
大数据文摘出品
作者:刘俊寰
疫情中的深度学习领域又有大动作。
3月25日下午,旷视科技举办线上发布会,宣布其自主研发、全员使用的AI生产力套件Brain++的核心深度学习框架——天元(MegEngine)开源。
回溯2017年,AlphaGo与柯洁的围棋大战让人叹为观止,也点燃了不少科研人员对AI的研发热情,其中,支撑AlphaGo运转的底层技术框架是谷歌的TensorFlow。但其实,早在2014年,旷视就已经着手开始研发其深度学习框架MegEngine,在过去5年内,这套深度学习框架被旷视全员使用,也支撑起了整个旷视的科研及产品化进程。
现在,这套深度学习框架终于开源啦!这也是本月继清华Jittor之后,又一个开源的国产深度学习框架。

作为旷视绝对招牌之一,MegEngine是什么,有何特点?在旷视的发展历程中,它做出了哪些贡献,文摘菌在这里为你一网打尽~
开源发布会上,旷视联合创始人、首席技术官唐文斌用厨房来做比喻,解释旷视的三位一体生产力平台——Brain++。
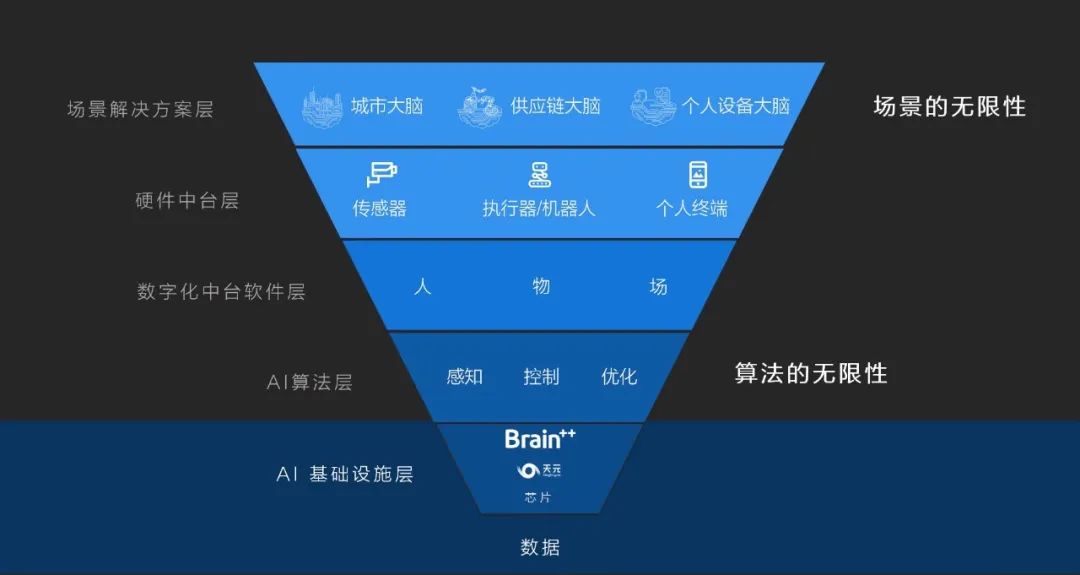
唐文斌介绍道,AI系统存在两大基础设施,芯片平台和AI生产力平台,后者涉及到数据、算法、算力等多方面问题。
什么是AI生产力平台,它就像是一道美食,需要原材料、一口好锅和一灶猛火共同烹饪炒出,以Brain++为例,数据、算法、算力分别就代表了材料、锅和猛火,今天就是这口“锅”亮相的时候。
天元MegEngine深度学习框架官方网站:
https://megengine.org.cn/

简单回想一下人工智能发展初期,想要训练出一个AI模型,至少需要一两个月,而且开发者要通过手敲代码完成计算过程,深度学习社区基本上被TensorFlow和PyTorch垄断。因此为了快速进行算法实验,落地实际工业场景,我们需要的是一个具有高性能、可复用和能灵活迭代的AI算法平台,要打造这个平台,就必须从计算性能,平台易用性,满足真实业务场景需求等各个方面进行考量。
旷视Brain++就是这样的一个系统,天元就是其中核心模块,唐文斌说,“天元”取围棋盘上的中心点之意,就是要做到训练推理一体化、兼容并包、灵活高效。
自2014年研发,2015年正式投入使用,如今旷视所有产品都使用了天元框架,整个过程可谓是来之不易。
今天天元开源代码共35万行,包括78%C++,17%CUDA,5%Python。唐文斌大方地承认道,今天发布的是Alpha版本,6月份会发布Beta版本,9月份发布正式版本。

他也很诚恳地表示,“所有程序员都知道,一个代码自己用和拿出来和别人分享的差距有多大。”因此希望有更多人对这一发布版本给出批评建议,共建更好的产品。九月份推出正式版本,即日起向企业开发。
发布会上也公布了代码的托管地址,感兴趣的同学不妨一试。
GitHub地址:
https://github.com/MegEngine/MegEngine
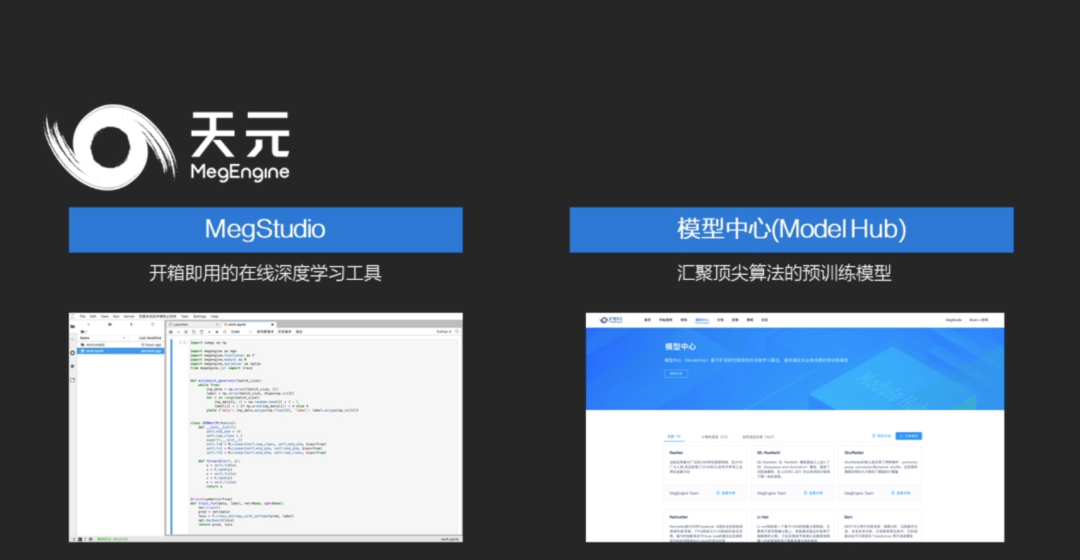
据介绍,天元系统共分为五个层次:计算接口,图表示、优化与翻译、运行时管理、计算内核。
可以从图中看到,天元支持Python和C++接口,支持静态图和动态图表达,也支持自动求导器、图优化、图编译。

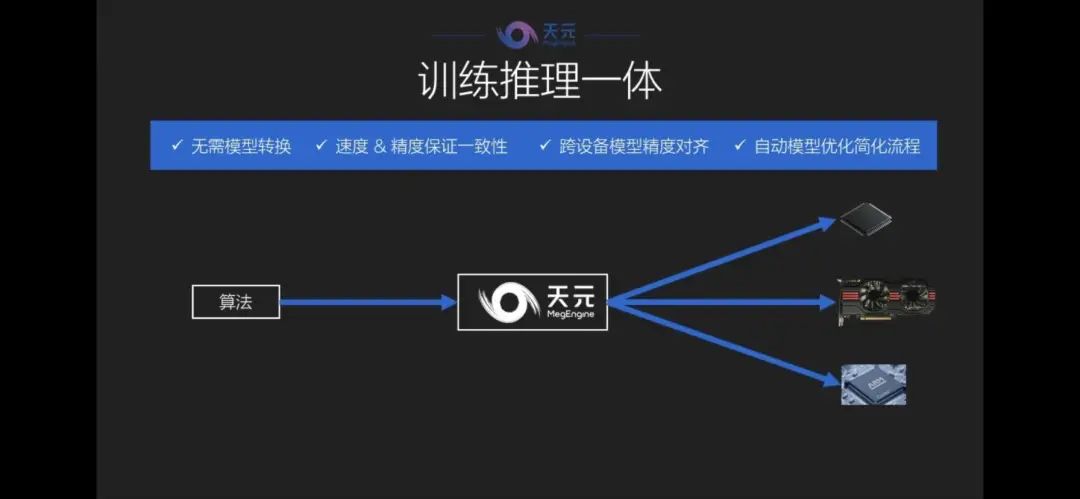
传统的训练框架和推理框架是分开进行的,也就是说,系统要先经过训练再接受新的格式,在推理框架上适配不同的场景,但是在两者转化过程中会遇到算子无法支持、手工无法优化、大量冗余算子等多种问题。
天元系统的训练和推理是一体的,因此无需进行模型转换,同时,系统内部内置有模型优化,可以有效降低手工优化的误差,精度和速度都能得到保证。
静态图和动态图之争也就是TensorFlow和PyTotch之争,但是两种框架真的不得兼得吗?天元给出的答案是,可以。动静合一就是天元的做法,从结果上看,使用静态图提速约5%-20%。
在学术界和工业界都会遇到框架接口不同引起的各种适配问题,天元在此也提出了解决方案,那就是兼容并包。天元采用了Pythonic风格API,可以很自然地被用户接受,函数的命名也尊重了以往的传统,可以直接导入PyTotch Module,方便模型复现和实验。

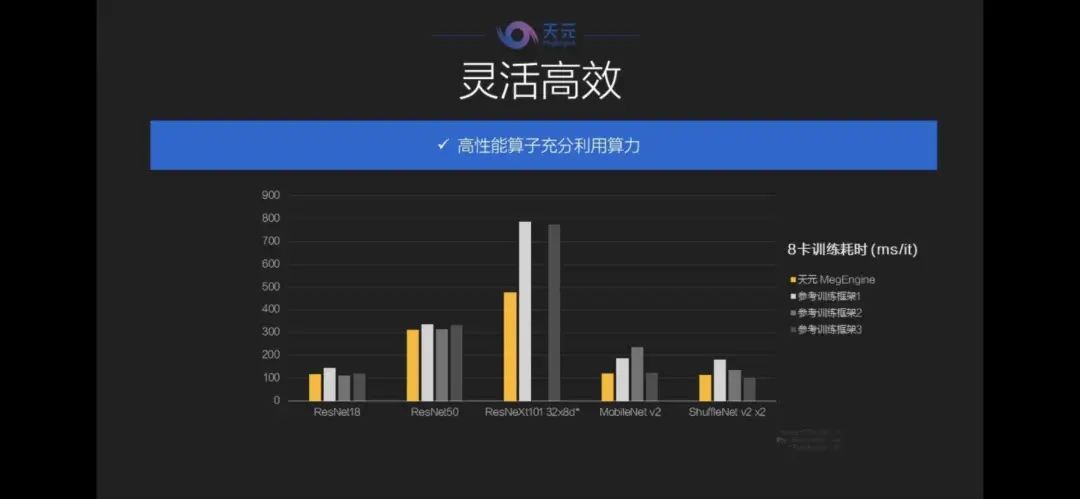
在生产环境上,天元也做到了“灵活高效”,不仅在许多算法上都取得了领先的性能,在与其他框架进行对比时速度也完全不输,同时,天元还关注到了显存和片上内存的节省,天元系统在保证不影响速度的前提下实现了20倍以上的内存减少。
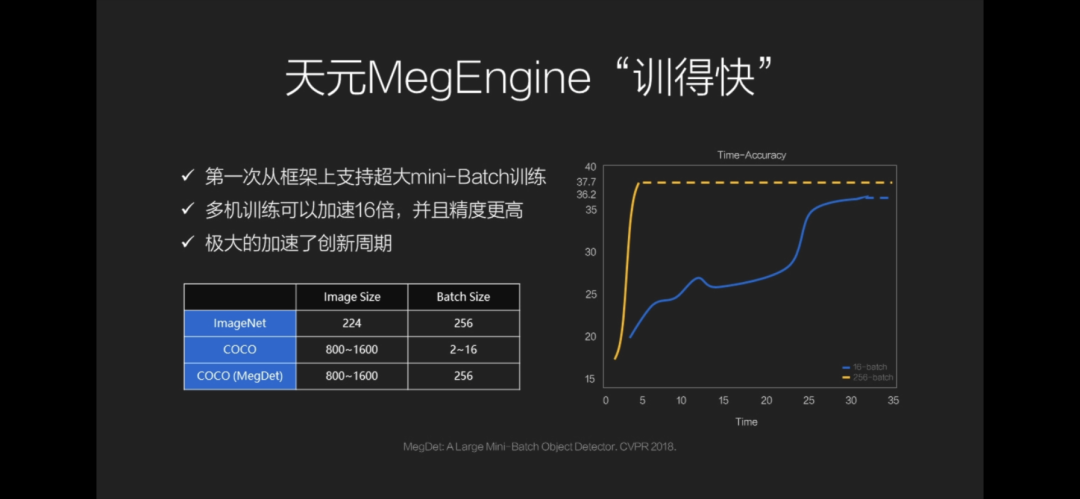
在发布会上,旷视首席科学家孙剑表示,“天元就像我们的孩子”,他也就其三大特点进行了介绍,包括框架与算法协同、高效训练系统、大规模能力,用大白话来说就是“训得好”、“训得快”、“训得动”。
孙剑表示,由于当前计算平台的特性差异比较大,无法用一种网络满足所有需求。
天元通过快速的算子算法开发,灵活高效的算子支持,Jit自动算子融合三方面,实现了端上的高性能,在自测和第三方测试中都取得了不错的成绩。目前也已经配备至国产智能手机中,加速手机的智能化。

在介绍第二个优点之前,孙剑提到,在计算机视觉挑战赛COCO中,旷视已经实现了三连冠,能取得这样的成绩,除了优秀的研究员、对比赛的理解,旷视天元系统功不可没。
旷视天元系统能够通过多机训练提速16倍,加速了创新周期,并且精度更高,而且也是第一次实现了从框架上支持超大mini-Batch训练,种种优点集中后,研究人员就可以在相同的比赛时间内测试更多的想法。
在Object365之后,孙剑表示,Object365 V2也在今天开放给大家,Object365 V2可以说是世界上最大的物体检测数据集,配备了365种常见物体,2百万张图像,2.8千万个人工标注,是COCO比赛数据集的16倍大。
面对如此庞大的数据集,孙剑表示,旷视天元完全“训得动”,高校加速比的多机训练、底显存消耗、亚线性显存节省技术、MegRay通讯框架、高效数据编码传输,这些特点都使得天元系统能够训练出一个精度更高速度更快的模型。

除了上述三个特点,孙剑让大家试想,1400多名研发人员共享高效计算资源是怎样的场景。
他说,共享时每个研发人员都有一份独有的交互式训练模式,能够让每个人随时停下来调试,不仅如此,系统还支持多人同时在线训练、数据自动预加载,自动闲置资源利用、计算配额管理,这些功能的实现,也都是要得益于旷视Brain++。

对于Brain++,用此前旷视联合创始人唐文斌的话说就是,Brain++的“目标是让研发人员获得从数据到算法产业化的综合技术能力,不用重复造轮子也可以推进AI快速落地。Brain++还引入了AutoML技术,可以让算法来训练算法,让AI来创造AI”。
发布会上,旷视云服务业务副总裁赵立威就旷视Brain++进行了更深层的介绍。
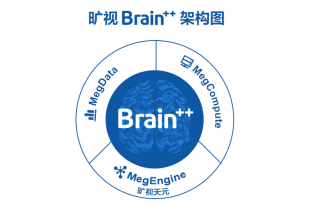
具体来说,Brain++的架构分为三部分,核心模块就是最新开源的深度学习算法开发框架天元(MegEngine),其次是提供算力调度支持的深度学习云计算平台MegCompute,以及用于提供数据服务和管理的数据管理平台MegData。
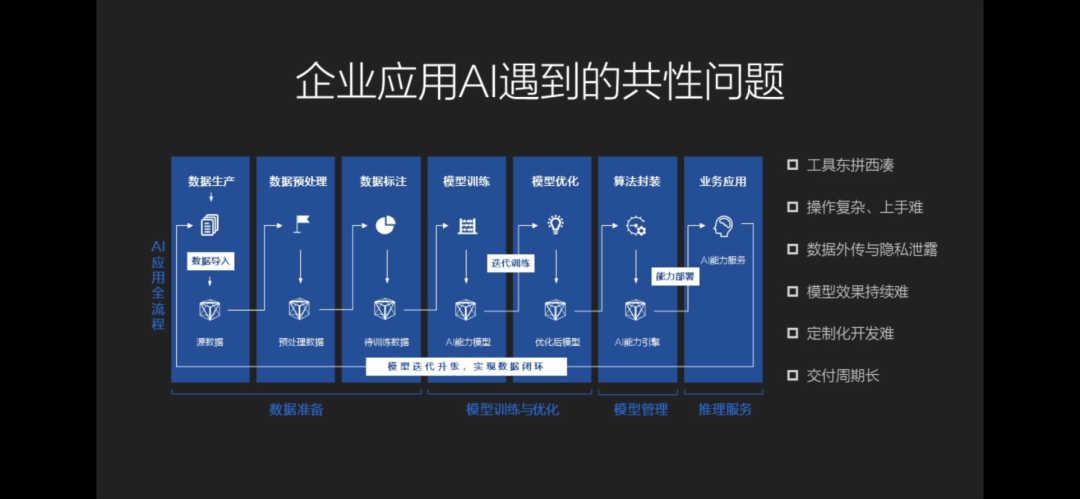
他说道,AI加速着各行各业的创新进程,但是在AI具体落地过程中马太效应还是比较明显的。其中,以企业为例,企业在应用AI时遇到了不少共性问题,比如对数据的利用、数据隐私、模型效果、难以保证使用方法在生产过程中的精度和性能需求等等。
旷视Brain++也正是基于解决这些问题提出,赵立威介绍道,在框架基础上,旷视研究院提出“三位一体”概念,融合数据和算力平台,构建出集“算法、数据和算力”于一体的AI生产力套件Brain++,自动化、规模化、集约化生产算法,在Brain++的驱动下一一成为现实。
要让AI真正助力到具体行业种,去赋能传统行业,达到商业创新的目标,赵立威在最后也向大家分享了三个通过使用旷视Brain++成功的案例,并表示,“你也可以拥有专属的Brain++平台”。
在这里,文摘菌也为大家简单总结一下,Brain++的核心模块MegEngine,也就是天元系统,是以C++为基础,和其他框架使用异构架构的框架不同,MegEngine使用了计算图方式,进行分布式计算更为便捷。同时,MegEngine引入了旷视独家AutoML技术,训练一次,就能得到整个模型空间的刻画,降低了人力成本,也大幅提高开发效率。
天元系统可实现训练、部署一体化,能够支撑大规模视觉方向的算法研发,具体又分为计算引擎、运行时管理、编译和优化以及编程和表示四个方面。
本次发布会上,众多AI界大咖也纷纷送上祝福,中国工程院院士高文表示,深度学习是目前AI能够掀起全球科研热潮的重要原因之一,而另一个则是采取了开源开放的措施,旷视这次的开源是“一件值得祝贺的事”,也是“一件重要的事”。中国科学院院士姚期智也表示,AI现在的地位就和过去数学和物理的地位很像,如何发展AI,这需要从两个角度考虑,一个是人才培养,一个是研究创新,其中,前者呼吁具有丰富交叉学科背景的人才,清华也在重点培养,包括开设智班和姚班,以及编纂AI教材,后者则需要产学研的结合,旷视Brain++正是工程化的代表。国产深度学习框架百花齐放!
清华开源首个国内高校自研的深度学习框架Jittor
先于旷视,3月20日,清华大学开发了名为Jittor的深度学习框架,这是首个国内高校自研的深度学习框架,这一框架的开源有望为深度学习社区提供新方案,推动深度学习框架国产化。根据官网介绍,Jittor是一个用元算子表达神经网络计算单元,并且完全基于动态编译的深度学习框架。根据官网的定义,“研究团队将神经网络所需的基本算子定义为元算子”,而Jittor的主要特性正是元算子和统一计算图。元算子非常底层,通过相互融合可以完成复杂的深度学习计算,体现出了易于使用的特点。研发团队表示,采用元算子的Jittor目前已经超越了Numpy,可以完成更复杂高效的操作。在统一计算图方面,Jittor融合了静态计算图和动态计算图的优点,在易于使用的同时,提供了高性能的优化。基于元算子开发的深度学习模型,可以被Jittor实时自动优化,并且运行在指定如CPU、GPU的硬件上。https://cg.cs.tsinghua.edu.cn/jittor/
https://github.com/Jittor/jittor
在设计理念上,Jittor保持着易用、灵活和及时的特点:- 易用且可定制:用户只需要数行代码,就可定义新的算子和模型,在易用的同时,不丧失任何可定制性;
- 实现与优化分离:用户可以通过前端接口专注于实现,而实现自动被后端优化,从而提升前端代码的可读性,以及后端优化的鲁棒性和可重用性;
- 所有都是即时的:Jittor的所有代码都是即时编译并且运行的,包括Jittor本身。用户可以随时对Jittor的所有代码进行修改,并且动态运行。
最近清华、旷视相继开源深度学习框架,再加上更早的开源百度PaddlePaddle,而据了解,华为也即将开源自己的深度学习框架,国产深度学习框架正在迎来发展高速期,希望借着这股东风,能够激发更多的人对AI领域的兴趣,参与到国产AI的建设中。实习/全职编辑记者招聘ing
加入我们,亲身体验一家专业科技媒体采写的每个细节,在最有前景的行业,和一群遍布全球最优秀的人一起成长。坐标北京·清华东门,在大数据文摘主页对话页回复“招聘”了解详情。简历请直接发送至zz@bigdatadigest.cn











