
1. 背景
自然语言本身是人类对世界各种具象和抽象事物以及他们之间的联系和变化的一套完整的符号化描述,它是简化了底层物理感知的世界模型。从本质上可以知道,语言就是一套逻辑符号,这意味着NLP处理的输入是高度抽象并且离散的符号,它跳过了感知的过程,而直接关注各种抽象概念,语义和逻辑推理。正是由于NLP涉及到高层语义、记忆、知识抽象以及逻辑推理等复杂的认知特性,导致基于数据驱动和统计学习的深度学习模型在NLP领域遇到了比较大的瓶颈。可以不夸张的说,NLP中复杂的认知特性已经完全超出了深度学习的能力边界。那如何打破这个魔咒,突破深度学习的能力边界,从而实现感知智能到认知智能的关键跨越呢? 这正是本文需要探索的原因所在,可能的一条出路就是通过对非结构化的数据(如业务的数据,产品的数据,行业领域的数据)进行整合和知识蒸馏,从而变成结构化的业务知识,结构化产品的知识,结构化的行业领域知识,在这些结构化的知识的基础上,再运用深度学习的模型进行推理,实现知识驱动,再进一步进阶到基于推理的驱动,这样就会形成结构化的知识推理引擎,从而提高整个智能系统的认知能力。那知识图谱就是将非结构的数据进行提炼归纳成结构化的知识的基础设施,图神经网络GNN就是在知识图谱基础设施上的推理模型。一句话概括就是:用不确定的眼光看待世界,再用确定的结构化知识来消除这种不确定性。在介绍知识图谱之前,先得弄清楚什么是知识?知识是从大量有意义的数据中归纳总结出来的,是从有意义数据中压缩、提炼,从而形成有价值的规律。比如,天文学家日夜观察各种行星的位置,及对应的时间,这些都是观察的数据,但是牛顿从这些观察的数据中发现了万有引力定律,这就是知识。就像后来的天文学家运用牛顿的万有引力定律这个有价值的知识,发现了更多的未知星体和宇宙的奥秘,知识也将大大的加强智能系统的认知能力,也将使智能系统走向更深的未知领域。知识图谱就是对知识进行存储,表示,抽取,融合,推理的基础设施。
建设一个知识图谱系统,需要包括:知识建模、知识获取、知识融合、知识存储、知识模型挖掘和知识应用6大部分:
1、知识schema建模:构建多层级知识体系,将抽象的知识、属性、关联关系等信息,进行定义、组织、管理,转化成现实的知识库。
2、知识抽取:将不同来源、不同结构的数据转化成图谱数据,包括结构化数据、半结构化数据(解析)、知识标引、知识推理等,保障数据的有效性和完整性。
3、知识融合:由于知识图谱中的知识来源广泛,存在知识质量良莠不齐、来自不同数据源的知识重复、知识间的关联不够明确等问题,所以必须要进行知识的融合。知识融合是高层次的知识组织,使来自不同知识源的知识在同一框架规范下进行异构数据整合、消歧、加工、推理验证、更新等步骤,达到数据、信息、方法、经验以及人的思想的融合,形成高质量的知识库。
4、知识存储:根据业务特点以及知识规模选择合适的存储方式将融合后的知识进行持久化保存。
5、知识模型挖掘:知识的分布式表示学习,通过图挖掘相关算法进行知识推理出新知识,关联规则挖掘一些隐藏知识。
6、知识应用:为已构建知识图谱提供图谱检索、知识计算、图谱可视化等分析与应用能力。并提供各类知识运算的API,包含图谱基础应用类、图结构分析类、图谱语义应用类、自然语言处理类、图数据获取类、图谱统计类等等。说这么多知识图谱的概念,可能这些概念有些抽象,这里给出一个实际的关务hscode领域的知识图谱的例子:知识图谱将按照欧式空间分布的的文本、图片、时间序列等数据进行归纳融合,提炼出了按照非欧空间的图结构来存储结构化知识。图结构的复杂性对传统的深度学习算法提出了重大挑战,主要是因为非欧空间的图结构数据是不规则的。每个图都有无固定数量的节点,同时图中的每个节点都有不同数量的邻居节点,这就导致传统深度学习的卷积操作不能在图结构上有效的计算。同时,传统深度学习算法的一个核心假设是样本实例彼此独立,如两张关于猫的图片是完全独立的。然而,对于图结构数据来说,情况并非如此,图中的节点通过边的连接信息,使节点之间有机的组合起来,从而天然构造了功能强大的结构性feature。另外,业界公认的传统的深度学习的一大软肋是无法有效的进行因果推理,只能进行某种意义上的统计相关性推理,这就大大降低了智能系统的认知能力。针对上述传统深度学习算法在图结构数据和因果推理上的天然软肋,业界最近兴起了针对图结构数据建模和因果推理的新方向-图神经网络GNN。图卷积神经网络GCN是目前最重要的图神经网络,本文落地的图神经网络也是基于图卷积神经网络GCN。图卷积神经网络GCN本质上是基于Message-Passing的信息传递式的通用框架,是由多层的图卷积操作组成,每一个图卷积层仅处理一阶邻域信息,通过叠加若干图卷积层可以实现多阶邻域的信息传递。基于Message-Passing的图神经网络有以下三个基本公式构成:
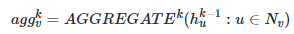
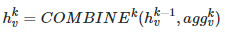
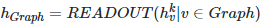
几乎所有的GNN模型的底层运行机制都是基于上述三个公式,只不过不同的AGGREGATE,COMBINE,READOUT的实现策略不同,导致演化成了GCN,GAT,GraphSAGE等不同类型的图神经网络。
3.2 图卷积网络GCN的AGGREGATE计算方式
图卷积网络GCN中的AGGREGATE是将GCN的每一层通过邻接矩阵A和特征向量
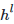 ,相乘得到每个顶点邻居特征的汇总,然后再乘上一个参数矩阵
,相乘得到每个顶点邻居特征的汇总,然后再乘上一个参数矩阵 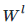 , 加上激活函数σ,做一次非线性变换得到聚合邻接顶点特征的矩阵
, 加上激活函数σ,做一次非线性变换得到聚合邻接顶点特征的矩阵 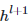 。基本公式如下:
。基本公式如下:
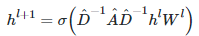
1. 是图卷积网络GCN中第l层的特征向量,其中 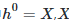 是输入特征。
是输入特征。
2. 是图卷积网络GCN每一层的参数矩阵。
3. 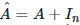 是图Graph的邻接矩阵加上每个图节点的自旋单位矩阵。
是图Graph的邻接矩阵加上每个图节点的自旋单位矩阵。
4. 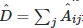 是图Graph邻接矩阵
是图Graph邻接矩阵 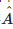 的度矩阵。上面是一般GCN的AGGREGATE策略,但是这样的AGGREGATE策略是的transductive learning的方式,需要把所有节点都参与训练才能得到图中节点的特征表示,无法快速得到新节点的特征表示。为了解决这个问题,参考文献[1]中的GraphSage利用采样(Sample)部分结点的方式进行学习,学习到K个聚合AGGREGATE函数,GraphSage的重点就放在了AGGREGATE函数的设计上。它可以是不带参数的𝑚𝑎𝑥, 𝑚𝑒𝑎𝑛, 也可以是带参数的如𝐿𝑆𝑇𝑀等神经网络。下图是参考文献[1]GraphSage的AGGREGATE函数的学习过程:
的度矩阵。上面是一般GCN的AGGREGATE策略,但是这样的AGGREGATE策略是的transductive learning的方式,需要把所有节点都参与训练才能得到图中节点的特征表示,无法快速得到新节点的特征表示。为了解决这个问题,参考文献[1]中的GraphSage利用采样(Sample)部分结点的方式进行学习,学习到K个聚合AGGREGATE函数,GraphSage的重点就放在了AGGREGATE函数的设计上。它可以是不带参数的𝑚𝑎𝑥, 𝑚𝑒𝑎𝑛, 也可以是带参数的如𝐿𝑆𝑇𝑀等神经网络。下图是参考文献[1]GraphSage的AGGREGATE函数的学习过程:
3.3 图卷积网络GCN的COMBINE计算方式
图卷积网络GCN中的COMBINE的计算方式一般就是将第k层节点通过AGGREGATE学到的向量和第K-1层已经学习到的节点向量进行CONCAT,然后在CONCAT后的向量加上一层神经网络Dense层即可。GCN中的COMBINE采用concate就是将两个原始特征直接拼接,让网络去学习,在学习过程中确定最佳的方式去融合特征,这样保证特征在融合过程中信息不会损失。
3.4 图卷积网络GCN的READOUT计算方式
图读出操作(READOUT)就是用来生成整个图表示的,综合图中所有节点的特征向量最终抽象出整体图的特征表示。GCN的图读出操作目前有基于统计的方法与基于学习的方法两种。
统计的方法实现图读出操作一般常用的是sum,max,average来求整个图的抽象表示,这些统计的好处就是简单,不给整体的图神经网络模型带来额外的参数,但是sum,max,average带来的不利因素也是显然易见的,这些统计操作会对高维特征进行压缩,使每一维上数据的分布特性被完全抹除了,带来了信息的损失比较大。
基于统计的方法的不足是无法参数化同时带来信息损失,这样难以表示结点到图向量的这个“复杂”过程。基于学习的方法就是希望用神经网络来拟合这个过程。目前在参考文献[2]来自斯坦福等大学的研究者提出了DIFFPOOL,这是一个可以分层和端到端的方式应用于不同图神经网络的可微图池化模块,DIFFPOOL 可以有效的学习出整体图的层级表征。DIFFPOOL 可以以非均匀的方式将节点坍缩(collapse)成软簇,并且倾向于将密集连接的子图坍缩成簇。因为 GNN 可以有效地在密集的、类似团的子图(直径较小)上传递信息,因此在这样密集的子图上池化所有节点不太可能会损失结构信息。一句话概括,DIFFPOOL不希望图中各个结点一次性得到整体图的向量表示,而是希望通过一个逐渐压缩信息的过程,来得到最终图的表示,如参考文献[2]下图所示:

研究者通过可视化图神经网络不同层的簇分配研究了 DIFFPOOL 学习有意义节点簇的程度。参考文献[2]中的DIFFPOOL 的层级聚合分布的图展示了一个来自 COLLAB 数据集的图形在第一层和第二层节点分配的可视化图,图中节点颜色表示属于哪个聚合簇。

4.基于知识图谱的图神经网络在hscode产品归类中的落地
hscode是《商品名称及编码协调制度》的简称。编码协调制度由国际海关理事会制定,英文名称为The Harmonization System Code (HS-Code),是对各种不同产品出入境应征/应退关税税率进行量化管理的制度。hscode是各国海关、商品出入境管理机构确认商品类别、进行商品分类管理、审核关税标准、检验商品品质指标的科学系统的国际贸易商品分类体系。hscode总共22大类98章,前6位编码国际通用,后面的编码由各国/地区根据实际情况自行扩展,我国海关现行的是10位海关编码。hscode归类是一个非常特殊的NLP场景,在一般的NLP场景中如果根据文本语义匹配在top3能召回的话,那表明NLP的效果处理的还不错。但是由于hscode归类在通关过程中具有确定汇率,确定监管条件等等关键作用,导致了hscode需要更严的准确率,这也是和其他业务场景产品归类最大不同的地方,必须确保top1的准确性。举个具体的例子,大家可能更有体感一些。

通过上面的例子,我们发现从传统NLP文本语义相似度上来说,上面几条文本的语义匹配相似度非常高,但是hscode需要根据不同的申报要素(例如上图中的"是否液态要素","额定容量")的具体业务知识来进行精细化推理才能得出正确的hscode。
4.1 基于传统深度学习的NLP模型在hscode归类中的瓶颈
在hscode归类中,基于传统深度学习的NLP模型架构图如下:

传统深度学习的NLP模型主要包括以下几部分:
1、计算hscode质点向量:基于词向量平均池化的kmeans聚类算法计算hscode质点向量, hscode的向量表达能力和抗干扰能力。
2、hscode层级分类器:通过两层的层级分类器先进行粗排,选出候选的hscode。
3、细排阶段的语义推理:基于hscode产品归类领域特定的知识形态最终选择了基于BiLSTM + Attention的Encoder-Decoder语义推理模型。
基于传统深度学习的NLP模型已经在线上hscode归类场景中运行了,通过业务同学对线上真实客户原始提交的归类样本2223条进行评估,以下准确率为:算法预测HsCode top1的准确率,结果如下:

未修改:业务审核小二对客户原始输入信息没有做任何改动。
编码品名未修改:业务对品名未修改,但是修改了商品其他归类申报要素属性。
其他修改:其他修改的情况比较复杂,由于hscode归类本身是个很复杂专业的领域,客户原始提交的信息不能满足海关申报的规范,业务小二需要对客户原始提交的信息进行修改。
评估结果详细分析:由于基于传统深度学习NLP模型的训练数据都是来自业务小二审核后的规范样本上进行训练,这就可以看出在客户原始输入信息未修改那部分,传统深度学习NLP模型的准确率和算法测试集上的准确率差相差不多为89.3%,同时在品名未修改,但是其他归类要素修改了的情况,传统深度学习NLP模型的准确率在87.7%,证明了传统深度学习NLP模型有一定程度上的泛化性。但是在第三种其他修改情况,即客户原始提交信息不满足海关规范,传统的深度学习NLP模型的准确率只有17.3%。这样在总体样本上的准确率只有59.3%(计算公式为:0.31 X 89.3% + 0.28 X 87.7% + 0.41 X 17.3% = 59.3%)。
通过上面的分析我们发现,传统深度学习NLP模型在第三种其他修改情况(客户原始提交的信息不能满足海关申报的规范)下,准确率非常低,我们对第三种其他修改情况下的具体badcase进行了一定的拆解,主要原因如下:
1、申报要素不缺失,但是客户输入的具体申报要素值那些不规范,这种不规范如下:客户原始输入是行业术语"来令片"(其实是摩擦片),然而在nlp语料里没有这些行业领域知识,故传统深度NLP模型无法解决这些case。
2、申报要素不缺失,但是由于申报要素值需要进行一些逻辑计算,如 客户输入"含棉75%,羊毛10%,纤维15%",而当棉的成分<60%是hscode A,含棉成分>60%是hscode B,这种有逻辑计算的nlp问题,传统的深度NLP模型也无法解决这些case。
3、申报要素用户输入过多,带来太多的噪声。传统深度NLP模型不能有效抓取核心申报要素的结构性信息,容易被多余的噪声带偏。
4、hscode体系中有太多了其他,除非等托底编码,就是除了hscode A、hscode B、hscode C以外的情况都是hscode D,这种估计也需要一定的推理才能解决这个问题。
5、申报要素缺失,客户没有输入完整的hscode申报要素,从而导致不能正确归类。这个估计任何模型都无效。
上面的第1点和第2点是缺少结构化知识用于模型推理,第3,4点是不能有效的抓取结构化的特征进行因果逻辑推理,因此我们落地了基于知识图谱的GCN模型来尝试解决上述的问题。
4.2 hscode归类场景中知识图谱的知识schema建模
知识图谱的元数据schema信息定义非常重要。设计之初要既考虑本体之间的关系,还要考虑本体schema维度变化。hscode产品归类知识引擎的schema如下:

4.3 基于知识图谱的GCN模型的整体算法架构

1、在hscode领域,底层知识图谱的构建的实体是品名,具体申报要素值,申报要素对应行业领域的属性值,图谱中的边是不同申报要素的key,这样底层的图结构是个不同关系边组成的异构图。同时由于同一个商品,申报要素值的不同会导致对应不同的hscode(label),因此这里hscode(label)会标记在以品名,申报要素值构建的子图上,以这样的子图作为预测的实体节点。
2、在hscode领域,知识图谱的每个实体节点存储的是经过向量平均池化后的word2vec语义向量,这样也使这个图谱具有语义泛化性,这和以前每个知识图谱每个节点存储在以字面文本为主的实体有所不同。
3、在hscode领域,存储在知识图谱中的结构性知识需要经过图中节点文本语义特征,图中不同边的特征,图的结构特征等一起融合转化成GCN模型的embeding输入层。

4、在hscode领域,图神经网络的邻居节点的聚合机制如下:

具体的AGG策略如下:
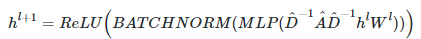
4.5 落地效果
从4.1的详细分析可以看到基于传统深度学习的NLP模型在hscode线上的准确率为:准确率只有59.3%(计算公式为:0.31 X 89.3% + 0.28 X 87.7% + 0.41 X 17.3% = 59.3%)。基于知识图谱的GCN模型取了2017-01-01 到 2020-01-08之间的所有客户原始提交数据进行训练,另取了2020-01-09到2020-01-12的5687条线上真实的客户原始提交的数据作为测试数据,业务评估的结果是:基于知识图谱的GCN模型的准确率到达了76%,相比以前传统深度学习的NLP模型准确率提升了16.7% ,证明了基于知识图谱的GCN模型具有更好的容错性。
5.实验
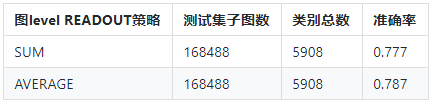
目前设立了2种对比实验,对比的指标是在测试集上的准确率。1种是图神经网络GCN的图level READOUT策略sum和average的对比,2种是底层知识图谱的图结构做一些改变,一种是较简单的星形结构,另一种是复杂的图结构。
在保持知识图谱的GCN模型其他参数不变的情况下,将GCN的图level READOUT策略由sum改成average,观察在测试样本上的准确率:
在保持知识图谱的GCN模型的参数都相同的情况下,将底层的知识图谱的存储结构一种是简单的星形结构,即只有品名-申报要素发生边的关联,申报要素之间不产生边的关系,另一种知识图谱的存储结构是复杂的图结构,除了品名和申报要素产生边的关联,敏感申报要素之间也产生边的关系,属性值和申报要素之间同样产生边的关联。
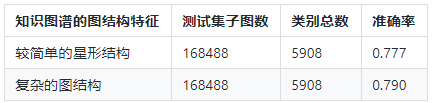
通过实验可以发现,知识图谱的底层结构化知识越丰富,基于知识图谱的GCN模型的准确率有会有相应的提升。改变整个图神经网络模型的READOUT策略对模型的准确率提升也一定的帮助。接下来会进一步做更多的实验,来充分挖掘基于知识图谱的GCN模型在NLP中的潜力。
6.未来思考
1、在很多业务领域,人工梳理了大量的业务规则知识,这些异构的规则知识如何抽取融合进知识图谱,进一步提升知识图谱的结构化的推理能力。业务梳理的多阶逻辑规则,如何用图谱进行存储。业务梳理的人工规则类似于规则树组织形式,将与、或、非等原子逻辑命题有机的组织在一起,这里如何将业务梳理的多阶逻辑规则树,抽象出实体和关系,从而转化成图谱结构,也是个未来需要攻坚的难题。
2、规则如何与图神经网络进行有效的融合。比如hscode领域还沉淀了大量的人工规则,这些规则是宝贵的知识财富,这些规则如果作为teacher-network,去指导hscode归类任务这个student-network,将能大大的提升hscode领域的精确性。规则这个teacher-network相当于起到指导和约束作用,在规则teacher-network学习出的各个规则的约束子空间更利于语义推理。这里规则如何转化成teacher-network,进而与知识图谱的图神经网络结合也是一个重要的优化方向。
3、目前的知识图谱还主要是基于文本构建的,真正完善的知识图谱应该是个多模态的结构化知识,比如除了文本,还应该有图片,语音等多模态信息,只有多模态的结构化知识,才能进一步推动整个智能系统的认知能力。
[1]Inductive Representation Learning on Large Graphs, https://arxiv.org/abs/1706.02216
[2]Hierarchical Graph Representation Learning with Differentiable Pooling, https://arxiv.org/abs/1806.08804
[3]https://www.cnblogs.com/SivilTaram/p/graph_neural_network_3.html
[4]https://zhuanlan.zhihu.com/p/68064309
[5]https://zhuanlan.zhihu.com/p/37057052
大咖架构师成长“三部曲”
什么样的人适合做架构师?做架构师都有哪些坑?如何才能成为一名优秀的架构师?阿里云MVP沈剑将和大家分享自己的心得看法,以及他的架构师成长之路。
识别下方二维码,或点击文末”阅读原文“收看文章和视频回放:


一分钟搭建会话机器人,阿里是怎么做到的?










