列表基础
1 创建列表
列表是一个容器,使用一对中括号[]创建一个列表。
创建一个空列表:
a = [] # 空列表
创建一个含有 5 个整型元素的列表a:
a = [3,7,4,2,6]
列表与我们熟知的数组很相似,但又有很大区别。
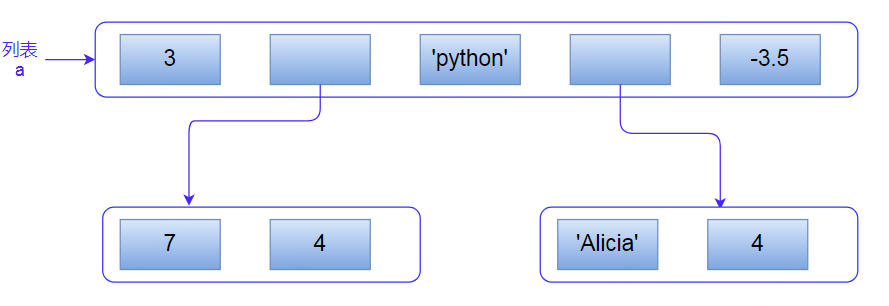
一般数组内的元素要求同一类型,但是列表内可含有各种不同类型,包括再嵌套列表。
如下,列表a包含三种类型:整形,字符串,浮点型:

如下列表a嵌套两个列表:
2 访问元素
列表访问主要包括两种:索引和切片。
如下,访问列表a可通过我们所熟知的正向索引,注意从0开始;
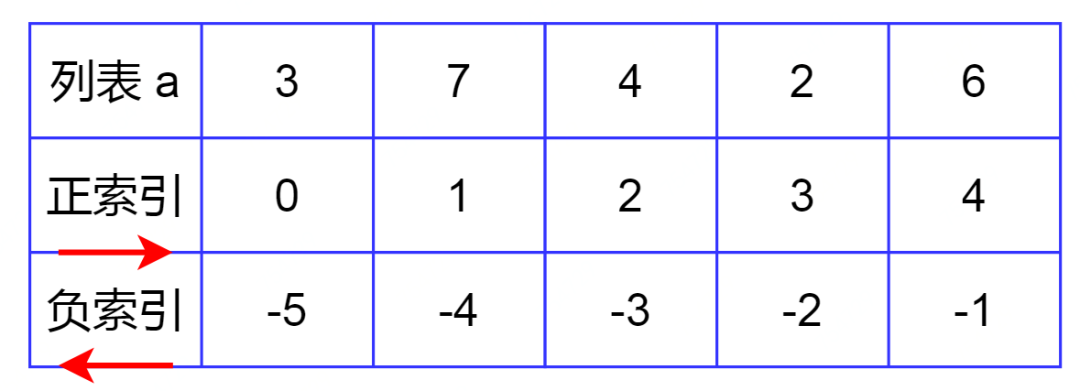
也可通过Python特有的负向索引,
即从列表最后一个元素往前访问,此时索引依次被标记为-1,-2,...,-5 ,注意从-1开始。
除了以上通过索引访问单个元素方式外,
还有非常像matlab的切片访问方式,这是一次访问多个元素的方法。
切片访问的最基本结构:中间添加一个冒号。
如下切片,能一次实现访问索引为1到4,不包括4的序列:
In [1]: a=[3,7,4,2,6]
In [2]: a[1:4]
Out[2]: [7, 4, 2]

Python支持负索引,能带来很多便利。比如能很方便的获取最后三个元素:
In [1]: a=[3,7,4,2,6]
In [3]: a[-3:]
Out[3]: [4, 2, 6]
除了使用一个冒号得到连续切片外,
使用两个冒号获取带间隔的序列元素,两个冒号后的数字就是间隔长度:
In [1]: a=[3,7,4,2,6]
In [7]: a[::2] # 得到切片间隔为2
Out[7]: [3, 4, 6]
其实最全的切片结构:start:stop:interval,如下所示,获得切片为:索引从1到5间隔为2:
In [6]: a=[3,7,4,2,6]
In [7]: a[1:5:2]
Out[7]: [7, 2]
3 添加元素
列表与数组的另一个很大不同,使用数组前,需要知道数组长度,便于从系统中申请内存。
但是,列表却不需要预先设置元素长度。
它支持任意的动态添加元素,完全不用操心列表长短。
它会随着数组增加或删除而动态的调整列表大小。
这与数据结构中的线性表或向量很相似。
添加元素通常有两类场景。
append一次添加1个元素,insert在指定位置添加元素:
In [8]: a=[3,7,4,2,6]
In [9]: a.append(1) # append默认在列表尾部添加元素
In [10]: a
Out[10]: [3, 7, 4, 2, 6, 1]
In [11]: a.insert(2,5) # insert 在索引2处添加元素5
In [12]: a
Out[12]: [3, 7, 5, 4, 2, 6, 1]
extend或直接使用+实现一次添加多个元素:
In [13]: a.extend([0,10])# 一次就地添加0,10两个元素
In [14]: a
Out[14]: [3, 7, 5, 4, 2, 6, 1, 0, 10]
In [15]: b = a+[11,21] # + 不是就地添加,而是重新创建一个新的列表
In [16]: b
Out[16]: [3, 7, 5, 4, 2, 6, 1, 0, 10, 11, 21]
这里面有一个重要细节,不知大家平时注意到吗。
extend 方法实现批量添加元素时未创建一个新的列表,而是直接添加在原列表中,这被称为in-place,就地。而b=a+list对象实际是创建一个新的列表对象,所以不是就地批量添加元素。
但是,a+=一个列表对象,+=操作符则就会自动调用extend方法进行合并运算。大家注意这些微妙的区别,不同场景选用不同的API,以此高效节省内存。
4 删除元素
删除元素的方法有三种:remove,pop,del.
remove直接删除元素,若被删除元素在列表内重复出现多次,则只删除第一次:
In [17]: a=[1,2,3,2
,4,2]
In [18]: a.remove(2)
In [19]: a
Out[19]: [1, 3, 2, 4, 2]
pop方法若不带参数默认删除列表最后一个元素;若带参数则删除此参数代表的索引处的元素:
In[19]: a = [1, 3, 2, 4, 2]
In [20]: a.pop() # 删除最后一个元素
Out[20]: 2
In [21]: a
Out[21]: [1, 3, 2, 4]
In [22]: a.pop(1) # 删除索引等于1的元素
Out[22]: 3
In [23]: a
Out[23]: [1, 2, 4]
del与pop相似,删除指定索引处的元素:
In [24]: a = [1, 2, 4]
In [25]: del a[1:] # 删除索引1到最后的切片序列
In [26]: a
Out[26]: [1]
5 list 与 in
列表是可迭代的,除了使用类似c语言的索引遍历外,还支持for item in alist这种直接遍历元素的方法:
In [28]: a = [3,7,4,2,6]
In [29]: for item in a:
...: print(item)
3
7
4
2
6
in 与可迭代容器的结合,还用于判断某个元素是否属于此列表:
In [28]: a = [3,7,4,2,6]
In [30]: 4 in a
Out[30]: True
In [31]: 5 in a
Out[31]: False
6 list 与数字
内置的list与数字结合,实现元素的复制,如下所示:
In [32]: ['Hi!'] * 4
Out[32]: ['Hi!', 'Hi!', 'Hi!', 'Hi!']
表面上这种操作太方便,实际确实也很方便,比如我想快速打印20个-,只需下面一行代码:
In [33]: '-'*20
Out[33]: '--------------------'
使用列表与数字相乘构建二维列表,然后第一个元素赋值为[1,2],第二个元素赋值为[3,4],第三个元素为[5] :
In [34]: a = [[]] * 3
In [35]: a[0]=[1,2]
In [36]: a[1]=[3,4]
In [37]: a[2]=[5]
In [38]: a
Out[38]: [[1, 2], [3, 4], [5]]
7 列表生成式
列表生成式是创建列表的一个方法,它与使用append等API创建列表相比,书写更加简洁。
使用列表生成式创建1到50的所有奇数列表:
a=[i for i in range(50) if i&1]
列表进阶
8 其他常用API
除了上面提到的方法外,列表封装的其他方法还包括如下:
clear,index,count,sort,reverse,copy
clear 用于清空列表内的所有元素index 用于查找里面某个元素的索引:
In [4]: a=[1,3,7]
In [5]: a.index(7)
Out[5]: 2
count 用于统计某元素的出现次数:
In [6]: a=[1,2,3,2,2,5]
In [7]: a.count(2) # 元素2出现3次
Out[7]: 3
sort 用于元素排序,其中参数key定制排序规则。如下列表,其元素为元祖,根据元祖的第二个值由小到大排序:
In [8]: a=[(3,1),(4,1),(1,3),(5,4),(9,-10)]
In [9]: a.sort(key=lambda x:x[1])
In [10]: a
Out[10]: [(9, -10), (3, 1), (4, 1), (1, 3), (5, 4)]
reverse 完成列表反转:
In [15]: a=[1,3,-2]
In [16]: a.reverse()
In [17]: a
Out[17]: [-2, 3, 1]
copy 方法在下面讲深浅拷贝时会详细展开。
9 列表实现栈
列表封装的这些方法,实现栈这个常用的数据结构比较容易。栈是一种只能在列表一端进出的特殊列表,pop方法正好完美实现:
In [23]: stack=[1,3,5]
In [24]: stack.append(0) # push元素0到尾端,不需要指定索引
In [25]: stack
Out[25]: [1, 3, 5, 0]
In [26]: stack.pop() # pop元素,不需指定索引,此时移出尾端元素
Out[26]: 0
In [27]: stack
Out[27]: [1, 3, 5]
由此可见Python的列表当做栈用,完全没有问题,push 和 pop 操作的时间复杂度都为 O(1)
但是使用列表模拟队列就不那么高效了,需要借助Python的collections模块中的双端队列deque实现。
10 列表包含自身
列表的赋值操作,有一个非常有意思的问题,大家不妨耐心看一下。
In [1]: a=[1,3,5]
In [2]: a[1]=a # 列表内元素指向自身
这样相当于创建了一个引用自身的结构。
打印结果显示是这样的:
In [3]: a
Out[3]: [1, [...], 5]
中间省略号表示无限循环,这种赋值操作导致无限循环,这是为什么?下面分析下原因。
执行 a = [1,3,5] 的时候,Python 做的事情是首先创建一个列表对象 [1, 3, 5],然后给它贴上名为a的标签。
执行 a[1] = a 的时候,Python 做的事情则是把列表对象的第二个元素指向a所引用的列表对象本身。
执行完毕后,a标签还是指向原来的那个对象,只不过那个对象的结构发生了变化。
从之前的列表 [1,3,5] 变成了 [1,[...], 5],而这个[...]则是指向原来对象本身的一个引用。
如下图所示:
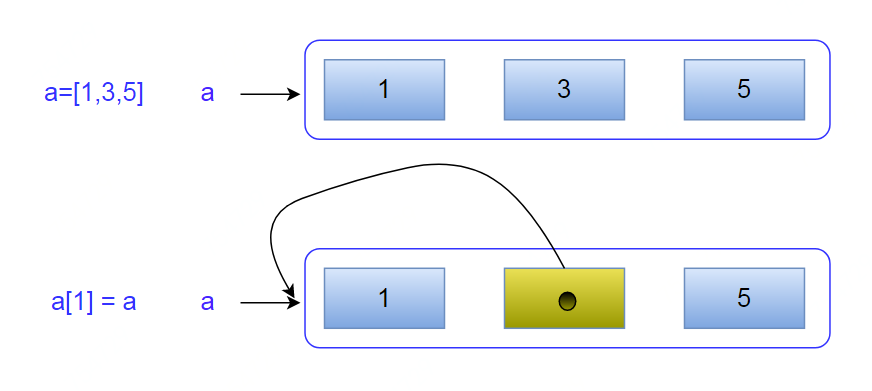
可以看到形成一个环路:a[1]--->中间元素--->a[1],所以导致无限循环。
11 插入元素性能分析
与常规数组需要预先指定长度不同,Python 中list不需要指定容器长度,允许我们随意的添加删除元素。
但是这种便捷性也会带来一定副作用,就是插入元素的时间复杂度为O(n),而不是O(1),因为insert会导致依次移动插入位置后的所有元素。
为了加深对插入元素的理解,特意把cpython实现insert元素的操作源码拿出来。
可以清楚看到insert元素时,插入位置处的元素都会后移一个位置,因此插入元素的时间复杂为O(n),所以凡是涉及频繁插入删除元素的操作,都不太适合用list.
static int
ins1(PyListObject *self, Py_ssize_t where, PyObject *v)
{
assert((size_t)n + 1 if (list_resize(self, n+1) 0)
return -1;
if (where 0) {
where += n;
if (where 0)
where = 0;
}
if (where > n)
where = n;
items = self->ob_item;
//依次移动插入位置后的所有元素
// O(n) 时间复杂度
for (i = n; --i >= where; )
items[i+1] = items[i];
Py_INCREF(v);
items[where] = v;
return 0;
}
12 深浅拷贝
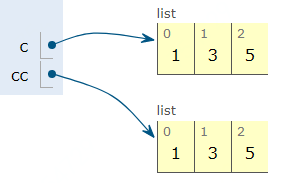
list 封装的copy 方法实现对列表的浅拷贝,浅拷贝只拷贝一层,具体拿例子说:
In [38]: c =[1,3,5]
In [39]: cc = c.copy()
c和cc分别指向一片不同内存,示意图如下:
这样修改cc的第一个元素,原来c不受影响:
In [40]: cc[0]=10 # 修改cc第一个元素
In [41]: cc
Out[41]: [10, 3, 5]
In [42]: c # 原来 c 不受影响
Out[42]: [1, 3, 5]
但是,如果内嵌一层列表,再使用copy时只拷贝一层:
In [32]: a=[[1,3],[4,2]]
In [33]: ac = a.copy()
In [34]: ac
Out[34]: [[1, 3], [4, 2]]
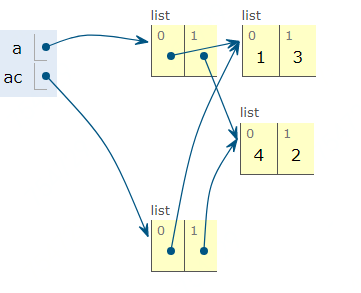
上面的示意图清晰的反映出这一点,内嵌的列表并没有实现拷贝。因此再修改内嵌的元素时,原来的列表也会受到影响。
In [35]: ac[0][0]=10
In [36]: ac
Out[36]: [[10, 3], [4, 2]]
In [37]: a
Out[37]: [[10, 3], [4, 2]]
要想实现深度拷贝,需要使用Python模块copy中的deepcopy方法。
13 列表可变性
列表是可变的,可变的对象是不可哈希的,不可哈希的对象不能被映射,因此不能被用作字典的键。
In [51]: a=[1,3]
In [52]: d={a:'不能被哈希'} #会抛出如下异常
# TypeError: unhashable type: 'list'
但是,有时我们确实需要列表对象作为键,这怎么办?
可以将列表转化为元祖,元祖是可哈希的,所以能作为字典的键。
总结
以上就是列表专题的所有13个方面总结,目录如下:
列表基础
1 创建列表
2 访问元素
3 添加元素
4 删除元素
5 list 与 in
6 list 与数字
7 列表生成式
列表进阶
8 其他常用API
9 列表实现栈
10 列表包含自身
11 插入元素性能分析
12 深浅拷贝
13 列表可变性
总结
此外,推荐一本对Python感兴趣的书籍《Python进阶》,是《Intermediate
Python》的中文译本,IntermediatePython这本书具有如下几个优点:简单、易读、易译。这些都不是重点,重点是:它是一本开脑洞的书。无论你是Python初学者,还是Python高手,它显现给你的永远是Python里最美好的事物。
扫描下方公众号回复Python进阶,即可领取

原书作者
感谢英文原著作者 @yasoob《Intermediate Python》,有了他才有了这里的一切
本书作者的行文方式有着科普作家的风范,--那就是能将晦涩难懂的技术用比较清晰简洁的方式进行呈现,深入浅出的风格在每个章节的讨论中都得到了体现:
每个章节都非常精简,5分钟就能看完,用最简洁的例子精辟地展现了原理
每个章节都会通过疑问,来引导读者主动思考答案
每个章节都引导读者做延伸阅读,让有兴趣的读者能进一步举一反三
每个章节都是独立的,你可以挑选任意的章节开始阅读,而不受影响








