度
height=800, #词云图高度
random_state=42)
wc.generate_from_frequencies(fre_dict) #从词频字典生成词云
plt.figure()
plt.imshow(wc)
plt.axis("off")
wc.to_file(savepath)
图像数据结果如下:

2、 基于背景图像数据的词云可视化具体实现如下:
先贴一下背景图像:

这也是一个比较经典的图像数据了,下面来看具体的实现:
def simpleWC2(sep=' ',back='black',backPic='a.png',freDictpath='data_fre.json',savepath='res.png'):
'''
词云可视化Demo【使用背景图片】
'''
try:
with open(freDictpath) as f:
data=f.readlines()
data_list=[one.strip().split(sep) for one in data if one]
fre_dict={}
for one_list in data_list:
fre_dict[unicode(one_list[0])]=int(one_list[1])
except:
fre_dict=freDictpath
back_coloring=imread(backPic)
wc=WordCloud(font_path='simhei.ttf',#设置字体 #simhei
background_color=back,max_words=1300,
mask=back_coloring,#设置背景图片
max_font_size=120, #字体最大值
margin=3,width=1800,height=800,random_state=42,)
wc.generate_from_frequencies(fre_dict) #从词频字典生成词云
wc.to_file(savepath)
结果图像数据如下:

3、 自定义词云字体颜色的具体实现如下:
#自定义颜色列表
color_list=['#CD853F','#DC143C','#00FF7F','#FF6347','#8B008B','#00FFFF','#0000FF','#8B0000','#FF8C00',
'#1E90FF','#00FF00','#FFD700','#008080','#008B8B','#8A2BE2','#228B22','#FA8072','#808080']
def simpleWC3(sep=' ',back='black',freDictpath='data_fre.json',savepath='res.png'):
'''
词云可视化Demo【自定义字体的颜色】
'''
#基于自定义颜色表构建colormap对象
colormap=colors.ListedColormap(color_list)
try:
with open(freDictpath) as f:
data=f.readlines()
data_list=[one.strip().split(sep) for one in data if one]
fre_dict={}
for one_list in data_list:
fre_dict[unicode(one_list[0])]=int(one_list[1])
except:
fre_dict=freDictpath
wc=WordCloud(font_path='font/simhei.ttf',#设置字体 #simhei
background_color=back, #背景颜色
max_words=1300, #词云显示的最大词数
max_font_size=120, #字体最大值
colormap=colormap, #自定义构建colormap对象
margin=2,width=1800,height=800,random_state=42,
prefer_horizontal=0.5) #无法水平放置就垂直放置
wc.generate_from_frequencies(fre_dict)
plt.figure()
plt.imshow(wc)
plt.axis("off")
wc.to_file(savepath)
结果图像数据如下:
上述三种方法就是我在具体工作中使用频度最高的三种词云可视化展示方法了,下面贴出来完整的代码实现,可以直接拿去跑的:
#!usr/bin/env python
#encoding:utf-8
from __future__ import division
'''
__Author__:沂水寒城
功能: 词云的可视化模块
'''
import os
import sys
import json
import numpy as np
from PIL import Image
from scipy.misc import imread
from matplotlib import colors
import matplotlib.pyplot as plt
from matplotlib.font_manager import FontProperties
from wordcloud import WordCloud,ImageColorGenerator,STOPWORDS
reload(sys)
sys.setdefaultencoding('utf-8')
#自定义颜色列表
color_list=['#CD853F','#DC143C','#00FF7F','#FF6347','#8B008B','#00FFFF','#0000FF','#8B0000','#FF8C00',
'#1E90FF',
'#00FF00','#FFD700','#008080','#008B8B','#8A2BE2','#228B22','#FA8072','#808080']
def simpleWC1(sep=' ',back='black',freDictpath='data_fre.json',savepath='res.png'):
'''
词云可视化Demo
'''
try:
with open(freDictpath) as f:
data=f.readlines()
data_list=[one.strip().split(sep) for one in data if one]
fre_dict={}
for one_list in data_list:
fre_dict[unicode(one_list[0])]=int(one_list[1])
except:
fre_dict=freDictpath
wc=WordCloud(font_path='font/simhei.ttf',#设置字体 #simhei
background_color=back, #背景颜色
max_words=1300,# 词云显示的最大词数
max_font_size=120, #字体最大值
margin=3, #词云图边距
width=1800, #词云图宽度
height=800, #词云图高度
random_state=42)
wc.generate_from_frequencies(fre_dict) #从词频字典生成词云
plt.figure()
plt.imshow(wc)
plt.axis("off")
wc.to_file(savepath)
def simpleWC2(sep=' ',back='black',backPic='a.png',freDictpath='data_fre.json',savepath='res.png'):
'''
词云可视化Demo【使用背景图片】
'''
try:
with open(freDictpath) as f:
data=f.readlines()
data_list=[one.strip().split(sep) for one in data if one]
fre_dict={}
for one_list in data_list:
fre_dict[unicode(one_list[0])]=int(one_list[1])
except:
fre_dict=freDictpath
back_coloring=imread(backPic)
wc=WordCloud(font_path='simhei.ttf'
,#设置字体 #simhei
background_color=back,max_words=1300,
mask=back_coloring,#设置背景图片
max_font_size=120, #字体最大值
margin=3,width=1800,height=800,random_state=42,)
wc.generate_from_frequencies(fre_dict) #从词频字典生成词云
wc.to_file(savepath)
def simpleWC3(sep=' ',back='black',freDictpath='data_fre.json',savepath='res.png'):
'''
词云可视化Demo【自定义字体的颜色】
'''
#基于自定义颜色表构建colormap对象
colormap=colors.ListedColormap(color_list)
try:
with open(freDictpath) as f:
data=f.readlines()
data_list=[one.strip().split(sep) for one in data if one]
fre_dict={}
for one_list in data_list:
fre_dict[unicode(one_list[0])]=int(one_list[1])
except:
fre_dict=freDictpath
wc=WordCloud(font_path='font/simhei.ttf',#设置字体 #simhei
background_color=back, #背景颜色
max_words=1300, #词云显示的最大词数
max_font_size=120, #字体最大值
colormap=colormap, #自定义构建colormap对象
margin=2,width=1800,height=800,random_state=42,
prefer_horizontal=0.5) #无法水平放置就垂直放置
wc.generate_from_frequencies(fre_dict)
plt.figure()
plt.imshow(wc)
plt.axis("off")
wc.to_file(savepath)
if __name__ == '__main__':
text="""
The Zen of Python, by Tim Peters
Beautiful is better than ugly.
Explicit is better than implicit.
Simple is better than complex.
Complex is better than complicated.
Flat is better than nested.
Sparse is better than dense.
Readability counts.
Special cases aren't special enough to break the rules.
Although practicality beats purity.
Errors should never pass silently.
Unless explicitly silenced.
In the face of ambiguity, refuse the temptation to guess.
There should be one-- and preferably text one --obvious way to do it.
Although that way may not be obvious at first unless you're Dutch.
Now is better than never.
Although never is often better than *right* now.
If the implementation is hard to explain, it's a bad idea.
If the implementation is easy to explain, it may be a good idea.
Namespaces are one honking great idea -- let's do more of those!
"""
word_list=text.split()
fre_dict={}
for one in word_list:
if one in fre_dict:
fre_dict[one]+=1
else:
fre_dict[one]=1
simpleWC1(sep=' ',back='black',freDictpath=fre_dict,savepath='simpleWC1.png')
simpleWC2(sep=' ',back='black',backPic='backPic/A.png',freDictpath=fre_dict,savepath='simpleWC2.png')
simpleWC3(sep=' ',back='black',freDictpath=fre_dict,savepath='simpleWC3.png')
赞 赏 作 者

Python中文社区作为一个去中心化的全球技术社区,以成为全球20万Python中文开发者的精神部落为愿景,目前覆盖各大主流媒体和协作平台,与阿里、腾讯、百度、微软、亚马逊、开源中国、CSDN等业界知名公司和技术社区建立了广泛的联系,拥有来自十多个国家和地区数万名登记会员,会员来自以工信部、清华大学、北京大学、北京邮电大学、中国人民银行、中科院、中金、华为、BAT、谷歌、微软等为代表的政府机关、科研单位、金融机构以及海内外知名公司,全平台近20万开发者关注。
 ▼
投稿请点击阅读原文 喜欢文章,点个在看
▼
投稿请点击阅读原文 喜欢文章,点个在看









