作者:Mathieu Carrière 翻译:孙韬淳 校对:和中华本文简要介绍了机器学习中拓扑数据分析的力量并展示如何配合三个Python库:Gudhi,Scikit-Learn和Tensorflow进行实践。Hi大家好。今天,我想强调下在机器学习中拓扑数据分析(TDA,Topological Data Analysis)的力量,并展示如何配合三个Python库:Gudhi,Scikit-Learn和Tensorflow进行实践。
首先,让我们谈谈TDA。它是数据科学中相对小众的一个领域,尤其是当与机器学习和深度学习对比的时候。但是它正迅速成长,并引起了数据科学家的注意。很多初创企业和公司正积极把这些技术整合进它们的工具箱中(比如IBM,Fujitsu,Ayasdi),原因则是近年来它在多种应用领域的成功,包括生物学、时间序列、金融、科学可视化、计算机图形学等。未来我可能会写一个关于TDA一般用途和最佳实践的帖子,所以请大家等待下。TDA:
https://en.wikipedia.org/wiki/Topological_data_analysis
IBM:
https://researcher.watson.ibm.com/researcher/view_group.php?id=6585
Fujitsu:
https://www.fujitsu.com/global/about/resources/news/press-releases/2016/0216-01.html
Ayasdi:
https://www.ayasdi.com/platform/technology/
生物学:
https://www.ncbi.nlm.nih.gov/pubmed/28459448
时间序列:
https://www.ams.org/journals/notices/201905/rnoti-p686.pdf
金融:
https://papers.ssrn.com/sol3/papers.cfm?abstract_id=2931836
科学可视化:
https://topology-tool-kit.github.io/
计算机图形学:
http://www.lix.polytechnique.fr/~maks/papers/top_opt_SGP18.pdf
TDA的目标是对你数据的拓扑性质进行计算和编码,这意味着记录数据集中多样的连接成分,环,腔和高维结构。这非常有用,主要是因为其他描述符不可能计算这类信息。所以TDA真的储存了一组你不可能在其他地方找到的数据特征。现实情况是这类特征已被证明对提升机器学习预测能力很有用,所以如果你以前还没见过或听过这类特征,我来带你快速了解一下。
我已经写过很多这个主题的文章,你可以在Medium找到关于TDA的很多其他帖子,所以我不打算浪费时间在数学定义上面,而是通过解释TDA文献中的典型例子,来展示如何在你的数据集上应用TDA。https://towardsdatascience.com/mixing-topology-and-deep-learning-with-perslay-2e60af69c321https://towardsdatascience.com/applied-topological-data-analysis-to-deep-learning-hands-on-arrhythmia-classification-48993d78f9e6
TDA的参考示例:点云分类
这个数据集在一篇开创性的TDA文章上介绍过。它由通过下述动力系统生成的轨迹来得到的点云集组成:
http://jmlr.org/papers/v18/16-337.html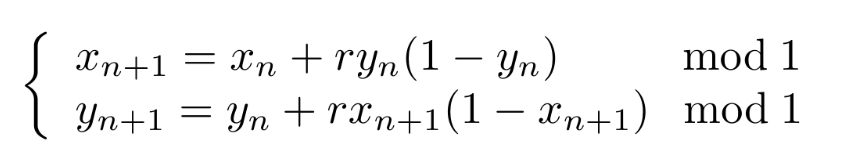
这意味着我们将从一个单位正方形内随机抽取一个初始点,并通过上面的方程生成一个点的序列。这将给我们一个点云。现在我们可以根据意愿重复这个操作,得到一堆点云。这些点云的一个有趣的属性在于,根据你用来生成点序列的r参数的值,点云会有非常不一样且有意思的结构。比如,如果r=3.5,得到的点云似乎覆盖了整个单位正方形,但如果r=4.1,单位正方形的一些区域就是空的:换句话说,在你的点云里有好多洞。这对我们是个好消息:TDA可以直接计算这些结构是否能出现。
r=3.5(左)和r=4.1(右)计算出的点云。相当明显的是后者有个洞,但前者没有TDA跟踪这些洞的方式实际上相当简单。想象给定半径为R的每个球的圆心都在你点云的每个点上。如果R=0,这些球的并集就是点云本身。如果R为无穷,那么球的并集是整个单位正方形。但如果R被很精心的选择,球的并集可能存在很多拓扑结构,比如,洞。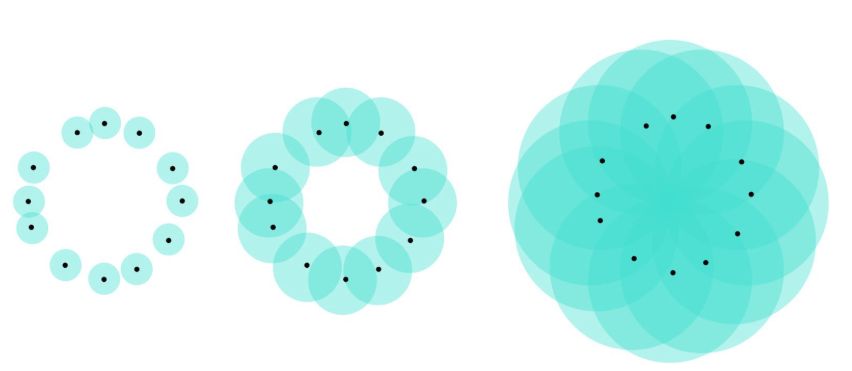
球并集的例子。对于中间图的并集,它清晰的组成了一个洞。整张图片被我“不要脸”地借用自我之前的一个帖子
https://towardsdatascience.com/a-concrete-application-of-topological-data-analysis-86b89aa27586那么,为了避免人工选择R的“好值”,TDA将针对每一个可能的R值(从0到无穷)计算球的并集,并记录每个洞出现或者消失时的半径,并对一些点使用这些半径值作为二维坐标。TDA的输出则是另一个点云,其中每个点代表一个洞:这叫做Rips持续图(Rips persistence diagram)。假设点云在一个numpy数组X中储存(shape为N*2),通过Gudhi,这个图可以用两行代码计算出来:import gudhirips = gudhi.RipsComplex(points=X).create_simplex_tree()
dgm = rips.persistence()
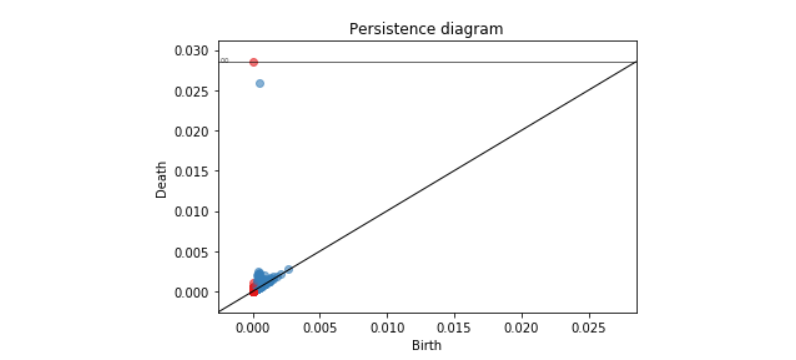
这个漂亮的持续图由r=4.1对应的点云计算出。红色的点代表相连的成分,蓝色的点代表洞
接下来我们将解决的任务则是给定点云预测r的值。
通过Gudhi+Scikit-Learn进行拓扑机器学习持续图很简洁,是不是?它们存在的问题则是,从不同点云计算出的持续图可能有不同数量的点(因为点云可能有不同数量的洞)。所以如果你想用Scikit-Learn从持续图中预测r,不幸的是,没有直接的方法,因为这些库预期输入是一个结构化的向量。这也是为什么目前大量的工作是关于将这些持续图转化为固定长度的欧几里得向量,或者是开发对应的核。这很棒,但是你应该使用哪种呢?
不要担心!Gudhi再一次给你解决办法。通过它的表达(representation)模块,你不仅可以计算所有的向量和核,甚至也可以使用Scikit-Learn来交叉验证并且(或)选择最佳的一种。就像下面这么简单:表达
https://gudhi.inria.fr/python/latest/representations.html
import gudhi.representations as tdafrom sklearn.pipeline import Pipelinefrom sklearn.svm import SVCfrom sklearn.ensemble import RandomForestClassifier as RFfrom sklearn.neighbors import KNeighborsClassifier as kNNfrom sklearn.model_selection import GridSearchCV
pipe = Pipeline([("TDA", tda.PersistenceImage()), ("Estimator", SVC())])param = [{"TDA": [tda.SlicedWassersteinKernel()], "TDA__bandwidth": [0.1, 1.0], "TDA__num_directions": [20], "Estimator": [SVC(kernel="precomputed")]}, {"TDA": [tda.PersistenceWeightedGaussianKernel()], "TDA__bandwidth": [0.1, 0.01], "TDA__weight": [lambda x: np.arctan(x[1]-x[0])], "Estimator": [SVC(kernel="precomputed")]}, {"TDA": [tda.PersistenceImage()], "TDA__resolution": [ [5,5], [6,6] ], "TDA__bandwidth": [0.01, 0.1, 1.0, 10.0], "Estimator": [SVC()]}, {"TDA": [tda.Landscape()], "TDA__resolution": [100], "Estimator": [RF()]}, {"TDA": [tda.BottleneckDistance()], "TDA__epsilon": [0.1], "Estimator: [kNN(metric="precomputed")]} ]model = GridSearchCV(pipe, param, cv=3)model = model.fit(diagrams, labels)
在前面的代码中,我尝试了带切片Wasserstein核和持续权重Gaussian核的核SVM、带有Persistence Images的C-SVM,带有Persistence Landscapes的随机森林,和一个带有所谓的持久图之间瓶颈距离(bottleneck distance)的简单KNN。在Gudhi中还有许多其他的可能,所以你一定要试试!如果想了解更多细节你也可以看看Gudhi的Tutorial。带切片Wasserstein核:
http://proceedings.mlr.press/v70/carriere17a/carriere17a.pdf
持续权重Gaussian核:
http://proceedings.mlr.press/v48/kusano16.html
Persistence Images:
http://jmlr.org/papers/v18/16-337.html
Persistence Landscapes:
http://www.jmlr.org/papers/volume16/bubenik15a/bubenik15a.pdf
Gudhi的Tutorial:
https://github.com/GUDHI/TDA-tutorial/blob/master/Tuto-GUDHI-representations.ipynb
用Gudhi和Tensorflow/Pytorch进行拓扑优化我很确信你目前已经成为了TDA的爱好者。如果你仍不相信,我还有其他的东西给你,这是受这篇论文启发。想象你现在想解决一个更难的问题:我想让你给我一个点云,这个点云的持续图有尽可能多的点。换句话说,你需要生成一个有好多洞的点云。https://arxiv.org/abs/1905.12200我可以看见你额头上出汗了。但我是很仁慈的,转眼间就能让你知道Gudhi(1)可以做这个。想一想:当你生成一个持续图时,这个图中不同点的坐标并不受全部的初始点云影响,是不是?对于这个持续图的一个给定点p,p的坐标仅依赖于在初始点云中组成p对应洞的点的位置,以一种简单的方式:这些坐标仅是球的并集使得这个洞出现或者消失时候的半径;或者,等价表达是,这些点中的最大的成对距离。而Gudhi(2)可以通过它的persistence_pairs()函数找出这些关系。梯度则可以简单的定义成欧几里得距离函数的导数(正式定义见这篇论文)。Gudhi(1):
http://gudhi.gforge.inria.fr/python/latest/
Gudhi(2):
https://gudhi.inria.fr/python/latest/
这篇论文:
https://sites.google.com/view/hiraoka-lab-en/research/mathematical-research/continuation-of-point-cloud-data-via-persistence-diagram
接下来让我们写两个函数,第一个从点云中计算Rips持续图,第二个计算持续图点集的导数。为了可读性我简化了一点点代码,实际的代码可以从这里找到。https://github.com/GUDHI/TDA-tutorial/blob/master/Tuto-GUDHI-optimization.ipynb
def compute_rips(x): rc = gd.RipsComplex(points=x) st = rc.create_simplex_tree() dgm = st.persistence() pairs = st.persistence_pairs() return [dgm, pairs]
def compute_rips_grad(grad_dgm, pairs, x): grad_x = np.zeros(x.shape, dtype=np.float32) for i in range(len(dgm)): [v0a, v0b] = pairs[i][0] [v1a, v1b] = pairs[i][1] grad_x[v0a,:]+=grad_dgm[i,0]*(x[v0a,:]-x[v0b,:])/val0 grad_x[v0b,:]+=grad_dgm[i,0]*(x[v0b,:]-x[v0a,:])/val0 grad_x[v1a,:]+=grad_dgm[i,1]*(x[v1a,:]-x[v1b,:])/val1 grad_x[v1b,:]+=grad_dgm[i,1]*(x[v1b,:]-x[v1a,:])/val1 return grad_x
现在让我们把函数封装进Tensorflow函数中(对Pytorch同样简单),并定义一个损失loss,这个损失是持续图点到其对角线的距离的相反数。这将迫使图有很多点,它们的纵坐标比横坐标大得多。这样的话,一个点云会有很多大尺寸的洞。import tensorflow as tffrom tensorflow.python.framework import opsdef py_func(func, inp, Tout, stateful=True, name=None, grad=None): rnd_name = "PyFuncGrad" + str(np.random.randint(0, 1e+8)) tf.RegisterGradient(rnd_name)(grad) g = tf.get_default_graph() with g.gradient_override_map({"PyFunc": rnd_name}): return tf.py_func(func, inp, Tout, stateful=stateful, name=name)def Rips(card, hom_dim, x, Dx, max_length, name=None
): with ops.op_scope([x], name, "Rips") as name: return py_func(compute_rips, [x], [tf.float32], name=name, grad=_RipsGrad)def _RipsGrad(op, grad_dgm): pairs = op.outputs[1] x = op.inputs[0] grad_x = tf.py_func(compute_rips_grad, [grad_dgm,pairs,x], [tf.float32])[0] return [None, None, grad_x, None, None]
tf.reset_default_graph()x = tf.get_variable("X", shape=[n_pts,2], initializer=tf.random_uniform_initializer(0.,1.), trainable=True)dgm, pairs = Rips(x)loss = -tf.reduce_sum(tf.square(dgm[:,1]-dgm[:,0]))opt = tf.train.GradientDescentOptimizer(learning_rate=0.1)train = opt.minimize(loss)
现在我们开始优化!这是epochs 0,20,90的结果: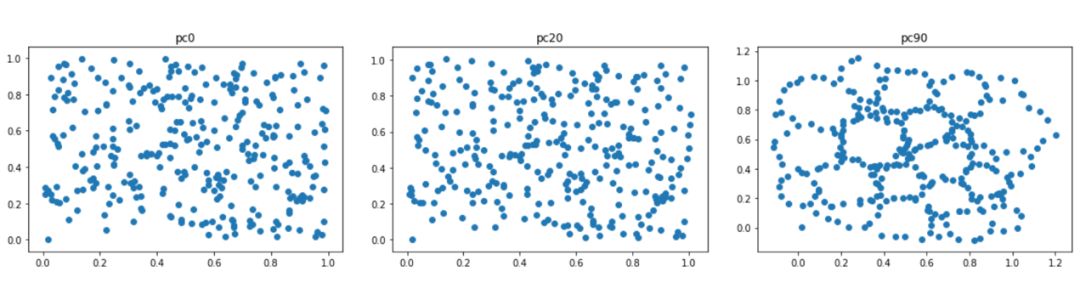
好多洞,好漂亮。。我们是不是在梦里。如果你想往前看看,使用其它的损失,查阅这个Gudhi的tutorial。https://github.com/GUDHI/TDA-tutorial/blob/master/Tuto-GUDHI-optimization.ipynb
这个帖子仅是一瞥由Gudhi,Scikit-Learn和Tensorflow提供的众多可能性。我希望我可以使你相信,在你的流程中整合TDA已经成为很简单的事情。即使许多TDA应用已经在文献中出现,肯定还有更多的应用需要去发现!
The Holy Trinity of Topological Machine Learning: Gudhi, Scikit-Learn and Tensorflowhttps://towardsdatascience.com/the-holy-trinity-of-topological-machine-learning-gudhi-scikit-learn-and-tensorflow-pytorch-3cda2aa249b5译者简介:孙韬淳,首都师范大学大四在读,主修遥感科学与技术。目前专注于基本知识的掌握和提升,期望在未来有机会探索数据科学在地学应用的众多可能性。爱好之一为翻译创作,在业余时间加入到THU数据派平台的翻译志愿者小组,希望能和大家一起交流分享,共同进步。
「完」
转自:数据派THU ;
版权声明:本号内容部分来自互联网,转载请注明原文链接和作者,如有侵权或出处有误请和我们联系。
合作请加QQ:365242293
更多相关知识请回复:“ 月光宝盒 ”;
数据分析(ID : ecshujufenxi )互联网科技与数据圈自己的微信,也是WeMedia自媒体联盟成员之一,WeMedia联盟覆盖5000万人群。











