1.文本存储
import requests
from pyquery import PyQuery as pq
url = 'https://www.zhihu.com/explore'
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36'
}
html = requests.get(url, headers=headers).text
doc = pq(html)
items = doc('.ExploreCollectionCard-contentItem').items()
for item in items:
question = item.find('a').text()
answer = pq(item.find('.ExploreCollectionCard-contentExcerpt').html()).text()
file = open('explore.txt', 'a', encoding='utf-8')
file.write('\n'.join([question, answer]))
file.write('\n' + '=' * 50 + '\n')
file.close()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
这里open()方法的第一个参数即要保存的目标文件名称,第二个参数为a,代表以追加方式写入到文本。
我们用requests提取知乎的“发现”页面,然后将热门话题的问题、回答者、答案全文提取出来,然后利用Python提供的
open()
方法打开一个文本文件,获取一个文件操作对象,这里赋值为
file
,接着利用
file
对象的
write()
方法将提取的内容写入文件,最后调用
close()
方法将其关闭,这样抓取的内容即可成功写入文本中了。
打开方式
关于文件的打开方式,还有其他几种:

简化写法
使用
with as
语法。在
with
控制块结束时,文件会自动关闭,所以就不需要再调用
close()
方法了。这种保存方式可以简写如下:
with open('explore.txt', 'a', encoding='utf-8') as file:
file.write('\n'.join([question, answer]))
file.write('\n' + '=' * 50 + '\n')
如果想保存时将原文清空,那么可以将第二个参数改写为w,代码如下:
with open('explore.txt', 'w', encoding='utf-8') as file:
file.write('\n'.join([question, author, answer]))
file.write('\n' + '=' * 50 + '\n')
2.JSON文件存储
在JavaScript语言中,一切都是对象。因此,任何支持的类型都可以通过JSON来表示,例如字符串、数字、对象、数组等。
对象
它在JavaScript中是使用花括号{}包裹起来的内容,数据结构为{key1:value1, key2:value2, …}的键值对结构。在面向对象的语言中,key为对象的属性,value为对应的值。键名可以使用整数和字符串来表示。值的类型可以是任意类型。
一个JSON对象可以写为如下形式:
[{
"name": "Bob",
"gender": "male",
"birthday": "1992-10-18"
}, {
"name": "Selina",
"gender": "female",
"birthday": "1995-10-18"
}]
[{'birthday': '1992-10-18', 'gender': 'male', 'name': 'Bob'},
{'birthday': '1995-10-18', 'gender': 'female', 'name': 'Selina'}]
由中括号包围的就相当于列表类型,列表中的每个元素可以是任意类型,这个示例中它是字典类型,由大括号包围。
JSON可以由以上两种形式自由组合而成,可以无限次嵌套,结构清晰,是数据交换的极佳方式。
2.1 读取JOSN
我们可以调用库的
loads()
方法将JSON文本字符串转为JSON对象,可以通过
dumps()
方法将JSON对象转为文本字符串。
import json
str = '''
[{
"name": "Bob",
"gender": "male",
"birthday": "1992-10-18"
}, {
"name": "Selina",
"gender": "female",
"birthday": "1995-10-18"
}]
'''
print(type(str))
data = json.loads(str)
print(data)
print(type(data))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
<class 'str'>
[{'name': 'Bob', 'gender': 'male', 'birthday': '1992-10-18'}, {'name': 'Selina', 'gender': 'female', 'birthday': '1995-10-18'}]
<class 'list'>
with open('data.json', 'w') as f:
f.write(str)
这里使用
loads()
方法将字符串转为JSON对象。由于最外层是中括号,所以最终的类型是列表类型。
这样一来,我们就可以用索引来获取对应的内容了。例如,如果想取第一个元素里的
name
属性,就可以使用如下方式:
data[0]['name']
data[0].get('name')
'Bob'
两种方法得到的结果是一样的,这里推荐使用get()方法, 这样如果键名不存在,则不会报错,会返回None。另外,get()方法还可以传入第二个参数(即默认值),示例如下:
print(data[0].get('age'))
data[0].get('age', 25)
None
25
这里我们尝试获取年龄age,其实在原字典中该键名不存在,此时默认会返回None。如果传入第二个参数(即默认值),那么在不存在的情况下返回该默认值。
需要注意的是,JSON的数据需要用双引号来包围,不能使用单引号。例如,若使用如下形式表示,则会出现错误:
import json
str = '''
[{
'name': 'Bob',
'gender': 'male',
'birthday': '1992-10-18'
}]
'''
data = json.loads(str)
json.decoder.JSONDecodeError: Expecting property name enclosed in double quotes: line 3 column 5 (char 8)
千万注意JSON字符串的表示需要用双引号,否则loads()方法会解析失败。
如果从JSON文本中读取内容,例如这里有一个data.文本文件,其内容是刚才定义的JSON字符串,我们可以先将文本文件内容读出,然后再利用loads()方法转化:
import json
with open('data.json') as file:
str = file.read()
data = json.loads(str)
print(data)
[{'name': 'Bob', 'gender': 'male', 'birthday': '1992-10-18'}, {'name': 'Selina', 'gender': 'female', 'birthday': '1995-10-18'}]
2.2 输出JSON
我们可以调用
dumps()
方法将JSON对象转化为字符串:
import json
data = [{
'name': 'Bob',
'gender': 'male',
'birthday': '1992-10-18'
}]
with open('data.json', 'w') as f:
f.write(json.dumps(data))
利用
dumps()
方法,我们可以将JSON对象转为字符串,然后再调用文件的
write()
方法写入文本
如果想保存JSON的格式,可以再加一个参数
indent
,代表缩进字符个数:
with open('data.json', 'w') as file:
file.write(json.dumps(data, indent=2))
如果JSON中包含中文字符,中文字符就变成了Unicode字符:
import json
data = [{
'name': '王伟',
'gender': '男',
'birthday': '1992-10-18'
}]
with open('data.json', 'w') as file:
file.write(json.dumps(data, indent=2))
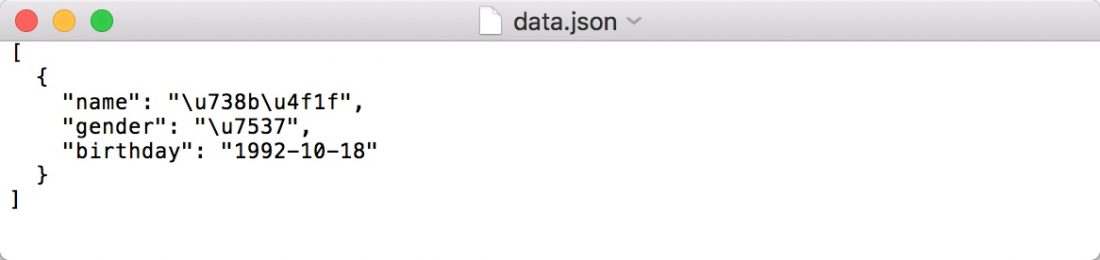
为了输出中文,还需要指定参数
ensure_ascii
为
False
,另外还要规定文件输出的编码:
with open('data.json', 'w', encoding='utf-8') as file:
file.write(json.dumps(data, indent=2, ensure_ascii=False
))
3.CSV文件存储
CSV,全称为Comma-Separated Values,中文可以叫作逗号分隔值或字符分隔值,其文件以纯文本形式存储表格数据。该文件是一个字符序列,可以由任意数目的记录组成,记录间以某种换行符分隔。每条记录由字段组成,字段间的分隔符是其他字符或字符串,最常见的是逗号或制表符。不过所有记录都有完全相同的字段序列,相当于一个结构化表的纯文本形式。所以,有时候用CSV来保存数据是比较方便的。
3.1 写入
import csv
with open('data.csv', 'w') as csvfile:
writer = csv.writer(csvfile)
writer.writerow(['id', 'name', 'age'])
writer.writerow(['10001', 'Mike', 20])
writer.writerow(['10002', 'Bob', 22])
writer.writerow(['10003', 'Jordan', 21])
首先,打开data.csv文件,然后指定打开的模式为
w
(即写入),获得文件句柄,随后调用
csv
库的
writer()
方法初始化写入对象,传入该句柄,然后调用
writerow()
方法传入每行的数据即可完成写入。
如果想修改列与列之间的分隔符,可以传入
delimiter
参数,其代码如下:
import csv
with open('data.csv', 'w') as csvfile:
writer = csv.writer(csvfile, delimiter=' ')
writer.writerow(['id', 'name', 'age'])
writer.writerow(['10001', 'Mike', 20])
writer.writerow(['10002', 'Bob', 22])
writer.writerow(['10003', 'Jordan', 21])
我们也可以调用
writerows()
方法同时写入多行,此时参数就需要为二维列表,例如:
import csv
with open('data.csv', 'w') as csvfile:
writer = csv.writer(csvfile)
writer.writerow(['id', 'name', 'age'])
writer.writerows([['10001', 'Mike', 20], ['10002',
'Bob', 22], ['10003', 'Jordan', 21]])
在csv库中也提供了字典的写入方式,示例如下:
import csv
with open('data.csv', 'w', newline='') as csvfile:
fieldnames = ['id', 'name', 'age']
writer = csv.DictWriter(csvfile, fieldnames=fieldnames)
writer.writeheader()
writer.writerow({'id': '10001', 'name': 'Mike', 'age': 20})
writer.writerow({'id': '10002', 'name': 'Bob', 'age': 22})
writer.writerow({'id': '10003', 'name': 'Jordan', 'age': 21})
如果要写入中文内容的话,可能会遇到字符编码的问题,此时需要给open()参数指定编码格式:
import csv
with open('data.csv', 'a', newline='', encoding='utf-8') as csvfile:
fieldnames = ['id', 'name', 'age']
writer = csv.DictWriter(csvfile, fieldnames=fieldnames)
writer.writerow({'id': '10005', 'name': '王伟', 'age': 22})
3.2 读取
我们同样可以使用csv库来读取CSV文件:
import csv
with open('data.csv', 'r', encoding='utf-8') as csvfile:
reader = csv.reader(csvfile)
for row in reader:
print(
row)
['id', 'name', 'age']
['10001', 'Mike', '20']
['10002', 'Bob', '22']
['10003', 'Jordan', '21']
['10005', '王伟', '22']
使用pandas的话,可以利用read_csv()方法将数据从CSV中读取出来,例如:
import pandas as pd
df = pd.read_csv('data.csv')
print(df)
id name age
0 10001 Mike 20
1 10002 Bob 22
2 10003 Jordan 21
3 10005 王伟 22









