Julia 语言是近年来科学世界中出现的一匹黑马。物理学家 Lee Phillips 发表了一篇高质量的科普,介绍了这种科学计算语言的真正魅力所在。

图片来源:Unsplash
本文转载自公众号“数据实战派”
撰文 Lee Phillips,物理学家
翻译 REN
最近,我和许多科学家在网上视频见面了很多次,他们对一个新工具感到兴奋。它既不是最新的粒子加速器,也不是超级计算机,而是一种年轻的计算机语言 ——Julia。
不同的计算机语言擅长的工作也不一样,有的运行速度很快,有的则更容易开发和部署,有的拥有庞大的生态系统和库,有的则适用于解决特定问题。
对于需要模拟气候变化或核聚变的科学家来说,目前的主流语言是 Fortran。它的编译器可以充分利用大型超级计算机的强大性能。而对于数据科学家来说,Python 才是最受青睐的语言,因为它拥有丰富的生态系统,强大的交互性和快速的开发周期。
六年前,我撰文描写了 Fortran 在科学计算领域的地位,并与其他几种语言进行了比较。在文章结尾处我曾预测:十年后,一种名为 Julia 的新语言很可能取而代之,成为科学家在解决大规模数字计算问题时更愿意使用的语言。
我的预言不是很准确,因为 Julia 只用了大约一半的时间,就接近了这一目标。
通过近年与许多科学家的交流,我确信,Julia 在业界掀起了新的热情。不过,当年分析它的潜力时,我还不明白为什么这种语言会如此受欢迎。
当时,我的评估是基于 Julia 独特的便捷语法与出色性能。尽管 Julia 1.0 正式版尚未发布,但整个社区已经非常兴奋。
Julia 似乎已经解决了 “两语言问题(two-language problem)”,这是 Python 等解释性语言用户经常面临的难题。用 Python 编写一个程序,虽然可以享受它的便捷语法和交互性,但当计算规模扩大到一定程度,程序的运算速度就会放慢很多。这是 Python 语言本身的局限性。
对于大型的仿真模拟运算来说,由于数据量过于庞大,程序的运行速度至关重要,因此研究人员不得不用 C 之类的语言再重写一个一样的程序,以提升实际应用时的运行速度。可是速度上来之后,他们在后续研究中又要同时维护和更新两种语言的代码。“两语言问题” 由此而生。
Julia 自诞生起就以解决 “两语言问题” 作为使命,以此吸引科学家和其他人来学习该语言,不过这并不是它唯一令人兴奋的地方。
以今年的 JuliaCon 大会为例,普通的计算机会议大多围绕编程、编译器、算法和优化等计算机科学主题展开。虽然 JuliaCon 上也有这些,但更多的是围绕科学研究课题,比如流体力学、语言处理、大脑成像等等。这些演讲题目给人一种走进了科学研究大会的错觉。
这种百花齐放的情况得益于 Julia 编程社区的开放态度,每个人的代码都可以在 GitHub 上找到。如果有人希望使用现成的算法,从帮助文档到代码注释,都可以拿到最新版本。
这与绝大多数年龄较大的科学家所熟悉的氛围完全不同:在过去,科研代码几乎不会离开实验室。
Julia 社区正是以大规模的协作和代码共享为基石。
解决 “表达问题”
“表达问题(Expression Problem)” 是计算机语言设计研究中的常见概念。它是计算机科学的分支研究领域,人们对它的含义和解释往往十分抽象,并且依赖于专业术语。
如果想要更好地理解这个概念,我们或许可以将其类比成烹饪。
首先我们要明确一些计算机科学术语,包括函数 / 程序、数据类型和库 / 模块 / 包。
简单来说,函数 / 程序指的是 “获取输入值,对其进行处理,最后产生输出值” 的过程。数据类型是数字、字符或其他信息的集合,这些信息有各式各样的结构,可以由函数操控。库 / 模块 / 包则是函数的集合,还包括函数使用的数据类型的描述。
接下来我们开始类比。
如果你知道食谱和烹饪是什么意思,这个类比就很好懂。我们可以将库 / 模块 / 包视为市面上出售的 “食谱书”,函数 / 程序就是 “制作菜肴的完整过程或技术”,而数据类型就是需要用到的 “食材或配料”。
现在想象一下食谱的内容。一般来说,食谱都是以不同菜品为分类,比如炒菜实际上细分为如何炒洋葱,如何炒虾等等。每一道菜的步骤不同,因为它们使用的食材或配料不同。这些食材和配料表也是食谱的一部分。
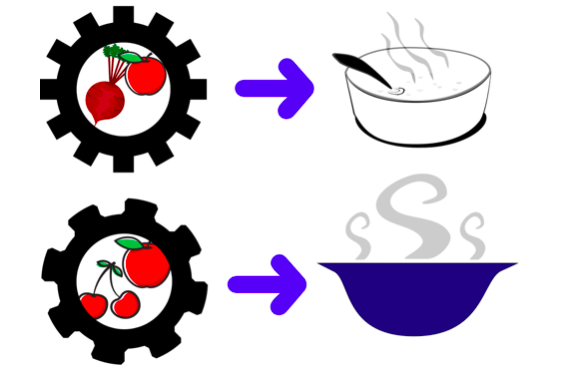
菜品烹饪需要特定食材和配料。图片来源:Lee Phillips
如果我们要添加一道新菜,那只需要囊括所有涉猎到的食材或配料就可以了,其他现有的菜品都不需要任何改动 —— 新菜不会让旧菜失效。

添加新菜不会影响旧菜。图片来源:Lee Phillips
但如果我们想加入新的配料或食材怎么办?比如现有菜品制作过程中没有用到鱼,那么我们就需要修改现有的制作过程。

但要添加新的食材,就要改变现有菜谱。图片来源:Lee Phillips
不过,组织食谱书的方法有很多,另一种方法是围绕食材来组织书谱,而不是烹饪方法。每个食材,都会有配套的烹饪技术和方法。就像下图所示:
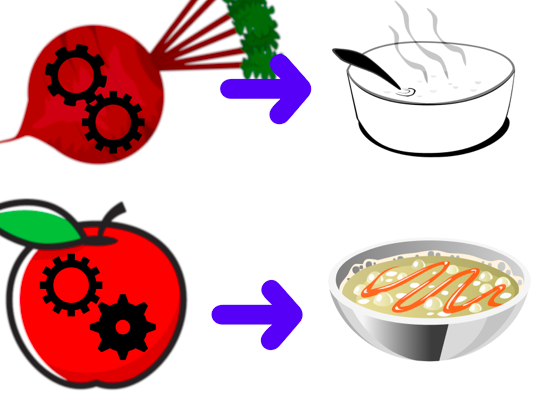
以食材为核心来组织菜谱。图片来源:Lee Phillips
在这种情况下,烹饪技术就不再是独立存在的,而是与所使用的食材相关联。如果要新添加鱼作为新的食材,就可以编写一个新的鱼的制作方法,与现有的鱼类烹饪方法整合在一起。

这样一来,添加新食材就不用改变现有菜谱。图片来源:Lee Phillips
但如果想添加一种新烹饪技术呢?比如如何使用搅拌机?
在不更改现有工作的情况下,我们没有办法实现。因为现有技术已经绑定在食材上,新烹饪技术必然会改变食材的制作方法。
这两种食谱的组织方式类似于两种计算机语言类型。围绕烹饪过程的食谱书是 “面向过程的语言”,而围绕食材的食谱书则是 “面向对象的语言”。两种语言各有千秋。
这其实就是 “表达问题”:无论哪种语言,都存在扩展软件(食谱)的障碍。在重用和组合现有代码时,能否不更改现有已存在的软件包至关重要。
如果你觉得前面的类比还不够清楚,接下来这一节还有另一种更直观的解释。
引入 “多重调度”
显而易见的是,若有一种无论什么情况下都不用更改已有内容的方式来组织食谱,就可以获得极大的扩展自由度,那将是一个很大的优势。
与其严格遵照制作过程和食材来组织食谱,不如采用一种更通用且灵活的方法。如下图所示:

看起来杂乱的新菜谱组合方式,允许更大的自由度。图片来源:Lee Phillips
这张图片显示了方法与食材的自由关联,谁都不是另外一个的附属品。但这不代表能随机组合无关的方法,而是要基于现有方法创建变种,并与不同的食材配套。
举个例子,我们现有的食谱书包含了炸鸡的烹饪过程。如果想添加煎鱼的过程,也不需要重新编写,只需要指导读者用炸鸡的方式煎鱼,但要使用更高的温度,并且将配料更早的剔除。
另一种审视三种思维模式的方法是想一想 “食谱的目录”。
在 “面向功能” 的版本中,目录可能是这样的:
在这种情况下,添加新功能只需要新开一章,但添加新的食材(比如鸡蛋)需要修改现有章节:在第一章添加煎蛋,第二章添加水煮蛋等等。
在 “面向对象” 的版本中,目录可能是这样的:
- 第一章:鸡
煎炸
水煮
- 第二章:鱼
煎炸
水煮
在这种情况下,添加新食材只需要新开一章,但添加新的烹饪方法(比如烤)需要修改现有章节:在第一章添加烤鸡,第二章添加烤鱼等等。
至于第三种方法,秉承可最大程度扩展食谱的思想,目录可能是这样的:
- 第一章:炸鸡
- 第二章:水煮鸡
- 第三章:炸鱼
- 第四章:水煮鱼
很显然,无论是食材还是烹饪技术,都能作为新章节自由添加到书中,无需修改任何现有章节:第五章烤鸡,第六章烤鱼等等。
与前两个版本相比,第三种模式似乎没有组织性。
但在实际操作中,烹饪方法和食材之间的关系可以成为库结构的一部分。在食谱类比的语境中,我们可以想象鸡和鱼是肉的子集,草莓和樱桃是红色水果的子集,而煎炒和水煮则是更大的通用烹饪方法的变体,以此类推。
这种思维模式是解决 “表达问题” 的一种尝试。这在语言设计中也被称为 “多重调度”,指的是基于要应用的所有数据类型的类型自动选择方法。
“多重调度” 是 Julia 解决 “表达问题” 的方法,也是其核心组织原则,因此 Julia 既不是面向对象的,也不是面向功能的。它采用的解决方法比两者更强大,更通用。这意味着 Julia 在混合和使用库方面更加自由。
工具的重要性
Julia 不是第一个尝试解决 “表达问题” 的语言,也不是第一个用到 “多重调度” 的语言。拥有该功能的 Common Lisp 语言已经诞生 40 年,Perl 等语言的最新版本也拥有该功能。用户已经肯定了 “多重调度” 在编写和扩展库方面的便利性。
但 Julia 与它们的区别在于,Julia 是围绕 “多重调度” 设计的,而其他语言只是将其作为可选项,并且会带来性能损失。比如 Julia 的 “多重调度” 允许其更灵活和自然地表达数学思维,其社区代码重用量让语言设计者都感到惊讶。
不过想在科学界立足,有了上述优势还不够。Julia 之所以受到了大量关注,还在于它将 “多重调度” 和其他特性相结合,比如快速上手的免费高质量代码和非常快的运算速度,对需要大量数字运算的科学家非常有吸引力。
斯坦福大学教授 Mykel Kochenderfer 使用 Julia 设计了避免飞机碰撞的系统,该系统已成为国际标准。他表示,Julia 不仅 “是高级的,可被解释的语言,而且它的运行速度也与高度优化的 C ++ 代码一样快。”
Julia 还具有表达力强,易于阅读的语法,尤其是在处理数组时。它为数字算法的并行处理提供了一条快速通道。它具有 Unicode 时代的设计优点,使其在表述数学公式时更像真正的数学。
下面这幅图片是 Julia 程序中的实际代码,使用了专门为 Julia 语言设计的字体。
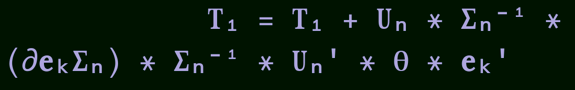
Julia 语言的数学公式表达。图片来源:Lee Phillips
Julia 的这些特性在早期就吸引了许多科学家,甚至在 “多重调度” 的特殊优势引发关注之前,就已经吸引了大量用户。
而我从中所学到的核心思想是:工具很重要。这就好比,画家作画时要选好符合作品风格的画笔和颜料,而作曲家脑海中的音律必须与乐器和表演者的技巧相吻合。
作为一个编程工具,Julia 之于科学家也是一样。它能扩展科学家在有限时间内能够完成的任务,帮助其实现未曾想象过的想法。
参考来源:
[1] The unreasonable effectiveness of the Julia programming language
https://arstechnica.com/science/2020/10/the-unreasonable-effectiveness-of-the-julia-programming-language/
扩展阅读:
忘了Python和Fortran吧,科学家开始用Julia了
本文转载自公众号“数据实战派”(ID:gh_ff93f845912e),原标题为“深度解读Julia丨不是超算、粒子加速器,一种编程语言同样能征服科学世界”。数据实战派致力于专业解读人工智能领域前沿技术发展、分享实战技术案例,同时提供人工智能和神经科学的交叉学科深度内容。





