一、本文编写缘由
很久没有写过爬虫,已经忘得差不多了。以爬取p站图片为着手点,进行爬虫复习与实践。
二、获取网页源码
爬取网页数据的过程主要用到request库,一个简单的网页爬虫实现过程大致可以分为一下步骤:
下面以爬取pixiv网站为例,获取pixiv网站首页源码并存储到pixiv1.html文件中。
import requests
if __name__ == "__main__":
# step 1: 爬取网页数据
# 指定url
url = 'https://www.pixiv.net/'
# 发起请求
home_text = requests.get(url).text
# step 2: 解析爬取数据
# step 3: 存储爬取数据
save_path = './pixiv1.html'
with open(save_path, 'w', encoding='utf-8') as fp:
fp.write(home_text)
print('下载成功!')
经过上述操作,将会在当前目录下生成一个“pixiv1.html”文件。双击文件打开,会发现是下图这样子,访问该网站首先需要登录,所以会跳入到登录注册页面,且页面都为日文。

针对这个问题,右键检查网页,进入network,然后刷新页面,发现有数据更新,点击查看Headers。发现request headers里面带有cookie,因此需要伪装UA,设置请求头header,将request header复制到代码块中。
# 指定url
url = 'https://www.pixiv.net/'
headers = {
'user-agent': '你的user-agent',
'referer':'https://www.pixiv.net/',
'sec-fetch-dest':'document',
'sec-fetch-mode':'navigate',
'sec-fetch-site':'same-origin',
'sec-fetch-user':'1',
'upgrade-insecure-requests':'1',
'accept':'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
'accept-encoding':'gzip, deflate, br',
'accept-language':'zh-CN,zh;q=0.9,en-US;q=0.8,en;q=0.7',
'cache-control':'max-age=0',
'cookie': '你的浏览器cookie'
}
# 发起请求
home_text = requests.get(url, headers=headers).text
再次打开保存的网页文件“pixiv2.html”,发现页面并不像我们登录进去的一样,而是如下图所示。
小朋友,你是不是有很多问号......
三、爬取单张缩略图片
由上一个章节可知,首页的插画部分并不是首页的直接源码,而是引入了另外的网页地址和脚本。这里,通过进入到网页并进行分析,右键图片再点击检查获取图片地址,该图片比较小,为缩略图片。复制图片地址,并粘贴到浏览器的地址栏,可显示图片。

根据获得的图片的地址,直接对图片地址进行访问,获取图片数据,并存储到本地。
import requests
if __name__ == "__main__":
# 指定url
url = 'https://i.pximg.net/c/360x360_70/custom-thumb/img/2020/09/19/02/56/19/84460298_p0_custom1200.jpg'
# 发起请求
img_data = requests.get(url).content
# 存储图片
img_path = './1.jpg'
with open(img_path, 'wb') as fp:
fp.write(img_data)
print('下载成功!')
于是名为“1.jpg”的图片在当前目录下生成,双击打开发现出错。如下图所示。
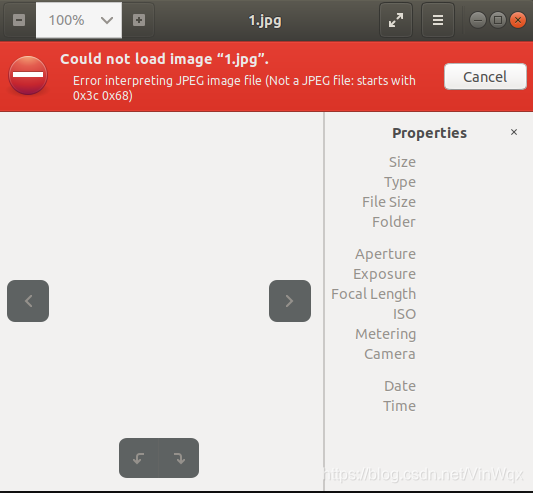
这是因为请求头信息缺失,需要添加请求头,代码如下:
# 指定url
url = 'https://i.pximg.net/c/360x360_70/custom-thumb/img/2020/09/19/02/56/19/84460298_p0_custom1200.jpg'
# UA伪装
headers = {
'user-agent': '你的user-agent',
'cookie': '你的浏览器cookie',
'referer':'https://www.pixiv.net/',
'sec-fetch-dest':'document',
'sec-fetch-mode':'navigate',
'sec-fetch-site':'same-origin',
'sec-fetch-user':'1',
'upgrade-insecure-requests':'1',
'accept':'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
'accept-encoding':'gzip, deflate, br',
'accept-language':'zh-CN,zh;q=0.9,en-US;q=0.8,en;q=0.7',
'cache-control':'max-age=0',
}
# 发起请求
img_data = requests.get(url, headers=headers).content
“1.jpg”文件生成,双击可打开,爬取单张图片成功。
三、爬取单张高清原图
1、获取原图地址
要爬取原图,首先还是得获取图片地址。点击插画的缩略图,进入插画的详情页面,右键插画图片inspect网页,如下图所示。
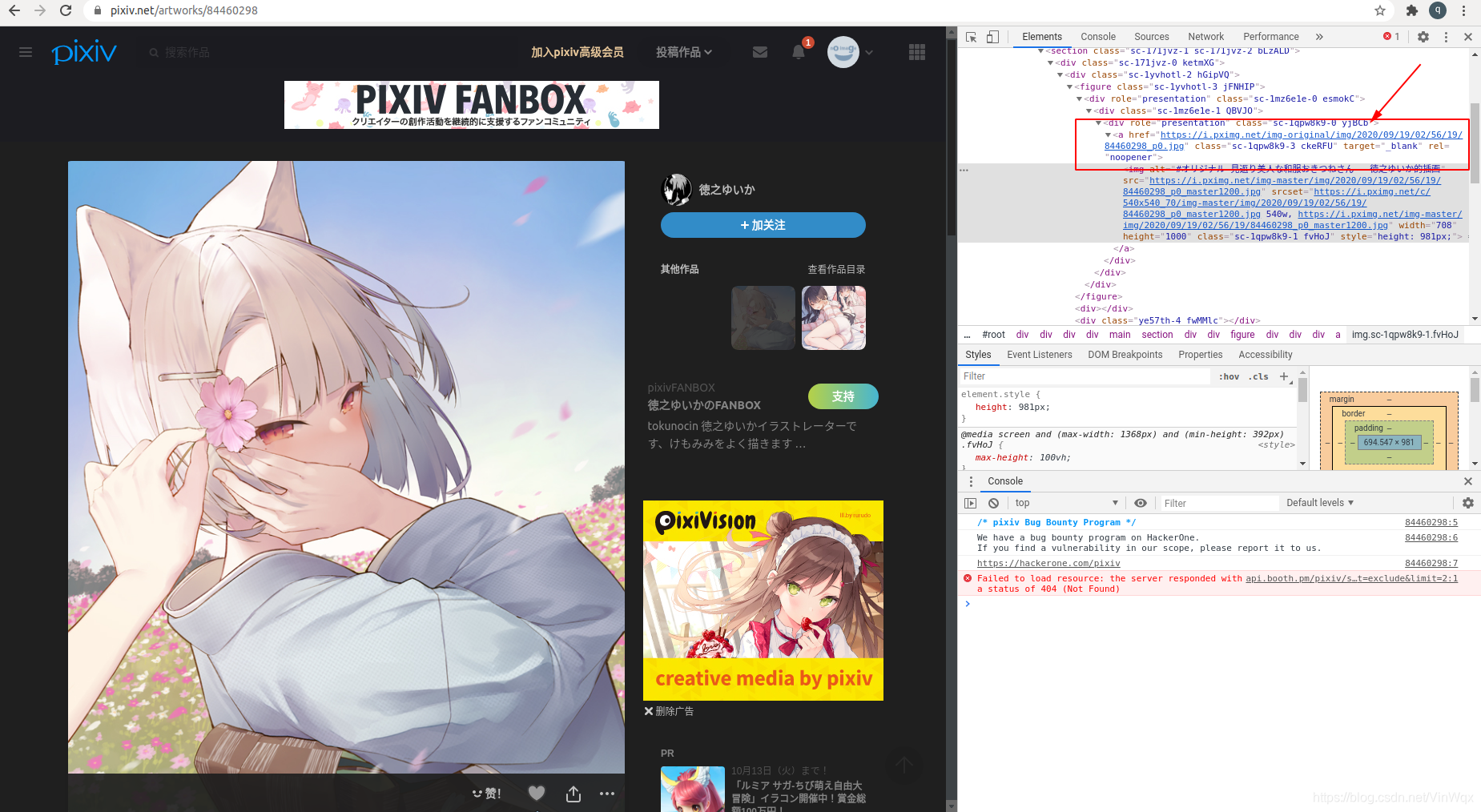
点击左侧图片进入大图预览模式,再右键inspect网页,可知右边红色框中a标签的链接地址就是插画的原图地址。但是复制该地址到浏览器地址栏,显示403状态码。这时点击返回原始网页中点击图片,进入大图模式,然后再在浏览器地址栏复制地址查看图片,发现可以成功显示图片。
2、爬取高清原图
先附上爬取原图的代码。
import requests
if __name__ == "__main__":
# step 1: 指定url
url = 'https://i.pximg.net/img-original/img/2020/09/19/02/56/19/84460298_p0.jpg'
headers = {
'referer': 'https://www.pixiv.net/artworks/84460298',
'user-agent':'你的user-agent'
}
# step 2:发起请求
res_data = requests.get(url, headers = headers)
# step 3: 存储数据
res_code = res_data.status_code
msg = '下载成功!'
if res_code == 200 : # 请求成功
img_data = res_data.content
# 存储数据
img_path = './img/5.png'
with open(img_path, 'wb') as fp:
fp.write(img_data)
print(msg)
else: # 请求失败
msg = "下载失败,返回状态码为:"+str(res_code)
print(msg)
根据上面已经获取了原图地址,在请求原图的过程中需设置headers的referer参数,否则请求不成功。
对于请求,可能存在不成功的情况,可以根据返回的状态码进行判断。如果状态为200,那么说明ok,请求成功,否则说明请求不成功,打印状态码信息。
四、批量爬取高清原图
上述爬取单张图片相比于“”手动右键另存为“,实在耗时费力且非但没有体现任何爬虫的优势。但是如果喜欢这个网站的大多数图片,并希望可以全部保存到本地,手动就太繁琐机械了,使用爬虫可以方便且快速地实现这个操作。
1、分析原图地址
由上一小节可知,这里是直接通过查看图片地址,然后获取多张图片。要获取多张图片,那么一种方法是记录下所有的图片地址并保存到文件,通过读取文件中的图片地址下载图片;另一种方式是分析图片地址的逻辑、构成、关系。显然后者更为科学与便捷。通过右击多张图片,获取如下图片地址:
-
https://i.pximg.net/img-original/img/2020/09/20/19/00/02/84495797_p0.jpg
-
https://i.pximg.net/img-original/img/2020/09/19/18/00/29/84470884_p0.jpg
-
https://i.pximg.net/img-original/img/2020/09/20/06/17/10/84484828_p0.png
-
https://i.pximg.net/img-original/img/2020/09/19/00/00/44/84457006_p0.jpg
以第一张图片地址为例,发现该地址前面的”
https://i.pximg.net/img-original/img/
“以及后面的”
_p0.jpg
“为公共部分,仅有中间的”
2020/09/19/18/00/29/84470884
“与其他图片地址不同。
通过查看network中XHR的Preview来查看每条xhr信息的主题内容,获知以下图片内容。

上图中的json数据中包含了不同的图片信息,比如最后一条的key参与构成原图地址和referer,且里面url的内容为原图的缩略图地址,具有原图特殊部分的信息。因此,可以通过解析该json数据来构造原图的url。
2、构造原图地址
首先找到该preview对应的xhr信息,然后复制request url,进行请求访问,编码实现如下:
import requests
import json
import pprint
if __name__ == "__main__":
# step 1: 指定url
url = 'https://www.pixiv.net/ajax/user/10797546/illusts?ids%5B%5D=84243244&ids%5B%5D=84089827&ids%5B%5D=83931617&ids%5B%5D=83817260&ids%5B%5D=83774711&ids%5B%5D=83630300&ids%5B%5D=83447790&ids%5B%5D=83294064&ids%5B%5D=83293792&ids%5B%5D=82883638&ids%5B%5D=82210044&ids%5B%5D=81883995&ids%5B%5D=81415445&ids%5B%5D=80789668&ids%5B%5D=79598338&ids%5B%5D=79218284&ids%5B%5D=78917052&ids%5B%5D=78768898&ids%5B%5D=78711808&lang=zh'
headers = {
'accept':'application/json',
'accept-encoding':'gzip, deflate, br',
'accept-language':'zh-CN,zh;q=0.9,en-US;q=0.8,en;q=0.7',
'cookie':'你的cookie',
'referer': 'https://www.pixiv.net/artworks/84460298',
'sec-fetch-dest':'empty',
'sec-fetch-mode':'cors',
'sec-fetch-site':'same-origin',
'user-agent':'你的user-agent',
}
# step 2:发起请求
res_data = requests.get(url, headers = headers)
# step 3: 查看请求结果
res_json = res_data.json()
pprint.pprint(res_json)
运行结果如下所示:
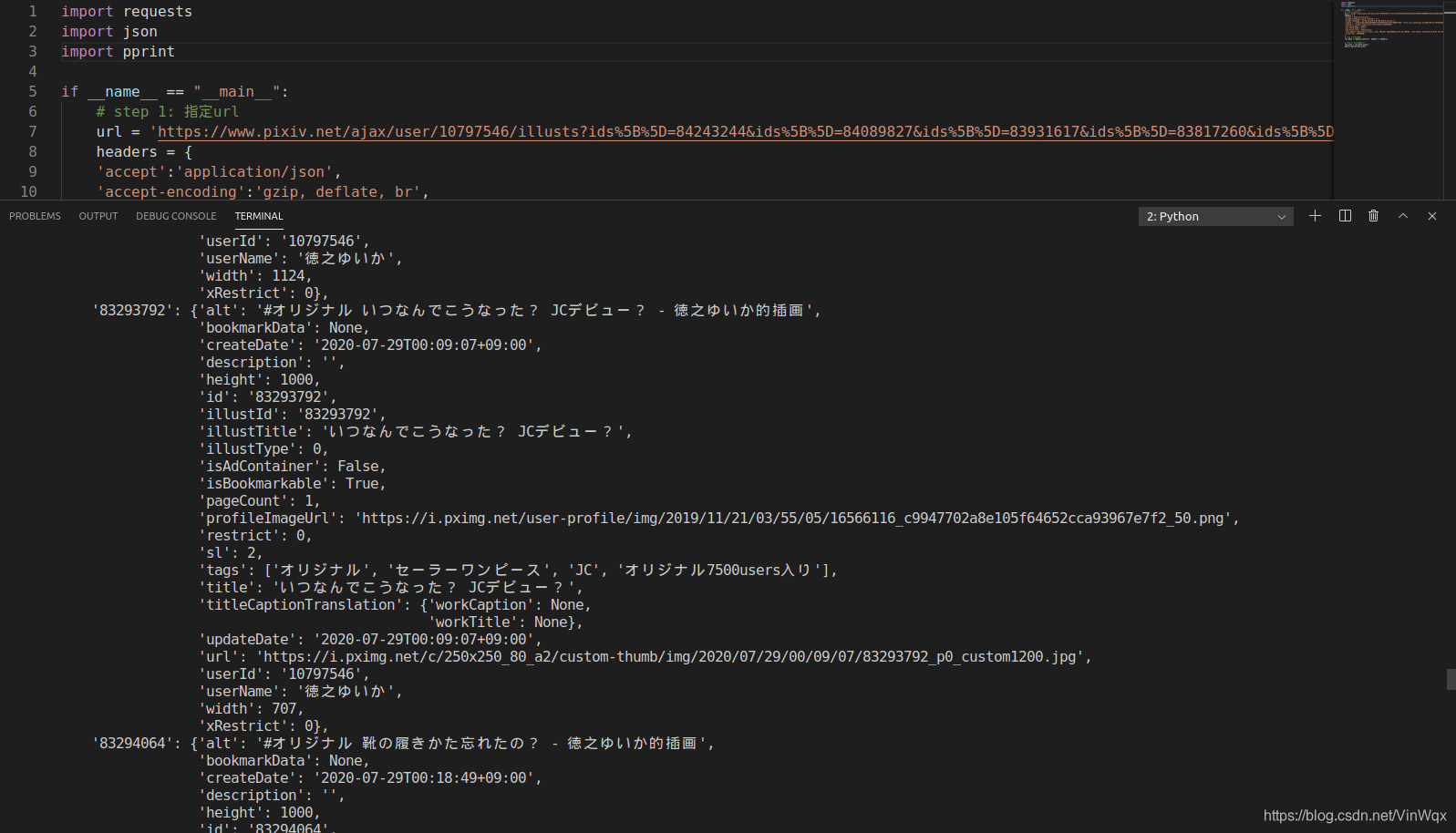
由此可知,该request url就是json数据对应的接口地址,通过访问该地址,返回所需要的包含图片信息的json数据。
根据显示的json数据,可知其中包含了不止一个的图片信息,通过解析请求结果可以构造多个图片地址。请求结果返回的数据为字典类型的数据,真正有用到的是body中的内容。首先或许结果数据的body部分,然后通过list方法可以获取字典所有的key,即图片的id。通过定义两个数组分别为origin_url_list和origin_title_list,分别保存所有的原图地址和原图名称。通过直接取值的方式获取图片的title并添加到列表中,通过正则表达式解析缩略图的地址来获取原图中的特殊部分,然后进行字符串拼接获得原图地址。最后可以通过打印的方式,检查构造的数据是否正确。
# step 3: 解析json数据
res_json = json_res_data.json()
res_json_body = res_json['body'] # 获取json中的body内容
id_list = list(res_json_body) # 获取body中的所有的key,即图片id
origin_url_list = [] # 保存所有的原图地址
origin_title_list = []
# step 4: 构造原图地址
for item in id_list:
# 获取title
origin_title_list.append(res_json_body[item]['title'])
# 通过获取缩略图地址构造原图地址
thumbnail_url = res_json_body[item]['url']
origin_specail_part = re.findall('img/(.*?)_p0',thumbnail_url)[0]
origin_url_list.append("https://i.pximg.net/img-original/img/%s_p0.jpg" % origin_specail_part)
# step 4: 打印查看结果是否正确
i = -1
for item in origin_url_list:
# 更新索引
print(origin_title_list[i])
print(id_list)
print(item)
print()
结果如下图所示:
3、批量爬取原图
经过上述步骤,可以获得图片的网址、标题、referer参数涉及到的图片id等信息,然后根据这些信息,发起请求访问,然后保存图片至本地即可。至此,批量爬取图片成功!
代码如下:
import requests
import pprint
import json
import re
if __name__ == "__main__":
# step 1: 指定url
json_url = 'https://www.pixiv.net/ajax/user/10797546/illusts?ids%5B%5D=84243244&ids%5B%5D=84089827&ids%5B%5D=83931617&ids%5B%5D=83817260&ids%5B%5D=83774711&ids%5B%5D=83630300&ids%5B%5D=83447790&ids%5B%5D=83294064&ids%5B%5D=83293792&ids%5B%5D=82883638&ids%5B%5D=82210044&ids%5B%5D=81883995&ids%5B%5D=81415445&ids%5B%5D=80789668&ids%5B%5D=79598338&ids%5B%5D=79218284&ids%5B%5D=78917052&ids%5B%5D=78768898&ids%5B%5D=78711808&lang=zh'
json_url_headers = {
'accept':'application/json',
'accept-encoding':'gzip, deflate, br',
'accept-language':'zh-CN,zh;q=0.9,en-US;q=0.8,en;q=0.7',
'cookie':'你的cookie',
'referer': 'https://www.pixiv.net/artworks/84460298',
'sec-fetch-dest':'empty',
'sec-fetch-mode':'cors',
'sec-fetch-site':'same-origin',
'user-agent':'你的user-agent',
'x-user-id':'你的user-id',
}
# step 2:发起请求
json_res_data = requests.get(json_url, headers = json_url_headers)
# step 3: 解析json数据
res_json = json_res_data.json()
res_json_body = res_json['body'] # 获取json中的body内容
id_list = list(res_json_body) # 获取body中的所有的key,即图片id
origin_url_list = [] # 保存所有的原图地址
origin_title_list = []
# step 4: 构造原图地址
for item in id_list:
# 获取title
origin_title_list.append(res_json_body[item]['title'])
# 通过获取缩略图地址构造原图地址
thumbnail_url = res_json_body[item]['url']
origin_specail_part = re.findall('img/(.*?)_p0',thumbnail_url)[0]
origin_url_list.append("https://i.pximg.net/img-original/img/%s_p0.jpg" % origin_specail_part)
# step 4: 遍历origin_url_list爬取图片
i = -1
for item in origin_url_list:
# 更新id列表索引
i = i+1
# 获取地址
origin_url = item
# 设置headers
origin_url_headers = {
'referer': 'https://www.pixiv.net/artworks/%s' % str(id_list[i]),
'user-agent':'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.125 Safari/537.36'
}
# 发起请求
img_res = requests.get(origin_url, headers=origin_url_headers)
img_res_data = img_res.content
img_res_code = img_res.status_code
if img_res_code == 200: # 如果请求成功
# 存储图片
img_save_name = str(origin_title_list[i])+".png"
with open("./img/"+img_save_name, 'wb') as fp:
fp.write(img_res_data)
msg = img_save_name+"保存成功!"
print(msg)
else: # 否则输出状态码
msg = "下载失败!状态码为:"+ img_res_code
print(msg)
保存结果如下图:

写在最后:
1、本文的图片爬取在
博主so long
引导下完成,并参考了其博客
P站爬虫,分析过程批量爬取原图png
。
2、如果读者你觉得有帮助,可以点亮下方的小拇指,因为博主会很开心你喜欢。










{kind=link}
{kind=link}
{kind=link}
{kind=link}