
【导语】:今天我们来聊聊小朋友和大朋友们都爱不释手的乐高,Python技术部分请看第四部分。公众号后台,回复关键字“乐高”获取完整数据。
Show me data,用数据说话
今天我们聊一聊 乐高
点击下方视频,先睹为快:
六一儿童节马上要到了,过节的不仅仅是儿童,还有很多不想长大的成年人。然而,儿童游乐场不好意思去跟小朋友抢,幼儿园里已经没有容身之地。这时,玩具可能是最后一件能让成年人过把瘾的方式了。
根据去年的天猫双11数据统计:双11玩具/童车/益智/积木品牌TOP20榜单中,在玩具领域,乐高位居首位,占据了1/5的市场份额,销售额超过1138万元,销量达14712件,妥妥的玩具领域大佬。今天我们就用数据来聊一聊,小朋友和大朋友们都爱不释手的乐高。

老少皆宜 大IP联名
玩具居然可以这么玩?!
1932年,乐高公司在丹麦成立。商标“LEGO”是来自丹麦语“LEg GOdt”,意为“play well”。

在10年前,乐高真是家庭水准的体现,小时候能有个乐高玩具,应该是很多人的梦想,但是长大了发现,现在拥有乐高玩具,也是梦想。有多少人在疫情期间想在淘宝买乐高玩具,也来挑战下千年隼75192,证明自己不再是手残党。
外国的乐高狂热粉丝用乐高拼了一辆能开的跑车,真的可以以每小时15公里的速度前进,这也算是人类创造能力的体现,本身乐高提倡的就是自由组装,play well。创造力才是他们的核心,这也就证明了乐高从小孩玩具到创造力检测仪的进化。
如今的乐高就像玩具界的Supreme,时不时就弄出套联名款,即使你不是乐高粉丝,也忍不住赶紧送上钱包。
之前,乐高就和暴雪合作推出了《乐高守望先锋系列》。

《乐高星球大战系列》,至今全球已经热销超过两千万套。其中“豪华千年隼”,更是被称为“乐高史上最大套装”。

从DC的蝙蝠侠到漫威的钢铁侠,热门电影的热度“能蹭就蹭”。

如果你是《哈利波特》迷,等不到送入学通知书的猫头鹰?没关系,乐高让你直接把霍格沃茨买回家。

都是哪些人在玩乐高?
那么都是哪些人在玩乐高呢?我们用Python获取“乐高中国”最新的三条微博(5.06日、5.08日、5.15日发布)后的评论和粉丝信息,分析粉丝画像,数据共4815条。
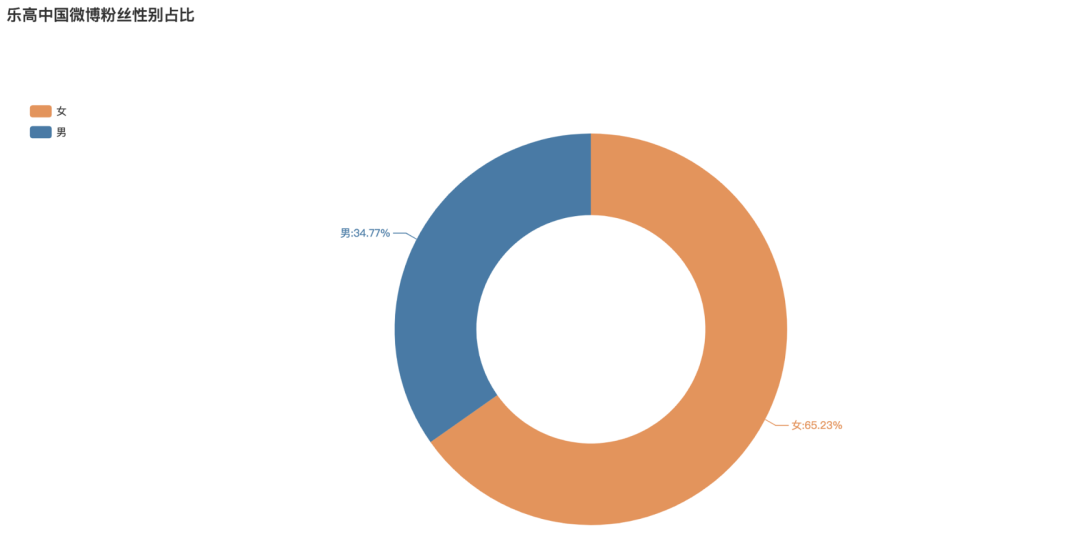
粉丝性别占比
首先看到乐高中国的微博粉丝性别占比,从数据可以看到,女性粉丝远超男性,占比高达到65.23%,男性占比34.77%
粉丝数量地区分布
都是哪些地区的人最爱玩乐高呢?
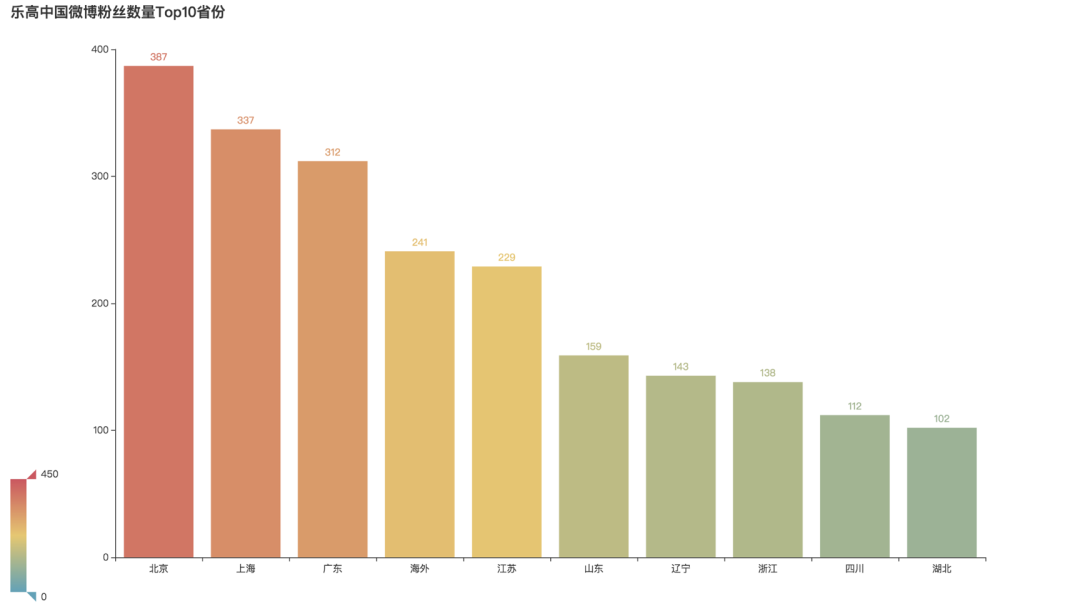
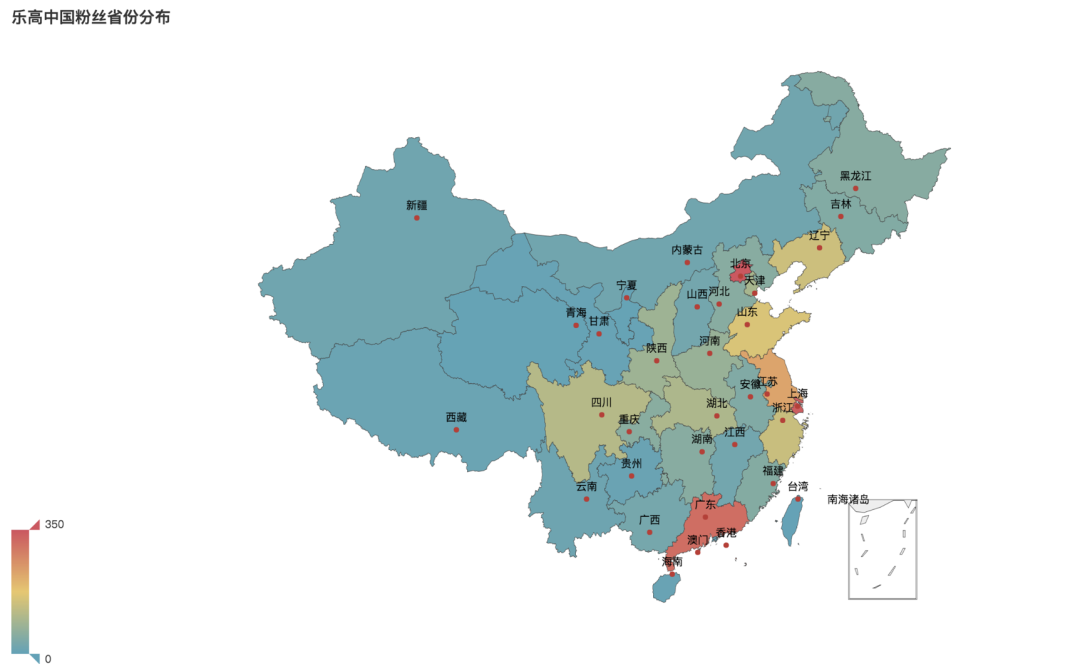
从图中可以看到,北上广位居前三,海外的粉丝也不少,位居第四。之后就是江苏、山东分别为第五和第六。
粉丝年龄分布
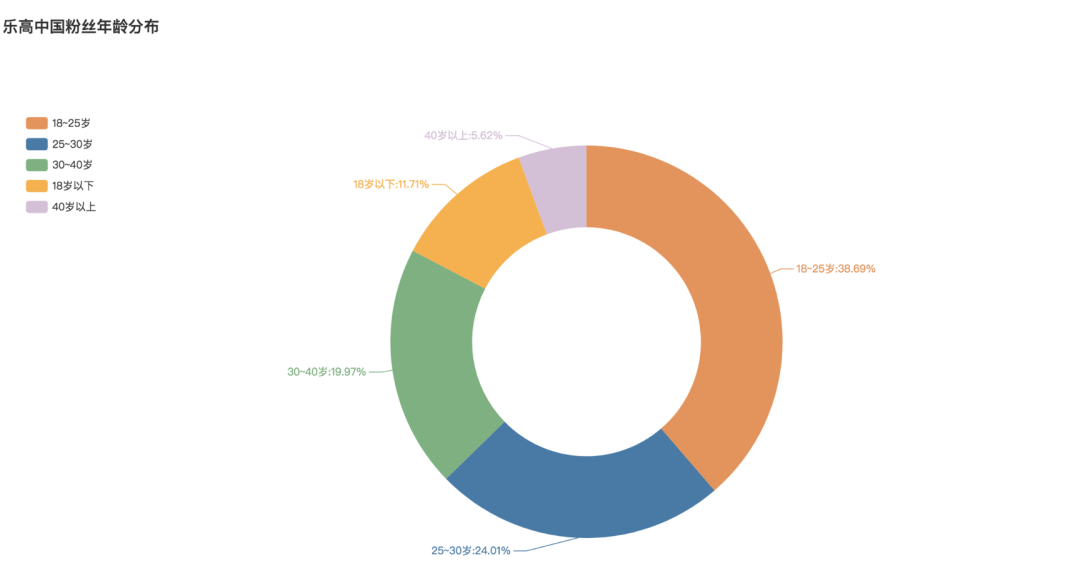
18-25岁的粉丝最多占比高达38.69%,其次就是25-30岁的了,占比为24.01%,30-40岁的占比19.97%。总体来说,乐高在国内的粉丝还是比较年轻化的,既有喜欢玩乐高的年轻玩家,也有热衷给孩子买乐高玩的年轻父母。
微博评论词云

下面我们看到“乐高中国”微博下面的评论词云,可以看到提到最多的就是"乐高"。同时"齐天大圣"、"忍者神龟"等都是被提及最多的热门款。
哪款乐高卖的最好?
下面我们用Python进一步分析乐高在天猫和淘宝全网的数据,我们共搜集整理了乐高在淘宝的商品数据,一共4404条商品信息。以及天猫乐高旗舰店一共392条的数据。
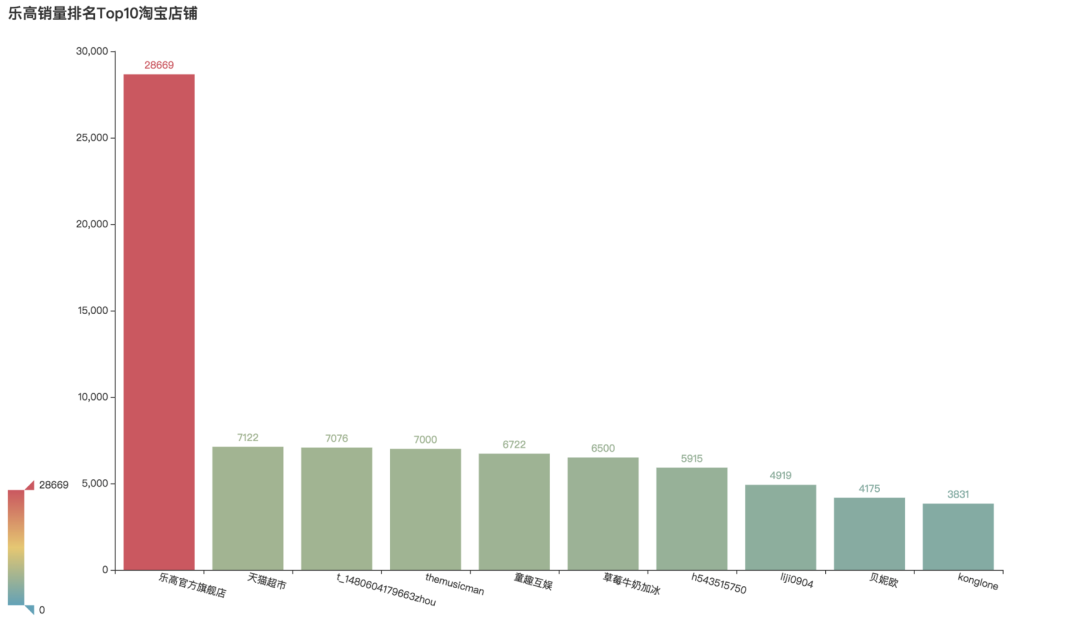
乐高销量TOP10店铺
首先看到淘宝全网乐高销量店铺的排名。不用说,乐高官方旗舰店是妥妥的第一位,其次天猫超市的位居第二。
乐高产地排名TOP10
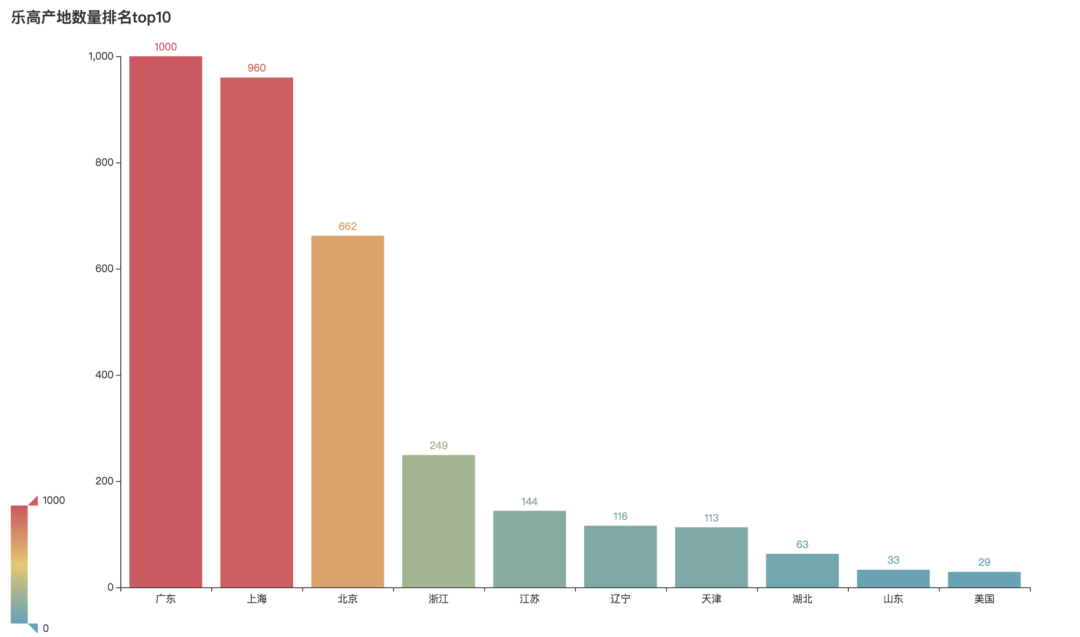
乐高产地方面,我们可以看到,广东和上海是大头,位居第一和第二。北京位居第三。
不同价格区间商品数量
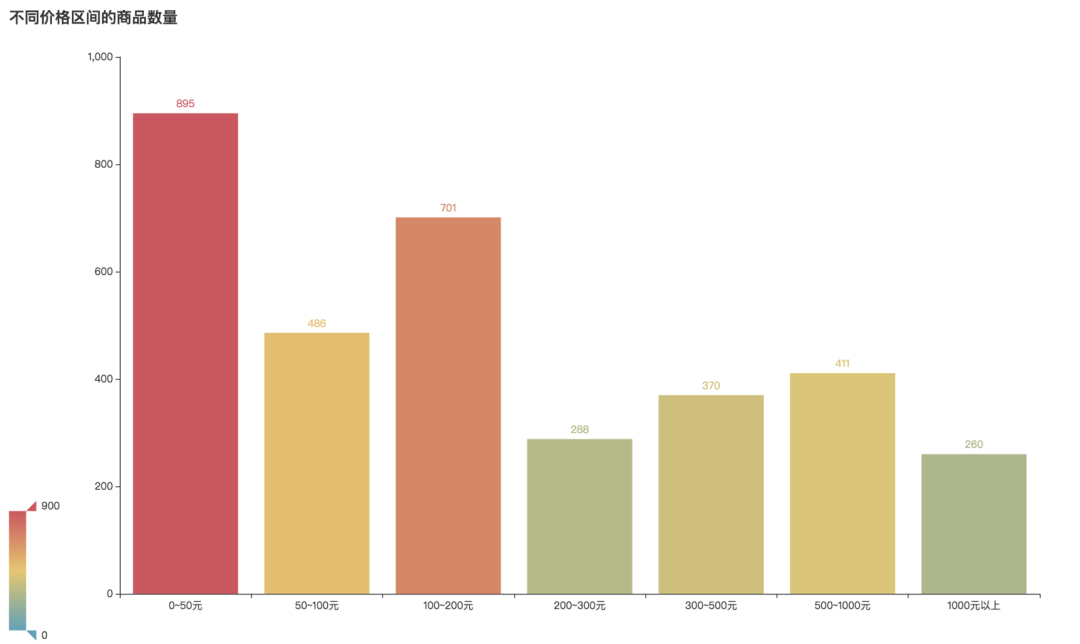
乐高的定价如何呢?我们可以看到0-50元的乐高商品是最多的,达到895件。其次100-200元的也不少,以701件位居第二。1000元以上的资深玩家款最少,为260件。
不同价格区间的销售额
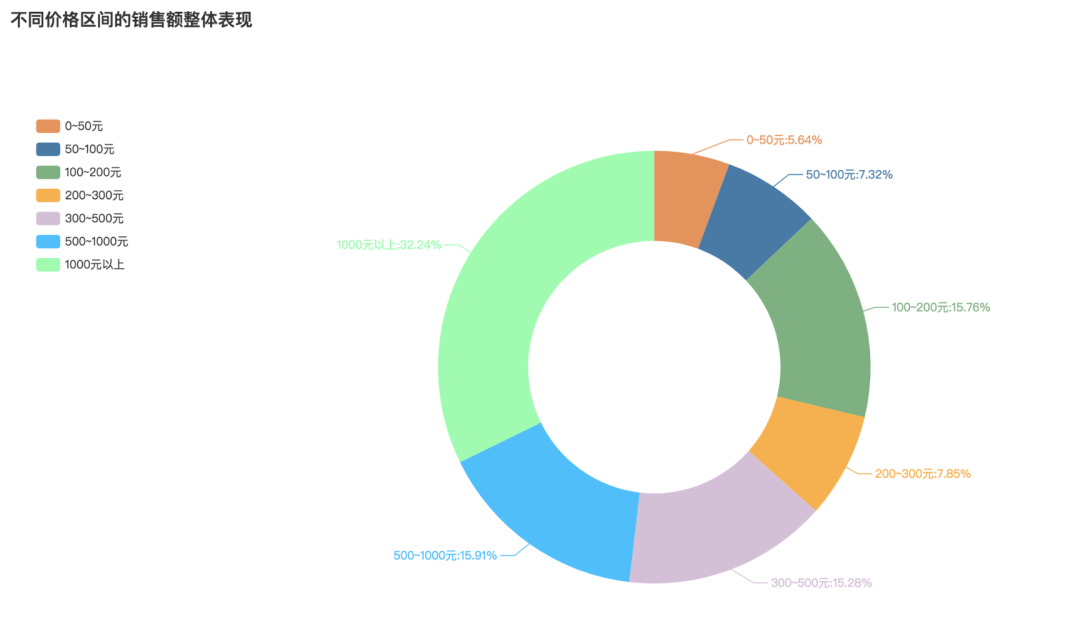
这里就比较有意思了,1000元以上的销售额占比达到32.24%,果然是人民币玩家的专选。其次500-1000元的商品销售额占比15.91%。紧接着较为平价的100-200元款,销售额占比15.76%。
淘宝乐高商品标题词云
下面看到淘宝乐高相关标题的词云,"乐高"、"玩具"、"积木"都是提及最多的关键词。同时"益智"、"系列"、"正品"等词也是标题中常有的词。
我们再具体看看哪款乐高产品卖得最好。
乐高旗舰店商品销量TOP10
让我们再看到乐高旗舰店的数据:
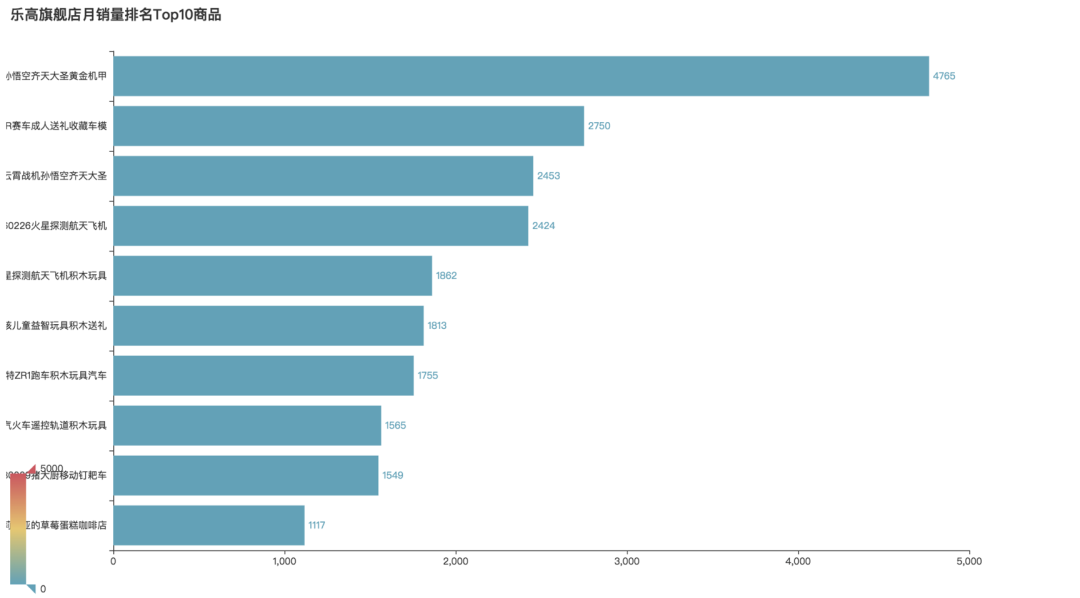
我们可以看到,孙悟空齐天大圣黄金机甲这款,以月销量4765件位居榜首。

其次第二位是R赛车成人送礼收藏车模,月销量2750件。然后云霄战机孙悟空齐天大圣位居第三,月销量达到2453件。
不同价格区间商品数量
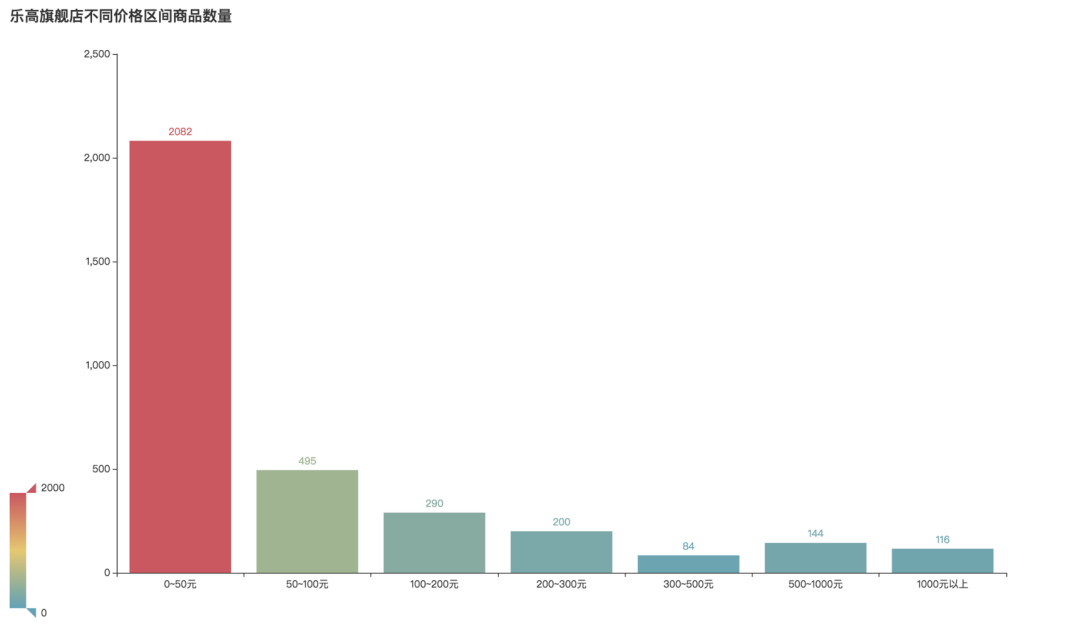
在商品价格区间方面,可以看到数量最多的还是0-50元的平价款,共2082件商品,远远高于其他价格区间。其次50-100元的商品有495件。
不同价格区间销售额
最后,我们再看到不同价格区间的销售额:
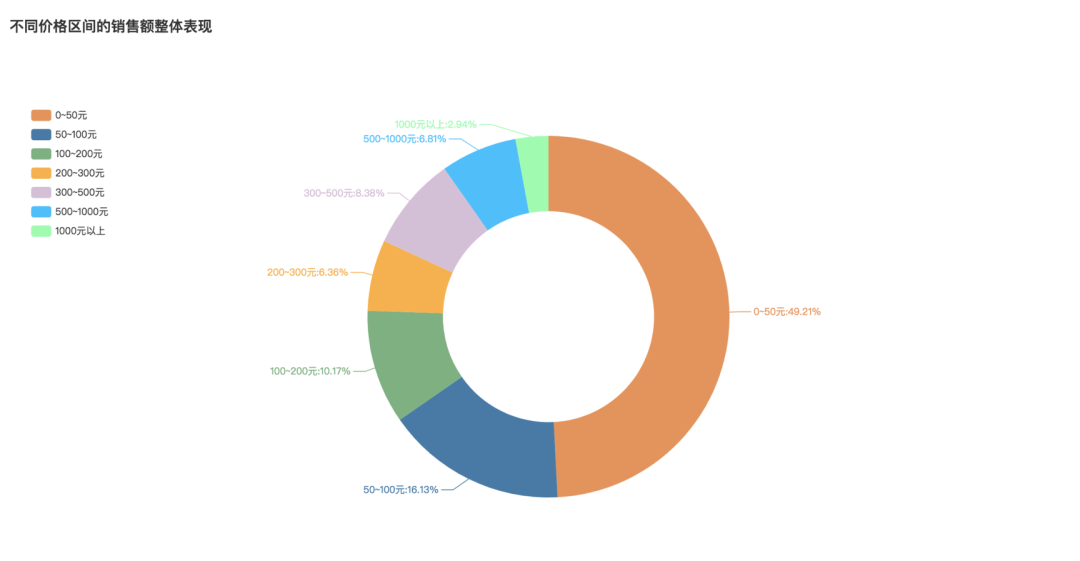
这里与淘宝全网数据不同,销售额占比最高的是0-50元的商品,占比49.21%。其次是50-100元,占比16.13%。而1000元以上的销售额占比最少,仅为2.94%。这也说明,在购买1000元以上的收藏款时,大家更倾向于在其他渠道购买,而不是官方旗舰店。
乐高旗舰店商品标题词云

我们再看看在乐高旗舰店,商品标题都有什么特点。可以看到标题中,"积木"、"玩具"、"XX系列"都被常常提到。同时"送礼"、"创意"、"益智"、"收藏"等也常出现。
带你用Python分析 乐高淘宝数据
我们使用Python分别获取了淘宝上的乐高商品数据、乐高旗舰店的店铺商品销售数据和微博乐高中国的评论和粉丝数据,进行了数据分析分析。此处展示淘宝商品分析部分代码。按照常规数据分析流程进行:
公众号后台,回复关键字“乐高”获取完整数据。
01 数据读入
首先导入所需的库,并读入采集的数据集。其中pandas用于数据整理、jieba用于分词、pyecharts和stylecloud用于绘制可视化图形。
# 导入包
import pandas as pd
import time
import jieba
from pyecharts.charts import Bar, Line, Pie, Map, Page
from pyecharts import options as opts
from pyecharts.globals import SymbolType
import stylecloud
获取到的数据集如下所示:
# 读入数据
df_tb = pd.read_excel('../data/乐高淘宝数据.xlsx')
df_tb.head()
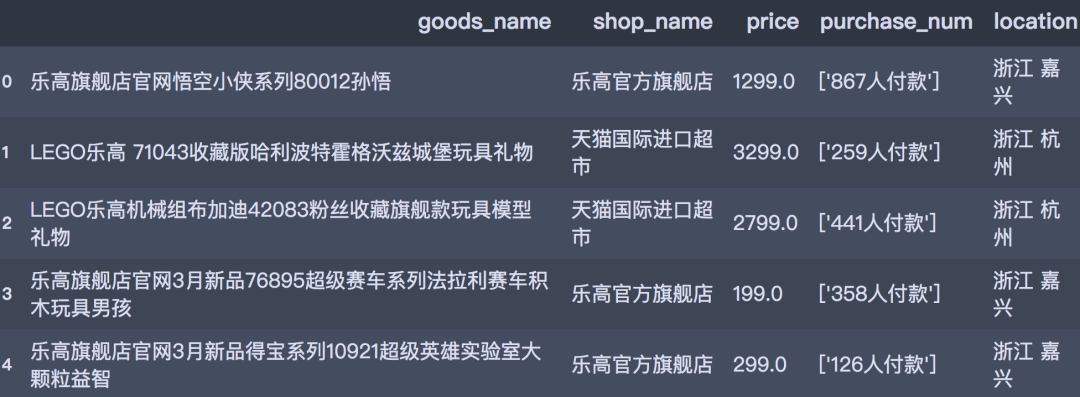
查看一下数据框的大小,可以看到一共有4403个样本。
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 4404 entries, 0 to 4403
Data columns (total 5 columns):
goods_name 4404 non-null object
shop_name 4404 non-null object
price 4404 non-null float64
purchase_num 4404 non-null object
location 4404 non-null object
dtypes: float64(1), object(4)
memory usage: 172.1+ KB
02 数据处理
此处我们对各个字段进行以下处理以方便后续的数据分析工作,经过去重之后一共有3411个样本:
- 计算销售额 = price * purchase_num
# 去除重复值
df_tb.drop_duplicates(inplace=True)
# 删除购买人数为空的记录
df_tb = df_tb[df_tb['purchase_num'].str.contains('人付款')]
# 重置索引
df_tb = df_tb.reset_index(drop=True)
df_tb.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 3411 entries, 0 to 3410
Data columns (total 5 columns):
goods_name 3411 non-null object
shop_name 3411 non-null object
price 3411 non-null float64
purchase_num 3411 non-null object
location 3411 non-null object
dtypes: float64(1), object(4)
memory usage: 133.3+ KB
# purchase_num处理
df_tb['purchase_num'] = df_tb['purchase_num'].str.extract('(\d+)').astype('int')
# 计算销售额
df_tb['sales_volume'] = df_tb['price'] * df_tb['purchase_num']
# location
df_tb['province'] = df_tb['location'].str.split(' ').str[0]
df_tb.head()
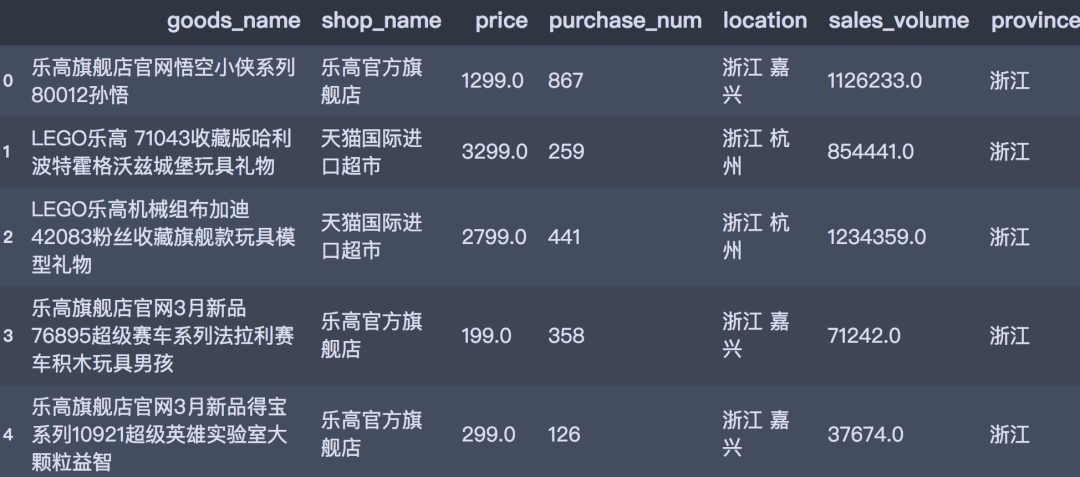
03 数据可视化
数据可视化部分主要对以下的信息进行汇总和可视化分析,分析维度和使用图形如下:
乐高销量排名Top10淘宝店铺 - 条形图
shop_top10 = df_tb.groupby('shop_name')['purchase_num'].sum().sort_values(ascending=False).head(10)
# 条形图
bar1 = Bar(init_opts=opts.InitOpts(width='1350px', height='750px'))
bar1.add_xaxis(shop_top10.index.tolist())
bar1.add_yaxis('', shop_top10.values.tolist())
bar1.set_global_opts(title_opts=opts.TitleOpts(title='乐高销量排名Top10淘宝店铺'),
xaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(rotate=-15)),
visualmap_opts=opts.VisualMapOpts(max_=28669)
)
bar1.render()
乐高店铺产地数量排名top10
province_top10 = df_tb.province.value_counts()[:10]
bar2 = Bar(init_opts=opts.InitOpts(width='1350px', height='750px'))
bar2.add_xaxis(province_top10.index.tolist())
bar2.add_yaxis('', province_top10.values.tolist())
bar2.set_global_opts(title_opts=opts.TitleOpts(title='乐高店铺产地数量排名top10'),
visualmap_opts=opts.VisualMapOpts(max_=1000)
)
bar2.render()
国内各省份乐高销量分布图
province_num = df_tb.groupby('province')['purchase_num'].sum().sort_values(ascending=False)
# 地图
map1 = Map(init_opts=opts.InitOpts(width='1350px', height='750px'))
map1.add("", [list(z) for z in zip(province_num.index.tolist(), province_num.values.tolist())],
maptype='china'
)
map1.set_global_opts(title_opts=opts.TitleOpts(title='国内各产地乐高销量分布图'),
visualmap_opts=opts.VisualMapOpts(max_=172277),
)
map1.render()
天猫乐高价格分布
# 分箱
cut_bins
= [0,50,100,200,300,500,1000,8888]
cut_labels = ['0~50元', '50~100元', '100~200元', '200~300元', '300~500元', '500~1000元', '1000元以上']
price_cut = pd.cut(df_tb['price'], bins=cut_bins, labels=cut_labels)
price_num = price_cut.value_counts()
# 饼图
bar3 = Bar(init_opts=opts.InitOpts(width='1350px', height='750px'))
bar3.add_xaxis(['0~50元', '50~100元', '100~200元', '200~300元', '300~500元', '500~1000元', '1000元以上'])
bar3.add_yaxis('', [895, 486, 701, 288, 370, 411, 260])
bar3.set_global_opts(title_opts=opts.TitleOpts(title='不同价格区间的商品数量'),
visualmap_opts=opts.VisualMapOpts(max_=900))
bar3.render()
不同价格区间的销售额整体表现
# 添加列
df_tb['price_cut'] = price_cut
cut_purchase = df_tb.groupby('price_cut')['sales_volume'].sum()
# 数据对
data_pair = [list(z) for z in zip(cut_purchase.index.tolist(), cut_purchase.values.tolist())]
# 绘制饼图
pie1 = Pie(init_opts=opts.InitOpts(width='1350px', height='750px'))
pie1.add('', data_pair, radius=['35%', '60%'])
pie1.set_global_opts(title_opts=opts.TitleOpts(title='不同价格区间的销售额整体表现'),
legend_opts=opts.LegendOpts(orient='vertical', pos_top='15%', pos_left='2%'))
pie1.set_series_opts(label_opts=opts.LabelOpts(formatter="{b}:{d}%"))
pie1.set_colors(['#EF9050', '#3B7BA9', '#6FB27C', '#FFAF34', '#D8BFD8', '#00BFFF', '#7FFFAA'])
pie1.render()
商品标题词云图
def get_cut_words(content_series):
"""
功能:传入Seires,获取分词后的结果,返回字符串。
"""
# 读入停用词表
stop_words = []
# 读入stop_words文件
with open(r"stop_words.txt", 'r', encoding='utf-8') as f:
lines = f.readlines()
for line in lines:
stop_words.append(line.strip())
# 添加关键词
my_words = ['乐高', '悟空小侠', '大颗粒', '小颗粒']
for i in my_words:
jieba.add_word(i)
# 分词
word_num = jieba.lcut(content_series.str.cat(sep='。'), cut_all=False)
# 条件筛选
word_num_selected = [i for i in word_num if i not in stop_words and len(i)>=2]
return ' '.join(word_num_selected)
# 生成分词str
text = get_cut_words(content_series=df_tb['goods_name'])
# 绘制词云图
stylecloud.gen_stylecloud(text, # 绘图文本
collocations=False,
font_path=r'C:\Windows\Fonts\msyh.ttc', # 电脑字体路径
icon_name='fas fa-heart'
, # 绘图形状
size=768, # 绘图尺寸
output_name='淘宝乐高标题词云图.png' # 输出png文件
)
参考文献:
乐高是如何起死回生的?
https://36kr.com/p/5211421
成年人的玩具能有多好玩儿?
https://zhuanlan.zhihu.com/p/56386424
本文出品:CDA数据分析师(ID: cdacdacda)
(点击下方图片阅读)
仅拍125个视频就成为千万级网红?李子柒的视频都在拍些什么?
喜欢本篇内容请点个“在看”哦!❤️









