作者海向,Java知音撰稿人,前58同城后端研发工程师,现某知名金融科技类公司Java工程师,热爱技术研究,技术分享。如果您有好的作品分享,公众号菜单栏“关于我们”中查看投稿方式。
什么是elasticsearch
Elasticsearch 是一个开源的高度可扩展的全文搜索和分析引擎,拥有查询近实时的超强性能。
大名鼎鼎的Lucene 搜索引擎被广泛用于搜索领域,但是操作复杂繁琐,总是让开发者敬而远之。而 Elasticsearch将 Lucene 作为其核心来实现所有索引和搜索的功能,通过简单的 RESTful 语法来隐藏掉 Lucene 的复杂性,从而让全文搜索变得简单
ES在Lucene基础上,提供了一些分布式的实现:集群,分片,复制等。
搜索为什么不用MySQL而用es
我们本文案例是一个迷你商品搜索系统,为什么不考虑使用MySQL来实现搜索功能呢?原因如下:
es在大厂中的应用情况
es客户端选型
spring-boot-starter-data-elasticsearch
我相信你看到的网上各类公开课视频或者小项目均推荐使用这款springboot整合过的es客户端,但是我们要say no!
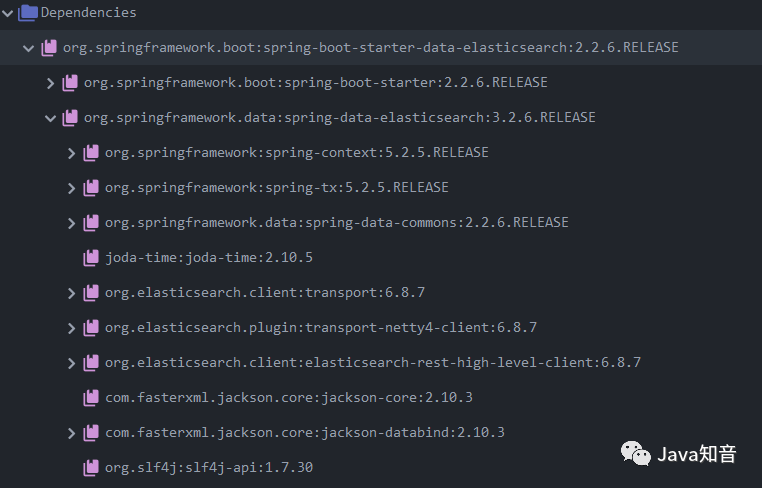
此图是引入的最新版本的依赖,我们可以看到它所使用的es-high-client也为6.8.7,而es7.x版本都已经更新很久了,这里许多新特性都无法使用,所以版本滞后是他最大的问题。而且它的底层也是highclient,我们操作highclient可以更灵活。我呆过的两个公司均未采用此客户端。
elasticsearch-rest-high-level-client
这是官方推荐的客户端,支持最新的es,其实使用起来也很便利,因为是官方推荐所以在特性的操作上肯定优于前者。而且该客户端与TransportClient不同,不存在并发瓶颈的问题,官方首推,必为精品!
搭建自己的迷你搜索系统
引入es相关依赖,除此之外需引入springboot-web依赖、jackson依赖以及lombok依赖等。
<properties>
<es.version>7.3.2es.version>
properties>
<dependency>
<groupId>org.elasticsearch.clientgroupId>
<artifactId>elasticsearch-rest-high-level-clientartifactId>
<version>${es.version}version>
<exclusions>
<exclusion>
<groupId>org.elasticsearch.clientgroupId>
<artifactId>elasticsearch-rest-clientartifactId>
exclusion>
<exclusion>
<groupId>org.elasticsearchgroupId>
<artifactId>elasticsearchartifactId>
exclusion>
exclusions>
dependency>
<dependency>
<groupId>org.elasticsearchgroupId>
<artifactId>elasticsearchartifactId>
<version>${es.version}version>
dependency>
<dependency>
<groupId>org.elasticsearch.clientgroupId>
<artifactId>elasticsearch-rest-clientartifactId>
<version>${es.version}version>
dependency>
es配置文件es-config.properties
es.host=localhost
es.port=9200
es.token=es-token
es.charset=UTF-8
es.scheme=http
es.client.connectTimeOut=5000
es.client.socketTimeout=15000
封装RestHighLevelClient
@Configuration
@PropertySource("classpath:es-config.properties")
public class RestHighLevelClientConfig {
@Value("${es.host}")
private String host;
@Value("${es.port}")
private int port;
@Value("${es.scheme}")
private String scheme;
@Value("${es.token}")
private String token;
@Value("${es.charset}")
private String charSet;
@Value("${es.client.connectTimeOut}")
private int connectTimeOut;
@Value("${es.client.socketTimeout}")
private int socketTimeout;
@Bean
public RestClientBuilder restClientBuilder() {
RestClientBuilder restClientBuilder = RestClient.builder(
new HttpHost(host, port, scheme)
);
Header[] defaultHeaders = new Header[]{
new BasicHeader("Accept", "*/*"),
new BasicHeader("Charset", charSet),
//设置token 是为了安全 网关可以验证token来决定是否发起请求 我们这里只做象征性配置
new BasicHeader(
"E_TOKEN", token)
};
restClientBuilder.setDefaultHeaders(defaultHeaders);
restClientBuilder.setFailureListener(new RestClient.FailureListener(){
@Override
public void onFailure(Node node) {
System.out.println("监听某个es节点失败");
}
});
restClientBuilder.setRequestConfigCallback(builder ->
builder.setConnectTimeout(connectTimeOut).setSocketTimeout(socketTimeout));
return restClientBuilder;
}
@Bean
public RestHighLevelClient restHighLevelClient(RestClientBuilder restClientBuilder) {
return new RestHighLevelClient(restClientBuilder);
}
}
封装es常用操作
@Service
public class RestHighLevelClientService {
@Autowired
private RestHighLevelClient client;
@Autowired
private ObjectMapper mapper;
/**
* 创建索引
* @param indexName
* @param settings
* @param mapping
* @return
* @throws IOException
*/
public CreateIndexResponse createIndex(String indexName, String settings, String mapping) throws IOException {
CreateIndexRequest request = new CreateIndexRequest(indexName);
if (null != settings && !"".equals(settings)) {
request.settings(settings, XContentType.JSON);
}
if (null != mapping && !"".equals(mapping)) {
request.mapping(mapping, XContentType.JSON);
}
return client.indices().create(request, RequestOptions.DEFAULT);
}
/**
* 判断 index 是否存在
*/
public boolean indexExists(String indexName) throws IOException {
GetIndexRequest request = new GetIndexRequest(indexName);
return client.indices().exists(request, RequestOptions.DEFAULT);
}
/**
* 搜索
*/
public SearchResponse search(String field, String key, String rangeField, String
from, String to,String termField, String termVal,
String ... indexNames) throws IOException{
SearchRequest request = new SearchRequest(indexNames);
SearchSourceBuilder builder = new SearchSourceBuilder();
BoolQueryBuilder boolQueryBuilder = new BoolQueryBuilder();
boolQueryBuilder.must(new MatchQueryBuilder(field, key)).must(new RangeQueryBuilder(rangeField).from(from).to(to)).must(new TermQueryBuilder(termField, termVal));
builder.query(boolQueryBuilder);
request.source(builder);
log.info("[搜索语句为:{}]",request.source().toString());
return client.search(request, RequestOptions.DEFAULT);
}
/**
* 批量导入
* @param indexName
* @param isAutoId 使用自动id 还是使用传入对象的id
* @param source
* @return
* @throws IOException
*/
public BulkResponse importAll(String indexName, boolean isAutoId, String source) throws IOException{
if (0 == source.length()){
//todo 抛出异常 导入数据为空
}
BulkRequest request = new BulkRequest();
JsonNode jsonNode = mapper.readTree(source);
if (jsonNode.isArray()) {
for (JsonNode node : jsonNode) {
if (isAutoId) {
request.add(new IndexRequest(indexName).source(node.asText(), XContentType.JSON));
} else {
request.add(new IndexRequest(indexName)
.id(node.get("id").asText())
.source(node.asText(), XContentType.JSON));
}
}
}
return client.bulk(request, RequestOptions.DEFAULT);
}
创建索引,这里的settings是设置索引是否设置复制节点、设置分片个数,mappings就和数据库中的表结构一样,用来指定各个字段的类型,同时也可以设置字段是否分词(我们这里使用ik中文分词器)、采用什么分词方式。
@Test
public void createIdx() throws IOException {
String settings = "" +
" {\n" +
" \"number_of_shards\" : \"2\",\n" +
" \"number_of_replicas\" : \"0\"\n" +
" }";
String mappings = "" +
"{\n" +
" \"properties\": {\n" +
" \"itemId\" : {\n" +
" \"type\": \"keyword\",\n" +
" \"ignore_above\": 64\n" +
" },\n" +
" \"urlId\" : {\n" +
" \"type\": \"keyword\",\n" +
" \"ignore_above\": 64\n" +
" },\n" +
" \"sellAddress\" : {\n" +
" \"type\": \"text\",\n" +
" \"analyzer\": \"ik_max_word\", \n" +
" \"search_analyzer\": \"ik_smart\",\n" +
" \"fields\": {\n" +
" \"keyword\" : {\"ignore_above\" : 256, \"type\" : \"keyword\"}\n" +
" }\n" +
" },\n" +
" \"courierFee\" : {\n" +
" \"type\": \"text\n" +
" },\n" +
" \"promotions\" : {\n" +
" \"type\": \"text\",\n" +
" \"analyzer\": \"ik_max_word\", \n" +
" \"search_analyzer\": \"ik_smart\",\n" +
" \"fields\": {\n" +
" \"keyword\" : {\"ignore_above\" : 256, \"type\" : \"keyword\"}\n" +
" }\n" +
" },\n" +
" \"originalPrice\" : {\n" +
" \"type\": \"keyword\",\n" +
" \"ignore_above\": 64\n" +
" },\n" +
" \"startTime\" : {\n" +
" \"type\": \"date\",\n" +
" \"format\": \"yyyy-MM-dd HH:mm:ss\"\n" +
" },\n" +
" \"endTime\" : {\n" +
" \"type\": \"date\",\n" +
" \"format\": \"yyyy-MM-dd HH:mm:ss\"\n" +
" },\n" +
" \"title\" : {\n" +
" \"type\": \"text\",\n" +
" \"analyzer\": \"ik_max_word\", \n" +
" \"search_analyzer\": \"ik_smart\",\n" +
" \"fields\": {\n" +
" \"keyword\" : {\"ignore_above\" : 256, \"type\" : \"keyword\"}\n" +
" }\n" +
" },\n" +
" \"serviceGuarantee\" : {\n" +
" \"type\": \"text\",\n" +
" \"analyzer\": \"ik_max_word\", \n" +
" \"search_analyzer\": \"ik_smart\",\n" +
" \"fields\": {\n" +
" \"keyword\" : {\"ignore_above\" : 256, \"type\" : \"keyword\"}\n" +
" }\n" +
" },\n" +
" \"venue\" : {\n" +
" \"type\": \"text\",\n" +
" \"analyzer\": \"ik_max_word\", \n" +
" \"search_analyzer\": \"ik_smart\",\n" +
" \"fields\": {\n" +
" \"keyword\" : {\"ignore_above\" : 256, \"type\" : \"keyword\"}\n" +
" }\n" +
" },\n" +
" \"currentPrice\" : {\n" +
" \"type\": \"keyword\",\n" +
" \"ignore_above\": 64\n" +
" }\n" +
" }\n" +
"}";
clientService.createIndex("idx_item", settings, mappings);
}
分词技巧:
我们向es导入十万条淘宝双11活动数据作为我们的样本数据,数据结构如下所示
{
"_id": "https://detail.tmall.com/item.htm?id=538528948719\u0026skuId=3216546934499",
"卖家地址": "上海",
"快递费": "运费: 0.00元",
"优惠活动": "满199减10,满299减30,满499减60,可跨店",
"商品ID": "538528948719",
"原价": "2290.00",
"活动开始时间": "2016-11-11 00:00:00",
"活动结束时间": "2016-11-11 23:59:59",
"标题": "【天猫海外直营】 ReFa CARAT RAY 黎珐 双球滚轮波光美容仪",
"服务保障": "正品保证;赠运费险;极速退款;七天退换",
"会场": "进口尖货",
"现价": "1950.00"
}
调用上面封装的批量导入方法进行导入
@Test
public void importAll() throws IOException {
clientService.importAll("idx_item", true, itemService.getItemsJson());
}
我们调用封装的搜索方法进行搜索,搜索产地为武汉、价格在11-149之间的相关酒产品,这与我们淘宝中设置筛选条件搜索商品操作一致。
@Test
public void search() throws IOException {
SearchResponse search = clientService.search("title", "酒", "currentPrice",
"11", "149", "sellAddress", "武汉");
SearchHits hits = search.getHits();
SearchHit[] hits1 = hits.getHits();
for (SearchHit documentFields : hits1) {
System.out.println( documentFields.getSourceAsString());
}
}
我们得到以下搜索结果,其中_score为某一项的得分,商品就是按照它来排序。
{
"_index": "idx_item",
"_type": "_doc",
"_id": "Rw3G7HEBDGgXwwHKFPCb",
"_score": 10.995819,
"_source": {
"itemId": "525033055044",
"urlId": "https://detail.tmall.com/item.htm?id=525033055044&skuId=def",
"sellAddress": "湖北武汉",
"courierFee": "快递: 0.00",
"promotions": "满199减10,满299减30,满499减60,可跨店",
"originalPrice": "3768.00"
,
"startTime": "2016-11-01 00:00:00",
"endTime": "2016-11-11 23:59:59",
"title": "酒嗨酒 西班牙原瓶原装进口红酒蒙德干红葡萄酒6只装整箱送酒具",
"serviceGuarantee": "破损包退;正品保证;公益宝贝;不支持7天退换;极速退款",
"venue": "食品主会场",
"currentPrice": "151.00"
}
}
扩展性思考
商品搜索权重扩展,我们可以利用多种收费方式智能为不同店家提供增加权重,增加曝光度适应自身的营销策略。同时我们经常发现淘宝搜索前列的商品许多为我们之前查看过的商品,这是通过记录用户行为,跑模型等方式智能为这些商品增加权重。
分词扩展,也许因为某些商品的特殊性,我们可以自定义扩展分词字典,更精准、人性化的搜索。
高亮功能,es提供highlight高亮功能,我们在淘宝上看到的商品展示中对搜索关键字高亮,就是通过这种方式来实现。
项目地址
https://github.com/Motianshi/alldemo/tree/master/demo-search
END
Java面试题专栏
【71期】面试官:对并发熟悉吗?谈谈你对Java中常用的几种线程池的理解
【72期】面试官:对并发熟悉吗?说一下synchronized与Lock的区别与使用
【73期】面试官:Spring 和 Spring Boot 的区别是什么?
【74期】面试官:对多线程熟悉吗,来谈谈线程池的好处?
【75期】面试官:说说Redis的过期键删除策略吧!(高频)
【76期】面试官问:List如何一边遍历,一边删除?
【77期】这一道面试题就考验了你对Java的理解程度
【78期】别找了,Java集合面试问题这里帮你总结好了!
【79期】别找了,回答Spring中Bean的生命周期,这里帮你总结好了!
【80期】说出Java创建线程的三种方式及对比
我知道你 “在看”