转债也能做因子模型吗?答案一定是肯定的,因子模型本身经过国内外多年实践早已与“难于实现”没有关系,而转债就算有一定特殊性,也不应该做不了。疑惑可能更多来自于这些方面:1、转债本身是一个衍生品,价格走势很多时候“身不由己”,但如果再分别做正股、期权、债底的模型,则很难再拼回到转债上去——这个问题最好解决,不把转债的价格波动作拆分、拿它直接当作一个普通的价格变动就好,至于转债特性(如溢价、条款等),可以通过定制一些因子来反映;2、个券少,容纳不下太多因子,效果不好与过拟合之间的界限太近——这个问题能解决,但需要在实践中重视。不过,好在至少2018年之后,个券样本少的问题已经明显缓解。事实上,如果是15年那种个券数量,转债肯定没办法做因子回归;3、其实更多的疑问还是来自:即便能做,有用吗?这里要看投资者用它来做什么。一个常见的误区是想用一个工具解决所有的问题——至少在转债上行不通。我们的目标也不在此,这里,我们更需要的是一个能既方便也稍有精确性地去描述市场的工具。一个原因是,随着个券增多,我们已经比较难以像更早期那样,只是看一看指数和自选股就能准确地描述市场了,而描述市场又是一项核心能力——事实上,投资者之间在预测能力上不易拉开差距,长期稳定水平明显高于50%的话基本要靠样本足够小,而描述能力却能真正拉开差距。下面我们来介绍一个简单的实现方式(仍基于Python)。在此我们不打算对因子模型和
python做过于基础的介绍,下面用到的也都非常简单易懂,而是着重介绍因为是转债,而做的特殊处理。这里我们用的基本模型仍是最简单、经典的形式,包括单因子测试和多因子回归两种形式。其中,多因子回归的模式下: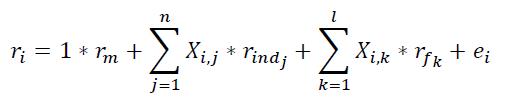
其中:1、等式左边是转债i的收益率(价格涨跌幅);2、右边四项各自代表市场风险、行业风险(Xij表示转债i在行业j上的暴露,若属于该行业则为1,否则为0,r_indj则是该行业相对收益率)、风格风险(Xik表示转债i在风格因子k上的暴露,r_fk则是该因子的收益率)和残差项。而我们在做单因子测试时,模式也与上式基本一致,保留市场风险因子、行业风险因子,同时只留一个待测试因子(相当于l=1)即可。自然,最后的回归是最简单的,主要的精力和时间可能都花在了前面的数据准备上。首先是转债的涨跌幅,这里当然要剔除当日无交易或停牌的品种。我们也剔除近期出现的“双高品种”,但方式更为简单:剔除换手率过百的品种即可。实现如下。第一个函数用于筛选当日有效样本,other属性在本报告中没有作用,后一个则是筛选所有在目标区间有成交的样本。最后一个则是提取当日(date)有效样本的涨跌幅,obj对象为我们的数据综合处理对象,此前报告有介绍,可以简单理解为obj.DB[‘Amt’]返回的是载有成交额的DataFrame,以此类推。def selByAmt(obj, date, other=None, noCrazy=True):
t = obj.DB['Amt'].loc[date] > 0
t *= obj.DB['Amt'].loc[date] < (obj.DB['Close'].loc[date] * obj.DB['Outstanding'].loc[date] / 100.0)
if other:
for k, v in other.iteritems():
t *= obj.DB[k].loc[date].between(v[0], v[1])
codes = list(t[t].index)
return codes
def selByAmtPq(obj, start, end):
t = obj.DB['Amt'].loc[start:end].sum() > 0
codes = list(t[t].index)
return codes
def getCBReturn(date, codes=None, obj=None):
if not obj:
obj = cb.cb_data()
if not codes:
codes = selByAmt(obj, date)
loc = obj.DB['Amt'].index.get_loc(date)
return 100.0 * (obj.DB['Close'][codes].iloc[loc] / obj.DB['Close'][codes].iloc[loc-1] - 1.0)
然后是行业因子。
如前所述,行业因子是哑变量,非0即1。这里我们先取每个转债正股所处行业,然后处理为哑变量矩阵。下面第一个函数得到转债对应正股代码,第二个得到对应行业,均用到sql查询,但万得Python接口也均可做到。最后一个函数用来生成哑变量矩阵,唯一需要说明的是下面用到了两次encode,如果使用python3以上则不会有这个问题,python27在部分IDE下会出现需要将unicode再编码才能做比较级运算的问题。
def getUnderlyingCodeTable(codes):
'''
输入转债代码list
返回正股代码list
'''
sql = '''select a.s_info_windcode cbCode,b.s_info_windcode underlyingCode
from winddf.ccbondissuance a,winddf.asharedescription b
where a.s_info_compcode = b.s_info_compcode and
length(a.s_info_windcode) = 9 and
substr(a.s_info_windcode,8,2) in ('SZ','SH') and
substr(a.s_info_windcode,1,3) not in ('137','117') '''
con = login(1) # 为我们的万得数据链接对象
ret = pd.read_sql(sql, con, index_col='CBCODE')
return ret.loc[codes]
def cbInd(codes):
dfUd = getUnderlyingCodeTable(codes)
sql = '''select a.s_info_windcode as udCode,
b.industriesname indName
from
winddf.ashareindustriesclasscitics a,
winddf.ashareindustriescode b
where substr(a.citics_ind_code,1,4) = substr(b.industriescode,1,4) and
b.levelnum = '2' and
a.cur_sign = '1' and
a.s_info_windcode in ({_codes})
'''.format(_codes = rsJoin(list(set(dfUd['UNDERLYINGCODE']))))
con = login(1) # 为我们的万得数据链接对象
dfInd = pd.read_sql(sql, con, index_col='UDCODE')
dfUd['Ind'] = dfUd['UNDERLYINGCODE'].apply(lambda x: dfInd.loc[x, 'INDNAME'] if x in dfInd.index else None)
return dfUd['Ind']
def factorInd(codes, cbInd=None):
if not cbInd:
cbInd = pd.DataFrame({'ind':_cbInd(codes)})
cbInd = pd.merge(cbInd, indCls, left_on='ind', right_index=True)
dfRet = pd.DataFrame(index=codes, columns=set(cbInd['ind']))
for c in dfRet.columns:
tempCodes = cbInd.loc[cbInd['ind'].apply(lambda x:x.encode('gbk')) == c.encode('gbk')].index
dfRet.loc[tempCodes, c] = 1.0
return dfRet.fillna(0)
这里需要注意的是,无论用那种行业分类,都会涉及到接近30个行业因子。虽然都只是哑变量,但在个券样本够少的情况下依然能出现明显的过拟合问题。因此,这种做法仅限2018年以后的数据,如果要分析更早的数据,我们建议用更粗糙的行业分类方式,比如分为金融、必选消费、可选消费、周期、中游制造、TMT这样的方法,来让模型重新回到“模糊正确”上来。
然后我们来处理风格因子。由于转债的特点,我们在此时要注意的方面比较多,包括:1、尤其在多因子回归时,要控制因子数量,不轻易加因子进来,尤其是与其他传统大类因子有较强相关性的;2、极端值在转债样本中很常见,我们统一用先排序,再中心化的方式处理每一个因子(下方的rankCV函数);3、为体现转债的衍生品特性,我们需要考虑把一些估值型指标加进来,如溢价率、债底溢价率、价位等等,但仍要控制因子数量。因而这里需要做些取舍;4、一些传统的因子,也要考虑转债和正股的区别。比如市值因子,一般股票模型喜欢用log(流通市值),但经过测试,“转债存量市值”更有效,t值明显更大。限于篇幅,我们无法在此展示每一个因子的获取(实际也大同小异),在此仅举一例,其他因子方法类似,只要最终能得到记载因子数据的DataFrame并满足以日期为行、以转债代码为列即可。下面的第一个函数factorSize_cb_outstanding为获取转债存量市值的方法(这个函数有点特殊,它在单因子、多因子回归时有其他用途),rankCV为排序中心化的小函数,用到DataFrame的运算,也比较简单。def factorSize_cb_outstanding(codes, start, end, obj=None):
if not obj:
obj = cb.cb_data()
ost_mv = obj.DB['Close'].loc[start:end, codes] * obj.DB['Outstanding'].loc[start:end, codes] / 100.0
return ost_mv
def rankCV(df):
rk = df.rank(axis=1, pct=True)
return (rk - 0.5).div(rk.std(axis=1), axis='rows')
下面可以开始做最终的单因子测试以及多因子回归了。单因子的相对简单,而多因子只需要稍加改动即可,下面先列出单因子的回归方法。没有技术上的难点,主要用到sklearn的LinearRegression模型。在每日回归的过程中,我们也顺便保留了t值和拟合优度数据(毕竟单因子的主要目的在于因子本身的测试和观察,尤其t值至关重要)。注意,在这里此前的函数factorSize_cb_outstanding又出现了,是因为我们需要借助它来解决异方差问题。在股票的因子模型中,一种实践上成熟的模式是用流通市值作为权重,以加权最小二乘回归替代OLS,从而能先验地解决异方差问题。而这个问题在转债上似乎更为严重,我们在此使用了转债市值作为权重来解决这一问题,实证效果尚可。
def oneFactorReg(start, end, dfFactor, factorName='ToBeTest',dfFctInd=None, obj=None):
if not obj:
obj = cb.cb_data()
if not dfFctInd:
codes = selByAmtPq(obj, start, end)
codes = list(set(codes).intersection(list(dfFactor.columns)))
dfFctInd = factorInd(codes)
arrDates = list(obj.DB['Amt'].loc[start:end].index)[1:]
lr = LinearRegression(fit_intercept=True)
dfRet = pd.DataFrame(index=arrDates
, columns=['One'] + list(dfFctInd.columns) + [factorName, 't','score'])
dfCBMV = factorSize_cb_outstanding(codes, start, end, obj)
for date in arrDates:
print date
tCodes = selByAmt(obj, date)
srsReturn = getCBReturn(date, tCodes, obj)
dfX = pd.DataFrame(index=tCodes)
dfX[list(dfFctInd.columns)] = dfFctInd
dfX[factorName] = dfFactor.loc[date]
dfX.dropna(inplace=True)
idx = dfX.index
arrW = pd.np.sqrt(dfCBMV.loc[date, idx])
arrW /= arrW.sum()
lr.fit(dfX.loc[:,:], srsReturn[idx], arrW)
dfRet.loc[date,list(dfFctInd.columns) + [factorName]] = lr.coef_
dfRet.loc[date, 'One'] = lr.intercept_
dfRet.loc[date, 't'] = t_test(lr, dfX.loc[:,:], srsReturn[idx])
dfRet.loc[date, 'score'] = lr.score(dfX.loc[:,:], srsReturn[idx], arrW)
print pd.np.abs(dfRet['t']).mean()
print pd.np.abs(dfRet['score']).mean()
return dfRet
def t_test(lr, x, y):
n = len(x) * 1.0
predY = lr.predict(x)
e2 = sum((predY - y) ** 2)
varX = pd.np.var(x) * n
t = lr.coef_ * pd.np.sqrt(varX) / pd.np.sqrt(e2 / n)
return t[-1]
而多因子版本,只需要把dfFactor相应改成包含多个dfFactor的字典,以及将factorName改为因子名称的列表,并删除dfRet列中的t和score即可。限于篇幅,不再重复。1、规模因子上,转债规模比正股市值更有影响力,可能与转债投资群体,以及因规模大小差异而造成投资者对该转债定位不同有关。同时,一个好的方面是,转债规模与其他因子之间的相关系数,都要小于正股市值,这减少了多重共线的隐患;但显然,规模不是一个收益型因子,也就是它能起到很好的分类效果,但无法提供单一方向的持续收益——持续持有大或小品种,都不是能简单收下超额回报的策略,对风格的倾向性分析,是转债投资者始终要做的。不过,历史上看,小略胜大(持有大市值组合会有相对负回报),而越是有行情的阶段,这个情况就越明显。也就是,在有行情的情况下,不满仓自然不易跑赢市场,但持仓风格过于偏大体型,效果也不好。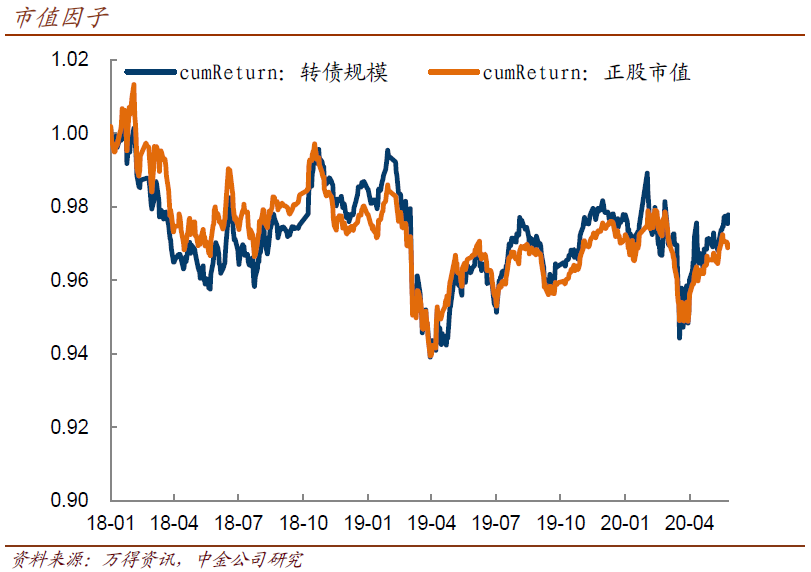
2、转债特质因子上,我们测算了溢价率、债底溢价率、价位、平底溢价率、(溢价率 – 债底溢价率)等多个指标,18年以后的数据显示,最简单直白的溢价率、债底溢价率以及价位,就能起到很好的解释效果,不必做更复杂的操作。不过,溢价率与后两者之间有着比较明显的负相关(价位的负相关性弱一些),只留一个的情况下,我们选择留溢价率。当然,这三者都能创造持续单向收益。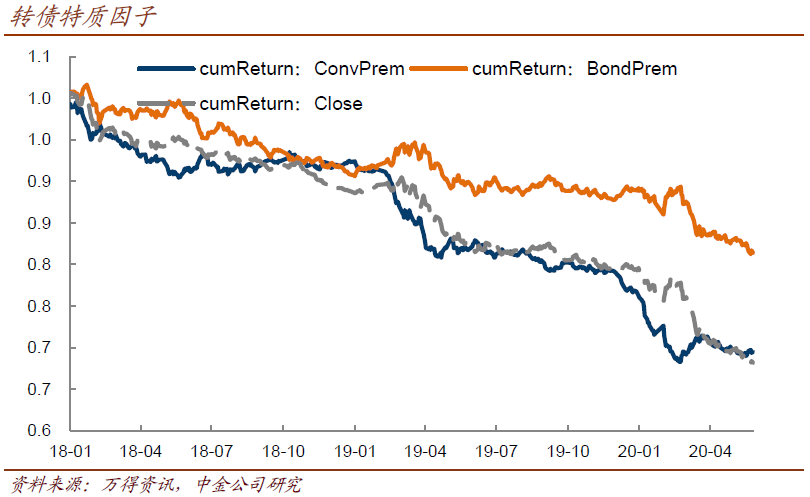
3、价值因子的影响力弱于前两者,相对而言P/B的效果更佳,且与市值因子相关系数控制在
-0.3附近,尚可接受。值得注意的是,与直观感受不同,低P/B没有超额收益,P/E、P/CF、P/S、PEG等也一样。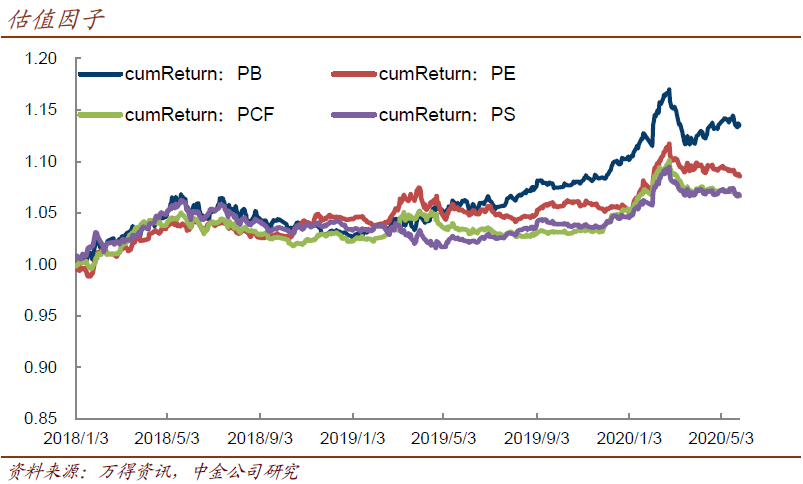
4、成长性因子的影响力也弱于前两者,好在与市值的相关性也不太强,逻辑上其提供的增量信息也更明了。几个类似的指标中,营收TTM成长即有相对可以接受的效果,且出现负值、跳跃等问题更少,我们倾向于用这个指标。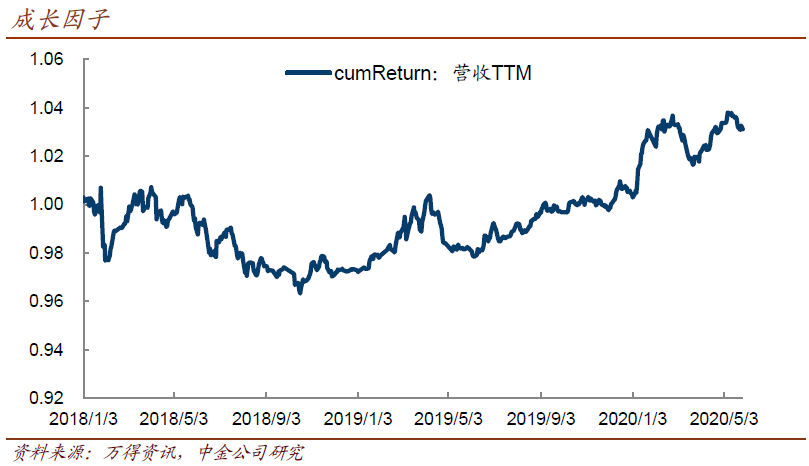
回到开篇的问题,转债的因子模型,能有什么用途?显然,我们没有对这个模型过于精雕细琢,因为我们的目标只是做一个稳定可用的工具,来观测市场。多因子模型下,我们可以更精致地衡量组合风险与收益,因为这时我们已经可以得到各因子之间的相关系数矩阵了。而单因子可以更清晰地看到“哪类转债在涨、哪类在跌”,以及哪些因子还在持续发挥作用,哪些回调了——这样可以得到一个比日常复盘更有效率的描述,加上一些对市场趋势的判断,我们可以更有效率地得到富有针对性的策略。此外,上述框架之下,投资者还可以进一步开发更接近“收益型”的因子策略。比如,我们看到溢价率因子和价格因子都有持续负收益(反过来低价、低溢价就有正收益),相关系数为负且并不绝对(-0.6左右)。那么,“2 *价格分位数倒序+ 溢价率分位数倒序”会有怎样的效果呢?下图给出了答案——所以,easy ball不是偶然,也不难提出来。类似的几个问题,投资者也可以从模型中得到答案,比如2016~2018年,超额收益真要那么执着于“精选个券”吗——这一段显然做对了风格就好。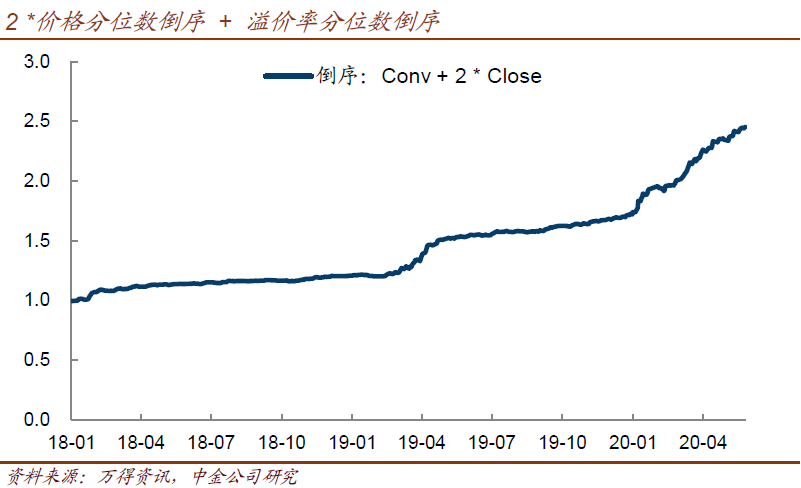
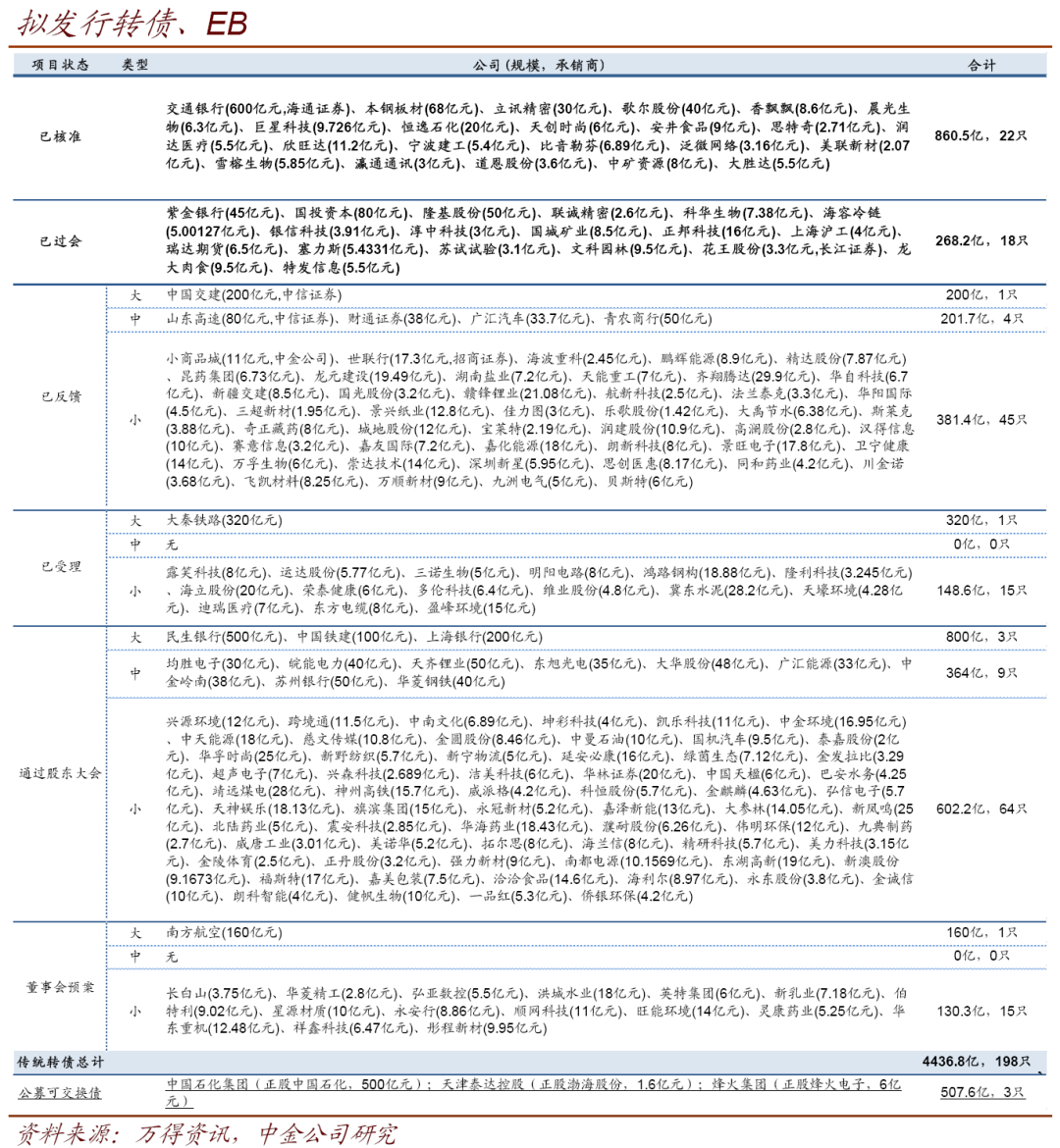
本周股市全面反弹,上周五至本周四收盘,万得全A上涨3.84%,上证50上涨2.62%,创业板指上涨4.69%,中小板指上涨5.21%,主要指数均收复前一周下跌失地,点位上普遍超过5月上旬平台位置,中小板相关指数在4月起的反弹中进度较慢,本周也反弹至前高位的密集成交区。本周前四天日均成交额7375亿元,较上周有明显提升。行业层面,电子、传媒、零售、通信、汽车涨幅居前,煤炭、钢铁、农牧、建材涨幅落后,本周市场对“复苏”概念有所倾斜,服务性消费、商贸零售、汽车领涨频次提升,不过这些同时也是此前相对落后的板块,与这类板块穿插领涨的是电子、通信、传媒等品种,消费板块的分化开始出现。转债指数上周五至本周四上涨1.62%,幅度低于各股指。个券层面,振德(62%)、春秋(20%)、新天(19%)、精测(18%)、国轩(17%)涨幅居前,特发(-13%)、凯龙(-11%)、广电(-9%)、模塑(-7%)领跌。全市场平均平价溢价率下跌2.4个百分点,百元以上平价的品种整体溢价率仅小幅下调0.1个百分点。本周新公告了3个转债预案,为华东重机(12.48亿元)、祥鑫科技(6.47亿元)、彤程新材(9.95亿元);证监会新受理4个转债预案,为迪瑞医疗(7亿元)、东方电缆(8亿元)、盈峰环境(15亿元)、大秦铁路(320亿元);4个方案过会,为花王股份(3.3亿元)、龙大肉食(9.5亿元)、特发信息(5.5亿元)、隆基股份(
50亿元);大胜达(5.5亿元)拿到核准批文。目前核准待发个券共22只860.5亿元,已过会未核准个券共18只268.2亿元。