小编现在每天思考最多的问题就是
到底什么时候能发财啊!!!
再看看每个月工资卡里的钱
真的是只能以45度角仰望天空
一直以来,年底都是离职的高峰期
嗑着瓜子,刷着51job
学习Python也有几个月了,
该考虑换工作啦,
看了眼招聘网站,就像这样~
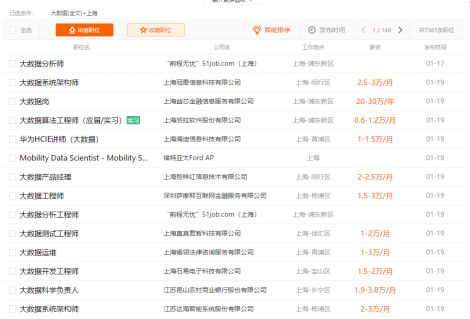
信息琳琅满目不知该怎么办了,这时候,我想到了Python爬虫,如果能把信息都下载下来,可以随时随地的分析,这样一定可以找到称心如意的工作
一、准备工作
语言:Python3
工具:Pycharm,firefox
技术:requests,BeautifulSoup,re,csv
二、流程概述
爬取51JOB相关工作第一页,获得页数
然后开始爬虫
获得每一页详细信息链接
通过链接获取详细信息
存入CSV文件
三、具体实现
a)使用浏览器前往51JOB打开开发者工具,进行搜索,我们选择http://m.51job.com/,一般来说大型网站的PC端会有反爬虫措施,相对起来移动端会容易点,不过51的PC端也很容易爬,只是不喜欢那个页面风格而已。

这样信息就一览无遗了,从右边的窗口我们能看到url,参数,以及响应页面
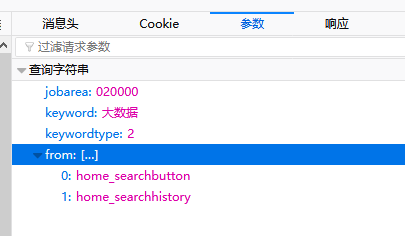
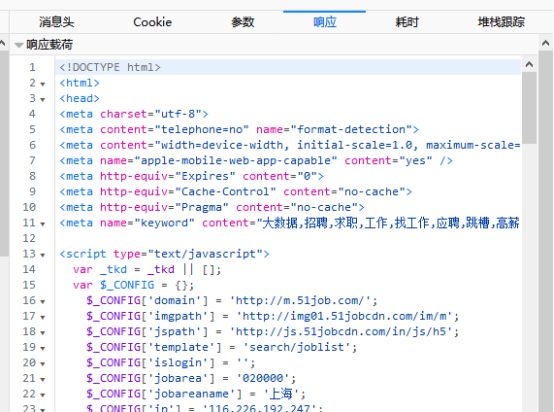
所以我们只要填写参数所有的数据要求,我们便能等到一串HTML代码,这就是我们要爬取的内容了。
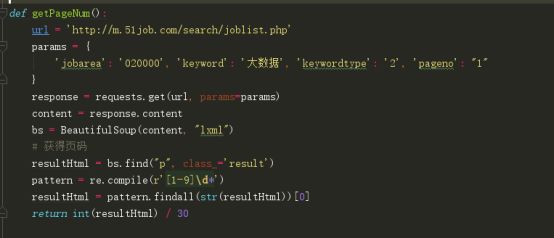
b)我们需要先直接请求第一页,获取总数,使用requests获取数据,然后使用bs解析,这两个python库,API都很简单并且都比较轻量,很适合初学者学习使用,利用正则表达式获取总工作数量
数了下大约一页可以显示30条记录,那我们就能得出需要爬的页数

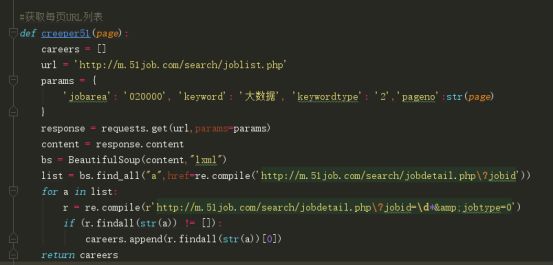
c)从密密麻麻的HTML中我们点开形如“http://m.51job.com/search”这样的链接,工作的详细信息映入我们眼帘,这就是我们数据的来源,我们把获得的链接存入一个列表中,便于我们接下来的调用。HTML我们使用BS4解析,BS4有四种解析器,lxml是需要安装C语言库的,我们可以使用html.parser库,lxml速度快但是在这个项目里并没有多明显。

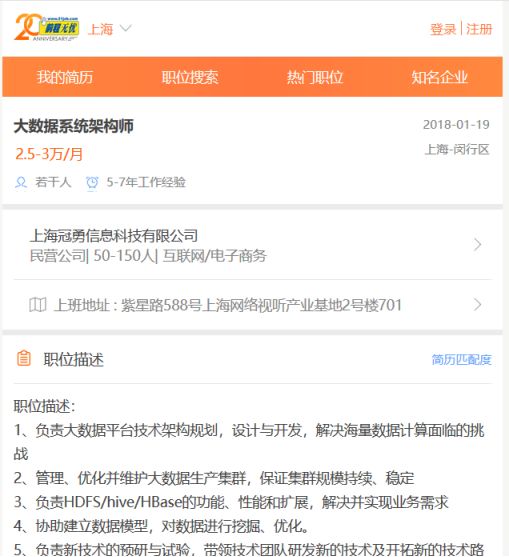
d)点开链接,我们需要的信息一目了然,从中我们选取我们需要的信息,可以直接使用bs的方法获取,也可以使用正则表达式提取相关段落。特别注意的是有些字段在某些页面是不存在的,比如工作经验,需要判断。
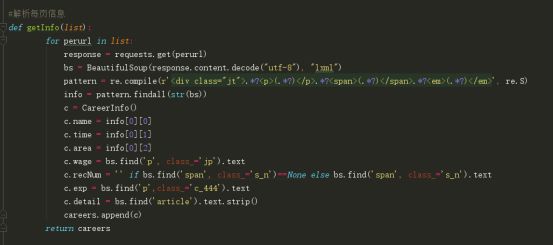
e)最后便是把信息插入到csv文件中,大家也可以使用mysql,mongoDB等工具存放数据。
这里特别注意的是,使用”w”模式写,会有空行,但是使用二进制”wb”模式会报二进制与字符串不匹配,所以在打开时候加入参数newline=’’,会避免空行。

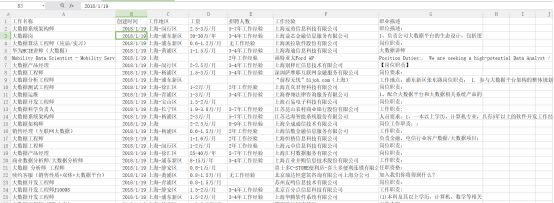
最后完成如上图,可以使用熟悉的Excel软件进行排序操作,随时随地可以查看了。
Python作为现在最流行的一种语言之一,以其编写简单不罗嗦,类库数量庞大而著称。自从学习了python,厚重的JAVA早被我抛到九霄云外了,日常编写点应用类工具什么的真的特别方便。
编写应用并不困难,只要思路理清了,对流程进行分解,按块来编程,最后组装起来,如果错了,直接修改出错的块,并不需要动整个代码。
看了上文介绍的如何用 找工作
找工作
是不是看文字还不够具体?
小编下周还为你精心准备了三个 的视频直播课。
的视频直播课。
手把手的教你如何用Python抓取数据。

赵瑾
数据分析讲师,多年开发经验,擅长JavaScript,Python, MATLAB,SASS等语言,对于数据可视化有独特见解,曾参与工商银行网站建设,某电商平台的设计,开发,及最后测试上线全部流程。
课程收益
1、分块解析:“人工智能”是什么
2、行业内情:人工智能就业前景如何,真的有那么好吗?
3、实战教学:python语言环境
直播时间:1月29日周一19:30-21:30
主题:2小时破冰爬虫技术 - 抓取51job职位信息
课程收益
1、直白解答:海量数据从哪来?
2、干货分享:爬虫抓取数据的有哪些流程?
3、实战教学:python实现(BeautifulSoup)
直播时间:1月31日周三19:30-21:30
课程收益
1、掌握贝叶斯公式
2、掌握垃圾邮件过滤原理
3、邮箱过滤技术实操演示
直播时间:2月2日周五19:30-21:30
扫码关注公众号

回复“直播”即可获得免费看课的资格~
 更多惊喜请阅读原文
更多惊喜请阅读原文










