这是这个网络实现关节点检测的关键所在了,上面经过网络推理,得到骨点热力图以及骨点之间的亲和区域,对热力图采取非极大值抑制得到一系列候选骨点。由于多人或者错误检测,对于每一类型的骨点会存在多个候选骨点。这些候选骨点之间的连接构成二分图,每两个骨点之间的连接置信度通过线积分计算得到。为二分图找到最优的稀疏性是NP-Hard 问题。
优化该二分图即在所有边中选择一组边使得最终二分图的总权重最大,所以目标函数可写为:
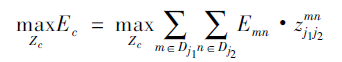
约束条件:
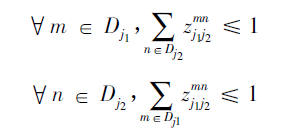
- 其中Ec为二分图优化之后肢体c的权重,我们要取其中总权重之和最大的;
问题分解与简化
为扩展到多人所有骨点的最优化问题,即定义Z为K 维匹配问题,这是一个NP-hard问题,为了提高最优化效率,如图所示,本文采用两种方法降低二分图优化算法的复杂度。
- 首先,如图所示,剔除跨骨点之间的连接构成稀疏二分图,代替全连接二分图;
- 然后根据肢体将稀疏后的二分图拆解得到图所示的多个简化二分图。
因此,整体优化问题转化为对各个简化后的二分图进行最优化。而最优化的目标函数为所有简化二分图的权重之和达到最大:
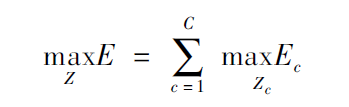
优化之后将各个简化二分图中共同的骨点进行整合得到最终多人人体姿态估计。这样做的优点是将NP-hard问题转化为多个较容易求解的二分图最优化,可以有效逼近全局最优解,同时降低算法复杂度,提高算法的运行效率,达到实时多人姿态估计的目的。
我对这个算法的整体思路做了个笔记,字太丑了orz,大家别见怪haha,道理讲明白理解清楚就行了。
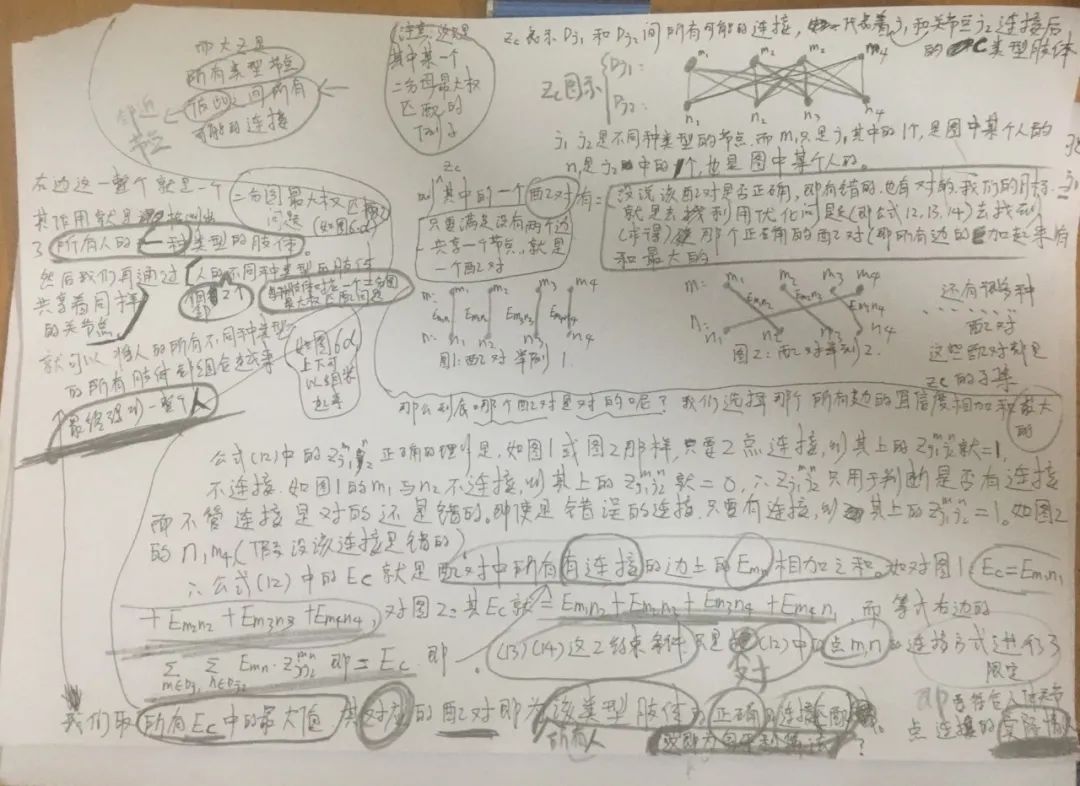
Fig.13: 站长的算法笔记(求各位大佬斧正)

站长的实验结果和分析
实验所使用的显卡为NVIDIA TITAN XP,CPU为Intel i7-6900K。图像大小为1920× 1080,通过下采样方法额外获得1280 × 720 和720 × 480 两个低分辨率的视频。
首先分析运行效率与人数的关系,在相同视频流和相同分辨情况下,计算自顶向下与自底向上运行时间与人数关系,计算结果如图14所示。由图可知,自顶向下随着人数的增加耗时几乎呈线性增加,而自底向上的运行耗时几乎不随人数增加而递增。卷积神经网络预测关节点的耗时也几乎不随人数增加而增加。因此我所使用的自底向上算法的运行效率不受行人数量的影响,对人数不确定的情况依然可以实时进行多人姿态估计。
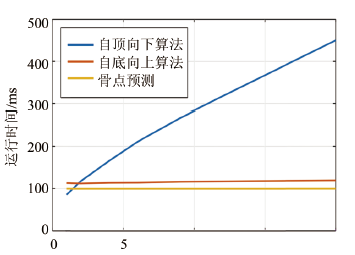
Fig.14: 实验的运行耗时
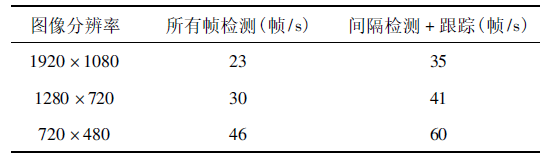
最后,对三种分辨率视频采用两种不同方法进行耗时分析,结果如表所示,随着分辨率的降低,处理速度越来越快。若对视频所有帧都进行关节点检测,在最高分辨率情况下每秒可处理23帧,人眼感觉不到卡顿,基本达到实时。如果采用间隔检测结合跟踪,帧率可提高十几帧,完全达到实时要求。
站长测试(使用自己乱糟糟的图片才有说服力哈)
以下是我采用深度学习算法(Openpose)最终的实验结果(效果果然杠杠的):

Fig.15: 一次旅游haha
总体而言,效果还算很nice的,关节点都检测出来了,Great!(羞涩的我)
能阅读到这里,说明你也是个踏踏实实的做研究的人了。此时,我们娱乐时间到了,让我们来段测试视频放松放松下哈:

总结











