原文翻译自:https://blog.bigchaindb.com/blockchain-infrastructure-landscape-a-first-principles-framing-92cc5549bafe
Ethereum,IPFS/Filecoin,和BigChainDB是如何实现互相补充的呢?那Golem,Polkadot或Interledge又是如何的呢。我经常问我自己这样的问题。所以我打算写篇文章来阐述自己的,第一性原理框架,并来回答这些问题。
简短的答案是:没有一个叫“区块链”的银弹,它能神奇的做所有的事情。相反,这里有的是非常好的实现图灵完备的各种各样的组件,你可以使用它们来搭建有效率的去中心化应用。以太坊可以参与其中,BigchainDB可以,所有其它组件也都可以,我们来一起看看...
背景
组成一个程序的要素有存储,计算和通信。大型机,个人电脑,手机和云计算,每一个都以自己独特的方式来表达了这些组成元素。专用于某一方面的组件出现来与其它组件合作来达到我们想要的结果。
举例来说,在存储元素中,我们可以选择文件系统和数据库系统组件。文件系统使用层级式的目录,存储像mp3这样的二进制的大对象,而数据库则用来存储结构化的元数据,通过SQL这样的语言来进行操作。在中心化的云上,我们则会使用Amazon
S3来进行二进制大对象的存储,使用MongoDB做为数据库存储,而使用Amazon EC2来做为计算服务器。
本文将聚集于区块链的技术概貌:程序用到的每个要素的相关组件,对应组件的实际项目的例子。对于每个组件,我会尽量的全面阐述。
区块链的一些基本组件
下面是程序的基本要素中,每个要素对应到块(译者注:核心职责,价值):
区块链基础设施概貌
每一个组件中的对应的区块链技术如下:
程序的三要素,及对应的组件,示例项目,去中心化版(后附原图,对比看,更清晰)
| 存储 | 计算 | 通信 |
|---|
代币存储
Bitcoin,Zcach,.* | 有状态的业务逻辑
Ethereum,Lisk,Rchain,Eos,Tezos,...客户端计算(JS,Swift) | 数据
TCP/IP,HTTP |
文件系统或二进制数据
IPFS/FileCoin,Eth Swarm,Storj,Sia,Tieron,LAFS | 无状态的业务逻辑
加密币条件(如BigchainDB),Bitshares,及所有的有状态的业务逻辑 | 价值
Interledger,Cosmos |
数据库
BigchainDB + IPDB,IOTA | 高性的运算
TrueBit,Golem,Iex.ec,Nyriad,VMs,客户端计算 | 状态
PolkaDot,Aeternity |

存储
程序中最基本的元素,存储,有下述一些可用的组件:
代币存储:代币存储的是价值(资产或安全)。无论这个价值是比特币,飞行里程,艺术品的电子版权。一个代币存储系统的主要操作就是发行和转移代币(满足各种各样的条件下),系统需要保证不会双花等。
比特币和Zcash是两个专注于代币存储的纯粹系统。以太坊恰好使用它的代币达到了世界计算机的目标(译者注:由于以太坊是图灵完备的,愿景是成为永不停机的世界计算机,但现在大多数人用它来进行代币的发行,作者在这里是一种调侃吧)。上述这些是代币被用来作为内部激励,驱动整个网络基础设施。
其它一些代币没有集成于整个网络内来驱动整个网络,而是用来激励更高层级的网络,但底层基础架构实际存储着对应的代币。一个例子是运行于以太坊主网上的ERC20标准的Golem(GNT)。另一个例子是运行在IPDB上的EnvokeIP授权代币。
最后,我使用“.*”来说明大多数的区块链系统都有代币的存储机制。
数据库:数据库专指存储结构化的数据,比如表(关系型数据库),文档存储(比如,JSON),键值对存储,时间序列或图;然后可以通过快速查询语言(比如:SQL)进行数据搜索。
传统的分布式(但中心化)数据库比如Mongo和Cassandra经常存储TB,甚至PB级的数据,而写性能能超过1000000每秒,正如这里(https://medium.com/netflix-techblog/benchmarking-cassandra-scalability-on-aws-over-a-million-writes-per-second-39f45f066c9e)所述。
查询语言SQL是非常巧妙的,因为他将规范与实现分开,这样它就不再与某种应用绑定。SQL在最近数十年一直是一个标准规范。这也让同样的数据库系统可以横跨不同的工业领域进行使用。
换种思路:如果你想将比特币更广泛的推广到其它的应用,没有任何特定应用程序的代码,你没有必要一定实现图灵完备。你只是需要一个数据库。这将在简单与规模间具有相应的优势。当然实现图灵完备在有些地方仍然是非常有用的;我们后面的关于去中心化的计算章节来更多的讨论一下。
BigchainDB是一个去中心化的软件;专注于文档存储。基于MongoDB(或RethinkDB)之上,它继承了Mongo的查询与扩容功能。但它仍有区块链的特性,比如去中心化的控制,防篡改和代币功能的支持。IPDB是BigchainDB的一个拥有治理功能的公网版本。
同样在区块链领域里,我们可以认为IOTA是一个按时间序列的数据库,如果换一个角度来看的话。
文件系统、二进制数据存储:这些是用来存储大文件(比如电影,mp3,超大数据集),以目录、文件这样的层级结构存储的系统。
IPFS和Tahoe-LAFS是去中心化的文件系统,整合了去中心化和中心化的二进制大对象的存储。FileCoin,Storj,Sia,Tieron实际进行二进制的存储。当然也包括老的BitTorrent,尽管他使用的是针对性的解决方案,而不是代币。以太坊的Swarm,Dat和Swarm-JS也差不多是在做这些。
计算
接下来我们聊聊,程序的第二要素计算。
“智能合约”系统是指使用去中心化方式进行计算的系统。系统可以区分为两大类,无状态(组合)的业务逻辑和有状态(顺序)的业务逻辑。无状态与有状态在复杂上,可验证性等上有着根本的区别。我们还有第三类的去中心化的计算组件:高性能计算(HPC)。
无状态(组合)的业务逻辑:在内部的任何逻辑里都不需要保留状态。
如果用电子工程术语来说的话,它是由数字逻辑回路组成。 逻辑表示为真值表,示意图或代码的条件语句(组合if/then,逻辑与,逻辑或)。
由于它们没有状态,因此很容易验证大型无状态智能合同,并由此构建大型校验/安全系统。 N个输入和一个输出需要O(2 ^ N)次计算来进行验证。
Interledger协议包含一个加密币条件(crypto-conditions aka. CC)协议来清晰的指定组合的回路。因为CC通过IETF成为了互联网的标准协议,同时ILP也正被中心化和去中心化的支付网络(75家银行采用了Ripple的协议)广泛的采纳,所以你最好对之有些了解。CC在JavaScript,Python,Java等都有单独的实现。 BigchainDB,Ripple等系统使用CC; 因此支持组合业务逻辑/智能合同。
由于有状态业务逻辑是无状态逻辑的超集,因此支持状态业务逻辑的系统也支持无状态业务逻辑(牺牲额外的复杂性和可验证性挑战)。
有状态(顺序)的业务逻辑:
任何内部的业务逻辑都有状态。这就是说,他有记忆(译者注:根据经历的形成的不同记忆有不同的选择)。或者是说,它是具有至少一个反馈回路(和时钟)的组合逻辑电路。
例如,微处理器具有根据发送给它的机器码指令进行更新的内部寄存器。 更一般地说,有状态的业务逻辑是图灵机,其接收输入序列,并且返回一系列的输出。
实现了这样逻辑(实际近似)的系统是图灵完备的。
以太坊是最知名的实现了有状态的逻辑和智能合约的链上(on-chain)系统。Lisk,RChain,DFINITY,EOS,Tezos,Fabric,Sawtooth,及很多其它的也实现了。可以运行一个“就在那里,但也可能是任何地方”的代码是非常强大的一个想法,有非常多的使用场景。这也侧面解释为什么以太坊会成功,为什么它的生态系统发展成为一个平台,以及为什么在这个领域里有如此多的竞争。
同时因为序列逻辑是组合逻辑的超集,这样的系统也支持组合逻辑。
有状态的业务逻辑的问题是,代码中的非常小的错误,将引发严重的后果,正如DAO的被黑事件所展示的那样。形式验证可以帮助解决这个问题,正如它在芯片行业所做的那样。以太坊基金正在积极引入形式验证。然后有状态业务逻辑的另一个问题是有规模的限制。对于组合回路,所有的可能的组合是2的所有可能输入的次方。对于有状态逻辑来说,内部状态的数量,假设所有的状态是布尔的,就是2的所有内存状态变量。举例来说,如果你有3种可能的输入,对于组合回路来说就是2的3次方,8种所有的可能。而对于有状态的逻辑来说,如果可改变状态的操作有32种,那么将检查2的32次方,即42亿个状态(译者注:实际的实现不会看起来的这么低效能,这里主要是为了说明复杂性)。这是有状态逻辑的复杂性限制(因为你需要相信这门技术,相信它最终实现的是你真正想要的,否则就会成为一个bug,带来经济损失)。“尽可能正确的创建”是另一种让智能合约可信的一种方法,正如Rchain使用的rho演算(译者注:对于这里,读者应保持自己的观点,图灵完备确实会让写的代码不可控,容易出bug,但它的想像力是比较大的。请保持自己独立思考)。
如果你想使用去中心化的计算,对于许多的情形来说,这里有一个简单的方法:在浏览器或者移动设备,可运行JavaScript和Swift这样的客户端上简单的执行就可以了。这里,你必须要相信在你的客户端上所进行的操作,但由于设备在你的手上,一般你会容易接受这点(译者注:可能会疑惑,平时就是这样做的,为什么要刻意强调。因为这里想说明的是去中心的运算是无信任任何节点,但浏览器的后端确定了,必须要相信现在配置的这个节点)。我们把这叫做胖客户端(https://blog.bigchaindb.com/bigchaindb-version-1-0-released-932bee682266)以区别于胖协议(http://joel.mn/post/148641439498/fat-protocols)框架。这个架构对于主流的web开发者来说非常好理解。举例来说,所有许多的web应用程序都需要状态。要创建这样一个程序,你需要JS + IPDB(使用js-bigchaindb-driver)。又或者你的应用需要使用到二进制的大对象存储或支付,可以包含IPFS的js版本(ipfs.js)和以太坊的js版本(web3.js)。下面是一个例子:

高性能计算(HPC):为渲染,机器学习,电路仿真,天气预报,蛋白质折叠等方面的“重”计算的处理。 计算任务将使用一个机器集群(CPU,GPU,甚至TPU),花上几个小时或甚至几个星期。
有如下的一些去中心化的实现HPC的方式:
Golem和iEx.ec框架整合去中心化的超级电脑的算力与相关的应用程序。
Nyriad作为存储执行。这种计算基于去中心化的存储(对于存储Nyrid也有自己的解决方案)。
TrueBit允许第三方进行计算,然后进行事后的计算检查(如果可能则进行隐式检查;如果有问题,则进行显示的检查)。
而另一些人只是在VM或Docker容器上运行大量计算,并将结果(最终的VM状态快照或刚刚计算的结果)存到一个需要权限才能访问的blob中。
然后,使用代币的方式来售卖访问权限。 这种方法要求更多的客户来验证结果,但好的是,今天所有这些技术都是可能的。
当TrueBit成熟时,这种方式将自然与TrueBit结合。
通信
最后我们将来说明一下程序的第三个要素,通信。通信方式有很多种; 我将专注于连接网络的这个层面。 它有三个层次:数据,价值和状态。
数据:在60年代时,我们有了ARPAnet。它成功的延伸出了类似的网络,如NPL,CYCLADES,随之诞生的问题时,大家不能互相交流。Cerf和Kahn在70年代发明了TCP/IP协议来把大家连在一起。TCP/IP现在是连接网络的事实上的标准。OSI是另一套与之竞争的协议,则显得逊色不少(尽管讽刺的是,它的模型已被证明是有用的)。所以,除了它的发明时间有点长,TCP/IP仍无可争议的是去中心组件的重要一环,用于连接网络中的数据(译者注:IPFS正打算创建一套全新的协议。)。
价值:TCP/IP仅仅提供了在数据层面连接网络。你可以重复发送数据,从而造成一些错误,但底层的TCP/IP协议并不关心这些。但如果你想要通过连接的网络发送资产呢。举例来说,从比特币发到以太坊,或发送到使用国际货币支付框架SWIFT协议的支付网络。你将期望你的代币一次只能转给一个目标(译者注:如果同一份钱,可以转给两个目标,那么这个网络将因为不可靠而失去大家的信任,因为可以双花)。一种连接整个网络,同时防止双花的方式是使用交易所,一种传统的非常重的方式。然而,你可以通过加密托管的方式来抽离交易所的本质,通过自动化的代码来移除对中间人的需要来实现。例如Alice可以通过Mallory向Bob转帐,Mallory中转资金但不能花费它们(资金会有一个超时,从而Mallory也不能永久的持有资金)。这也正是Interledger Protocol(ILP)的内在理念。这与双向锚定的概念类似以及状态通道(如Lighting网络和Raiden网络);但这些网络连接都是100%专注于面向价值的连接(译者注:因为要传输价值,所以建立的网络连接)。除ILP以外,还有Cosmos为了更加方便使用,增加了更多的复杂性。
状态:在通过网络连接价值以外,还有什么呢。想象一下一台计算机病毒,其自己的比特币钱包可以从一个网络跳到另一个网络。或某个以太坊的智能合约,可以移动他的状态到另一个以太坊网络,甚至到另一个匹配的不同网络?或者说,为什么限制AI DAO于某个具体的网络呢?
这正是Polkadot正在做的,连接网络的状态。Aeternity同样适用于价值网络与状态网络间的某个地方。
例子
我们刚回顾了程序的三个主要要素(存储,计算和通信),去中心的组件分类,每个组件内的一些对应的项目。
人们正在基于这些项目的组合来建造项目。有非常多同时组合两个以上的组件,如IPFS + 以太坊或者IPFS + IPDB。但也有同时组合三个及以上的组件。下面有几个前沿的例子:
相关的工作
后面是在区块链社区的其它一些相关的技术框架;所有这些我都与之进行过愉快的交流。
Joel Monegro的胖协议(http://joel.mn/post/148641439498/fat-protocols)框架强调每一个组件都是一个协议。我认为这是一个非常酷的框架,尽管它强制所有组件通过网络协议进行交互。这里还有其它的方式:区块间可以简单的通过一个import导入或库的调用进行通信。
使用import的方式的原因是(a)低延迟。如果通过网络调用,会影响甚至完全让应用不可用;(b)简单。使用库(甚至内嵌代码)总是比连接网络实现上简单,而且也不用花费代币等。(c)更成熟。协议栈的解决方案现在才出现,而现存在大量可使用的库,比如UNIX库,即使Python和JS的模块库也已经有15年的历史了。
Fred Ehrsam的“DAPP开发栈”适用于web的业务模型。它也非常有用,但它并不旨在对于给定的程序元素(例如文件系统与数据库),并在组件之间进行细粒度区分。
BigchainDB白皮书(https://www.bigchaindb.com/whitepaper/bigchaindb-whitepaper.pdf)(第一次发布于2016年2月),为了方便说明,下图给出了一个早期版本的开发栈:
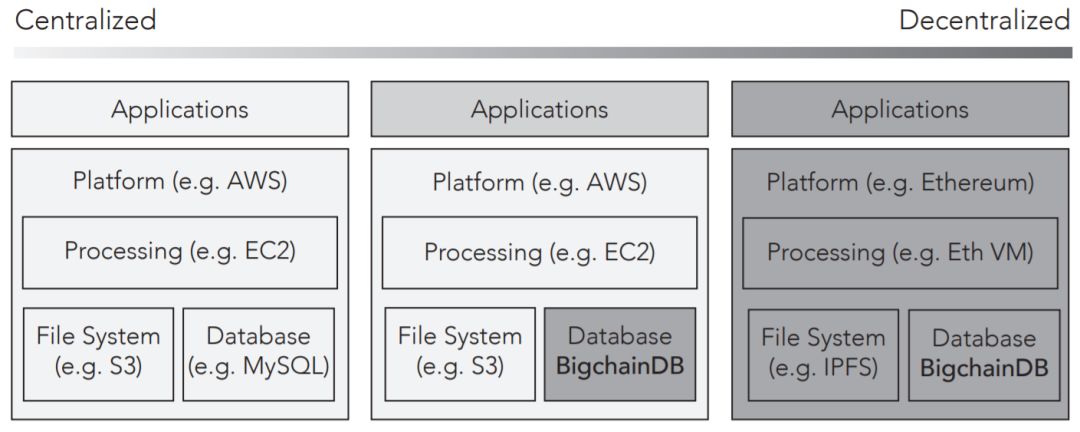
当时的这个版本关注于处理,文件系统,数据库。当时还并没有从程序的要素的角度来清晰划分,同时也没有详细的区分去中心化的计算这块(译者注:上图中,当时版本里面,只有一个模糊的VM)。现在的这个文章,是在当时的白皮书的基础上,经过了1年半的思维革新后;在某些演讲中持续更新后所得,正如5月22号在2017共识大会上的演讲(
http://trent.st/content/20170522%20blockchains%20for%20ai%20-%20consensus%202017.pdf)一样,就已经非常趋同于当前的这篇文章了(写这篇文章的另一个原因是我收到了大量的请求,希望我能用文字的方式将这些记录下来)。
上面这张旧图也强调了一个完全中心化的到一个完全去中心化的转变的解决方案。这可以用来帮助将现存的软件系统更新为更去中心化的系统,关注于更新那些最值得更新的组件就好了。
Stephan Tual的“Web3.0的重访问”(https://blog.stephantual.com/web-3-0-revisited-part-one-across-chains-and-across-protocols-4282b01054c5)提到的技术栈与本文类似,只是它更关注于以太坊相关的技术栈。它尝试将相似的项目归类到某些组件中,并形成一个地图,来服务社区。我非常惊喜想法与我的非常类似。然而文中服务应用的区块层(用于消息通信,存储,共识,治理的区块)混入了三种东西:apps,“什么”,“如何解决”。对我来说,区块是“什么”。所以消息通信是应用(应该属于应用层);而存储层应该更加细粒度的;共识是“如何实现”的那层(隐藏于某些区块里);治理是“如何实现”的另外一部分(因而也是隐藏于区块里的)。它也有[网络]协议作为分离的底层的块,同样我也赞同这是一种区块间,与库函数调用一起,相互通信的方式。尽管如些,我仍认为那是一篇非常好的文章和技术栈说明。
Alexander Ruppert的“去中心化世界的地图”(https://medium.com/birds-view/mapping-the-decentralized-world-of-tomorrow-5bf36b973203)有差不多20个组组成,x轴给出了从基础层到应用层的四个层次,但使用中间件和流动性作为关联性的层级。这也是一件巨作,我很高兴能帮助Alex把它整理出来。它更集中于边界,而没有那么强调基本的架构;然而这篇正是源自第一性原理框架关于核心基础设施的说明文章。
未来
像Ujo这样的系统,组合许多的组件到一起,比如IPFS等。最终他也能从所有的这些组件系统中受益。
我非常期待当大家更好的了解了组件间的关联关系后,这个趋势将进一步的加速。这样的分组比把所有组件揉为一个叫区块链的更能提高大家的生产率。
随着去中心化的生态演变,我期望这个技术栈不断迭代。AWS刚推出时只有一个服务:S3用于存储二进制的大对象。然后它发展了计算:EC2。既而一路向前,这里是它发展的完整时间线(https://en.wikipedia.org/wiki/Timeline_of_Amazon_Web_Services)。AWS现在有超过50个组件;尽管其中只有一小部分是最重要的。下面是一张AWS提供的服务的图片。
我预见在去中心的领域也将发生类似的事情。作为第一步,大家可以想像一下每一个AWS组件对应的去中化版本。然而,这其中,肯定会存在一些不同,每个生态(云计算 vs 去中心化)都会有一些自己独有的,比如去中化中特有的代币存储。让我们一起来开启这个有趣的旅程吧。
出处:http://me.tryblockchain.org/blockchain-infrastructure-landscape-a-first-principles-framing.html
版权申明:内容来源网络,版权归原创者所有。除非无法确认,我们都会标明作者及出处,如有侵权烦请告知,我们会立即删除并表示歉意。谢谢。
架构文摘
ID:ArchDigest
互联网应用架构丨架构技术丨大型网站丨大数据丨机器学习

更多精彩文章,请点击下方:阅读原文










