
Python部落(python.freelycode.com)组织翻译,禁止转载,欢迎转发。
特性
PyFunctional通过使用链式功能操作符使得创建数据管道变得简单。以下是pyfunctional及其内置工具可以做什么的几个例子:
● 链式运算符:seq(1, 2, 3).map(lambda x: x * 2).reduce(lambda x, y: x + y)
● 易表达且功能完整的API
● 读写 text, csv, json, jsonl, sqlite, gzip, bz2和lzma/xz文件
● 并行化“embarrassingly parallel”操作像map一样方便
● 完整的文档,严格的单元测试套件,100%的测试覆盖率,以及提供健壮性的CI
pyfunctional API的灵感来自于Scala集合,Apache Spark RDDS,和微软的LINQ。
安装
在pypi上可以获得PyFunctional并且可以通过运行以下命令安装:

然后在python上运行:from functional import seq
示例
PyFunctional对许多任务有用,并可以打开几种常见的文件类型。以下是你能做的一些例子。
简单的例子

流、转换和动作
PyFunctional有三种类型的功能:
1、流:读取数据以供集合API使用。
2、转换:使用诸如map, flat_map和filter之类的函数从流中转换数据。
3、动作:引起一系列的转变来求一个具体的值。to_list,reduce和to_dict是动作的例子。
在表达式seq(1, 2, 3).map(lambda x: x * 2).reduce(lambda x, y: x + y)中,seq是流,map是变换,而reduce是动作。
过滤账户交易列表
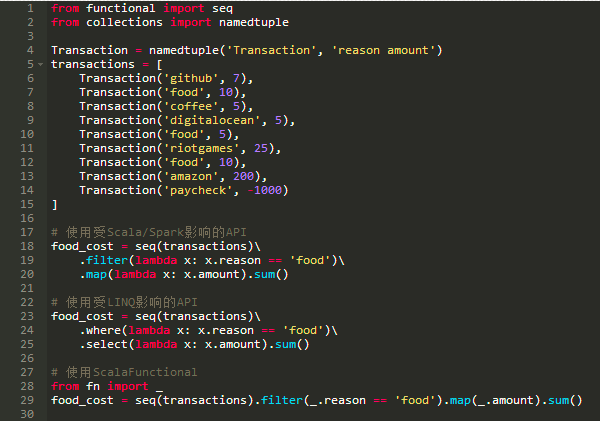
字数统计和连接
账户交易示例可以使用列表解析用纯Python轻松完成。为了展示PyFunctional擅长的一些事情,请看一下几个字数统计的例子。

在下一示例中,我们使用包含消息和元数据的json(jsonl)格式的聊天记录。一个典型的jsonl文件每行上有一个有效的json。以下是examples/chat_logs.jsonl中的几行。


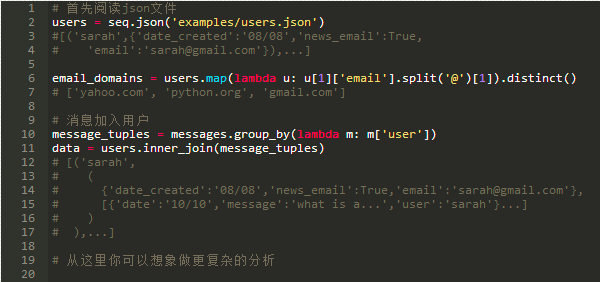
接下来,让我们继续这个例子,但是从examples/users.json引入一个用户的json数据库。在前面的例子中,我们展示了PyFunctional如何进行字数统计,下一个例子中展示PyFunctional如何加入不同的数据源。
CSV,聚合函数,和集合函数
在examples/camping_purchases.csv中有一个露营购物列表。让我们做一些成本分析,并比较存储在examples/gear_list.txt所需的野营装备列表。
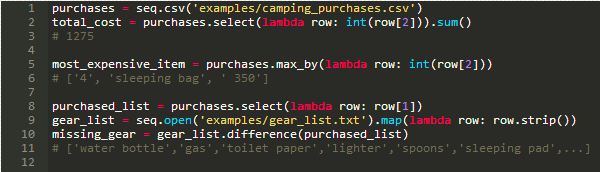
除了上面显示的聚合函数(sum和max_by)之外,还有更多。同样地,除了difference之外,还有一些集合函数。
读/写SQLite3
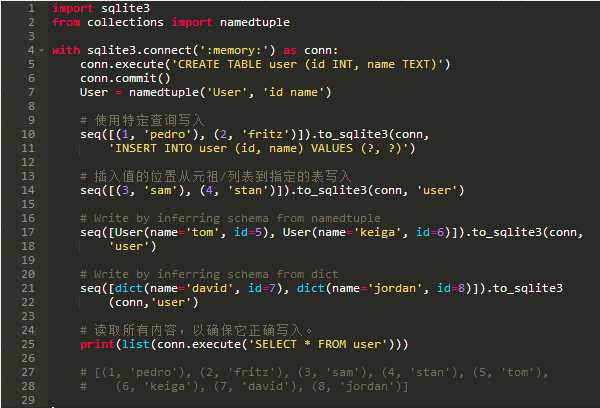
PyFunctional可以读取和写入SQLite3数据库文件。在下面的示例中,从中examples/users.db读取用户,将其列id:Int和name:String作为行存储。

写入SQLite3数据库同样简单
写入文件
就像PyFunctional可以从csv, json, jsonl, sqlite3和text文件读取一样,也可以写入它们。有关完整的API文档,请参阅集合API表或者官方文档。
压缩文件
PyFunctional将自动检测用gzip, lzma/xz和bz2压缩的文件。这是通过检查文件的前几个字节来确定它是否被压缩,因此不需要修改代码来工作。
要编写压缩文件,每个to_函数都有一个参数compression,可以将其设置为默认None用于无压缩,gzip或gz用于gzip压缩,lzma或xz用于lzma压缩和bz2用于bz2压缩。
并行执行
启用并行性所需的唯一更改是导入from functional import pseq而不是from functional import seq,而且使用seq的地方使用pseq。以下操作并行运行,在将来的版本中将实现更多的操作:
● map/select
● filter/filter_not/where
● flat_map
并行化使用Python multiprocessing和embarrassingly parallel操作链,来降低间接成本。例如,一系列映射和过滤器将一次执行,而不是使用multiprocessing在多循环中执行。
文档
下面是简明的文档,完整的文档位于docs.pyfunctional.org。
Streams API
所有的PyFunctional流都可以通过seq对象来访问。创建一个流的主要方法是通过调用一个可迭代的seq。可调用的seq是灵活的,可以接受多种类型的参数,如下面的例子所示。

seq还提供了进入其他流的属性函数,如下所示。
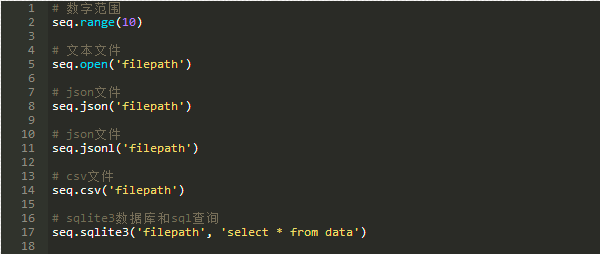
有关这些函数可以使用的参数的更多信息,请参考流文档。
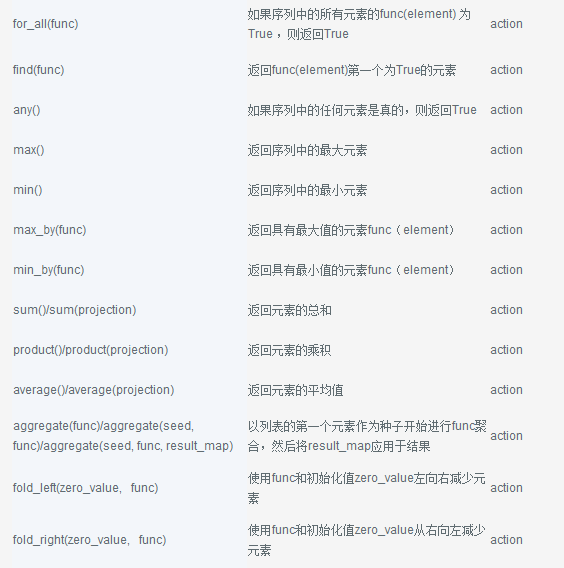
转换和动作API
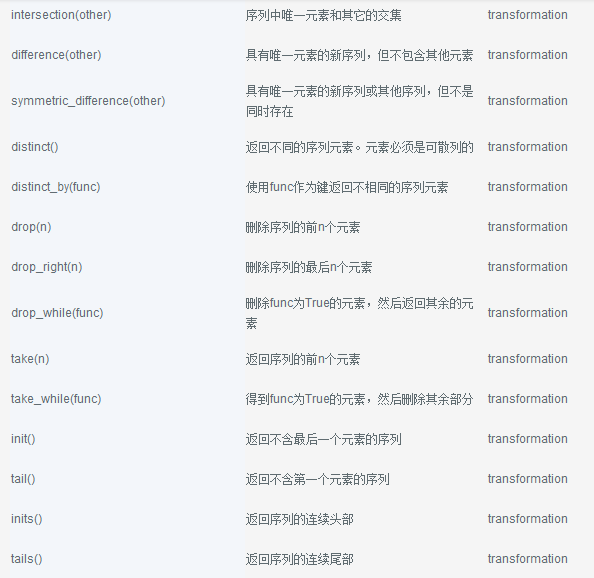
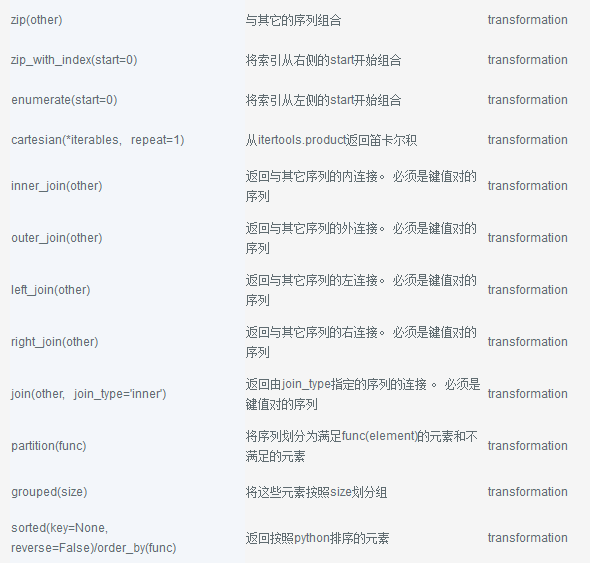
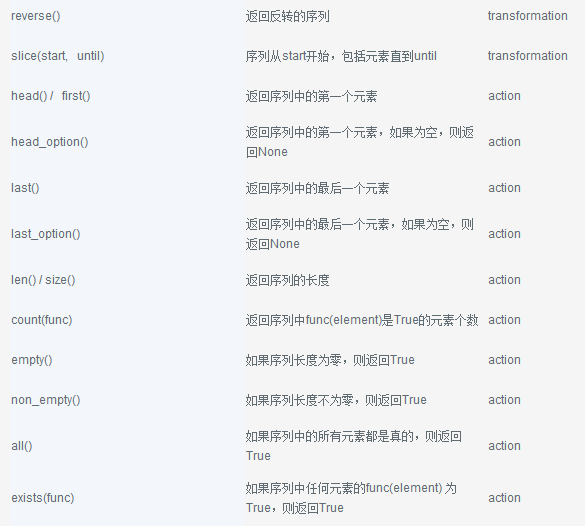
下面是seq的流对象可以调用的函数的完整列表。有关完整的文档参考转换和操作API。



延迟执行
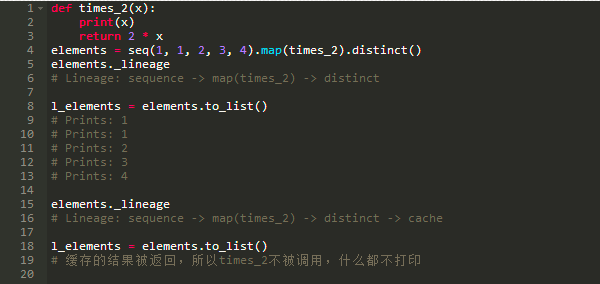
只要有可能,PyFunctional将延迟计算。这是通过跟踪已经应用到序列的转换列表来完成的,并且只有在一个动作被调用时才对它们进行求值。在PyFunctional中,这被称为跟踪谱系。这也是PyFunctional缓存计算结果的能力,以防止昂贵的重新计算。这主要是为了保持明智的行为,并谨慎使用。 例如,调用size()将缓存基础序列。 如果这没有完成,并且输入是一个迭代器,那么进一步的调用将在一个已到期的迭代器上运行,因为它被用来计算长度。 类似地, repr也是缓存的,因为它在交互式会话中经常使用, 而交互式对话中不希望重新计算相同的值。 以下是一些检查谱系的例子。
如果通过seq.open和相关API打开文件,则会给予特殊处理。 functional.util.ReusableFile实现了标准python文件的包装,以支持在单个文件对象上的多次迭代,同时正确处理迭代终止和文件关闭。
路线图的想法
● 基于SQL的查询计划器和解释器
● _ lambda运算符
● 准备1.0下一版本
贡献和错误修复
任何贡献或错误报告都是受欢迎的。 到目前为止,pull请求的接受率为100%,贡献者对代码提供了有价值的反馈和评论。 听到这个软件包的用户,特别是它的用途,运行良好,和还有什么可以改进,真是太棒了。
如果你也想做出贡献,创建一个PyFunctional的分支 ,进行更改,然后确保它们在TravisCI上运行时通过 (您可能需要注册一个帐户并链接Github)。 为了合并,所有的pull请求必须:
● 通过所有的单元测试
● 通过所有的pylint测试,或者忽略警告并解释为什它这样做是正确的
● 在coveralls.io上实现100%的测试覆盖率。
● 编辑CHANGELOG.md文件
联系
Gitter聊天
支持的Python版本
PyFunctional支持Python 2.7, 3.3, 3.4.4, 3.5和PyPy
更新日志
更新日志
关于我
关于我(作者)要了解更多,请访问我的网页pedrorodriguez.io。
我是科罗拉多大学博尔德分校计算机科学博士研究生。 我的研究兴趣包括大型机器学习,分布式计算和相邻领域。 在2015年,我在加州大学伯克利分校完成了计算机科学本科学位。之前我曾在Apache Berkeley的加州大学伯克利分校进行过研究,曾在Trulia担任数据科学家,今年夏天将担任Oracle Data Cloud的数据科学家。
我在Trulia时广泛使用Python,并且发现我想念Spark RDD和Scala集合操纵数据的易用性,创建了PyFunctional。当Scala不是一个选项或者PySpark过于复杂时,该项目从这些API和LINQ得到最好的想法来提供一个简单的方法来操作数据。
贡献者
这些人慷慨地贡献了他们的时间来改进PyFunctional
● versae
● adrian17
● lucidfrontier45
● Digenis
● ChuyuHsu
英文原文:http://www.pyfunctional.org/
译者:张新英










