唯一索引
UNIQUE
:唯一索引列的值必须唯一,但允许有空值。如果是组合索引,则列值的组合必须唯一。
创建命令:
ALTER TABLE table_name ADD UNIQUE (column);
普通索引
INDEX
:最基本的索引,它没有任何限制。
创建命令:
ALTER TABLE table_name ADD INDEX index_name (column);
组合索引
INDEX
:组合索引,即一个索引包含多个列。多用于避免回表查询。
创建命令:
ALTER TABLE table_name ADD INDEX index_name(column1, column2, column3);
全文索引
FULLTEXT
:全文索引(也称全文检索)是目前搜索引擎使用的一种关键技术。
创建命令:
ALTER TABLE table_name ADD FULLTEXT (column);
读到就是赚到,溪源这里再赠送一条删除索引命令:索引一经创建不能修改,如果要修改索引,只能删除重建。
删除索引命令:
DROP INDEX index_name ON table_name;
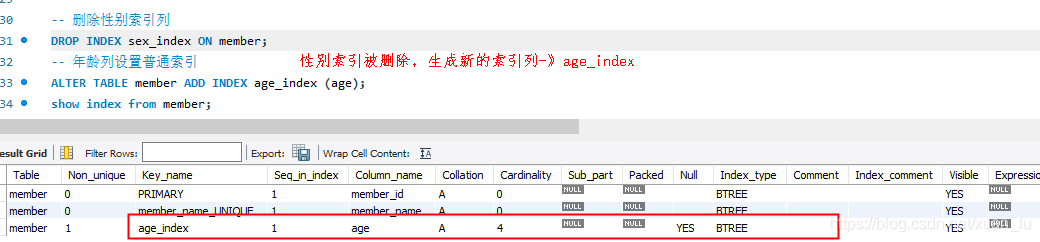
-- 删除性别索引列
DROP INDEX sex_index ON member;-- 年龄列设置普通索引
ALTER TABLE member ADD INDEX age_index (age);
show index from member;
1
2
3
4
5
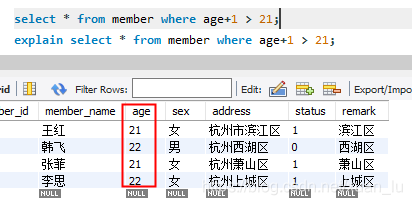
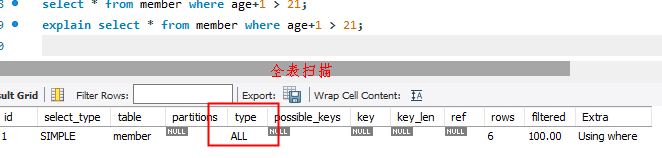
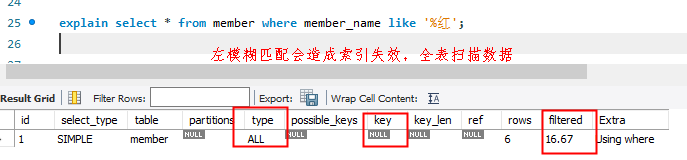
以下这条SQL会命中索引吗???
答案肯定是:不会
解密时刻:
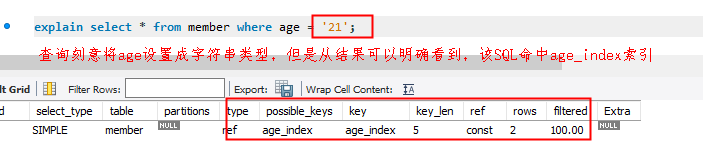
细心的伙伴可能会发现,溪源故意将
status
字段设置成VARCHAR类型,到了显露目的的时候啦,这里会将age索引列一起谈论是目的的,哈哈~
首先使用命令将status字段设置成普通索引
ALTER TABLE member ADD INDEX status_index (status);
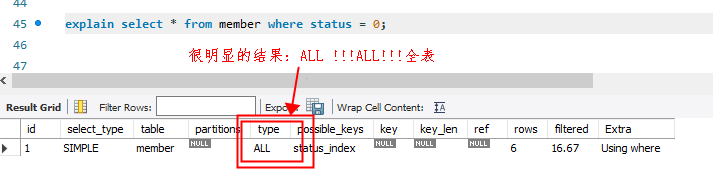
那么反过来,如果我们将status字段,查询时设置成非VARCAHR类型,会命中索引吗???
对比结果很明显啦,为了加深大家的理解和好奇心,溪源这里暂时不抛出答案,有兴趣的小伙伴百度一下哦,欢迎评论去留言哦~
相信到这里大家已经捞到了不少东西,趁着大家高涨的热情,继续分享联合索引~
联合索引问题:
为了避免索引数量过多,下面溪源将上面建立的
age_index\status_index
全部删除后,我们建立三个字段的联合索引;
ALTER TABLE member ADD INDEX age_sex_status_index (age,sex,status);
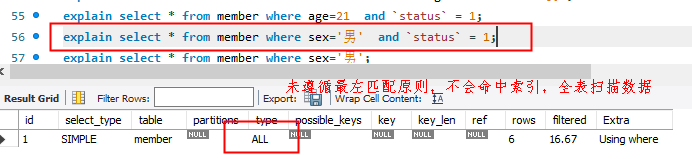
查询顺序按照索引顺序,与乱序是否命中:
explain select * from member where age=21 and sex='男' and status = 1; explain select * from member where age=21 and status = 1 and sex='男'; explain select * from member where status = 1 and age=21 and sex='男'; explain select * from member where age=21 and status = 1;
以上SQL语句均会命中索引,因为底层MySQL提供语句优化器,优先使用索引。












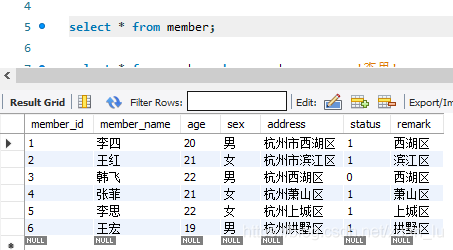
 溪源此时表中仅有6条数据时,设置性别作为索引列,查询会命中索引;
溪源此时表中仅有6条数据时,设置性别作为索引列,查询会命中索引;
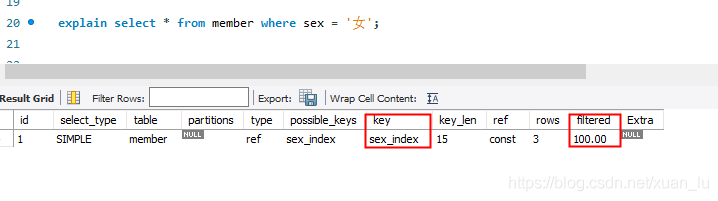
 可以从结果中看到已经命中索引列
可以从结果中看到已经命中索引列
 以下这条SQL会命中索引吗???
以下这条SQL会命中索引吗???