在新的文档被添加到索引内存缓冲区的同时,它们也被追加到分片的translog。translog是一个持久化的,记录所有更改操作( index, delete, update, or bulk)的write-ahead日志,可以防止数据丢失,并且可以用于分片的数据恢复。
每次flush操作,内存缓冲区中的所有文档都被refreshed(存储在新的segment中),所有内存中的segment都将落盘,并且清除translog。
有三种条件可以触发flush操作:
translog日志达到限制大小(index.translog.flush_threshold_size,默认为512MB);
如果设置了index.translog.durability=request,则每次更新操作( index, delete, update, or bulk)之后都执行flush(这是Elasticsearch的默认行为)
如果index.translog.durability= async,则采用异步sync机制,每index.translog.sync_interval执行一次flush操作,默认是5秒,但是这种情况可能导致未落盘的数据丢失。
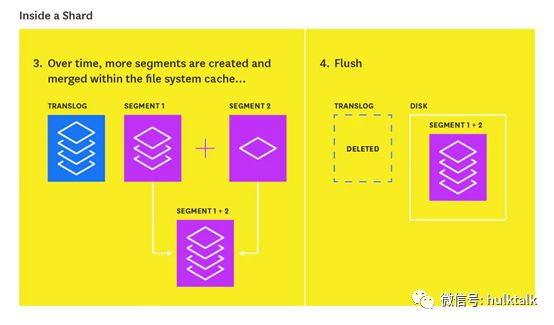
flush的过程如下图所示:
Elasticsearch提供了许多指标,您可以使用这些指标评估索引性能并优化更新索引的方式。