
导语:一文带你读懂机器学习、深度学习、统计与概率论的区别
文/ Limber Cheng
导言
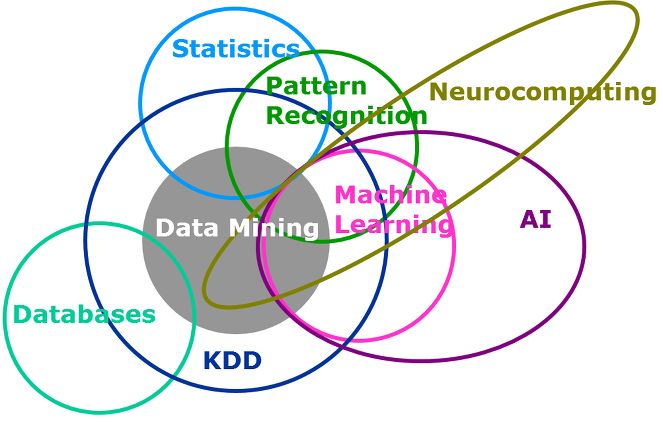
前几天和中科院的戴玮前辈谈论机器学习,在刷ESL(TheElement of Statistical Learning)的时候不免想到,所谓之机器学习究竟与Statistics有何区别。从最简单的Regression到神经网络,很大程度都是Statistical Learning的江山。而我们熟知当年Tom Mitchell经典一文[1]奠定了机器学习正式挺直了腰板,从此机器学习不再是Statistics的附庸。

除了风格与Supervised/Unsupervised Learning截然不同的Reinforcement Learning以外,大家虽然知道机器学习已不再附于Statistics,然而具体而言却又不得一二。本文就谈论机器学习与传统的统计入手,讲一下个人对二者区别之理解,而后在此基础上谈谈概率论与以上两个学科之不同。
侧重点之不同
在Brian Caffo[2]提到一个关于MachineLearning与Traditional statistical analyses的一些区别,主要在关注主体和验证性作区分。前者不关心模型的复杂度有多么的高,仅仅要求模型有良好的泛化性以及准确性。而后者在模型本身有一定的要求——不可过于复杂。
而前者主要验证的也就是前者的关注对象即是否有良好的泛化性与准确性,引入了Cross Validation。而后者尝试寻找一种可被验证的Hypotheses,因此而引入了如 student t-test 等方法。也就是说统计希望得到的是一个被实验数据在一定容许误差内验证为正确的东西。统计要求过程严谨可证明,而机器学习要求结果有效,偏实用主义更多。
结果导向在金融市场的应用时也出了大问题,然而甚至有人(市面上有好几本教别人用机器学习做量化分析的书)还光明正大的招摇撞骗,自己做的金融产品亏的一塌糊涂还强行吹【人工智能选出来的】——这届韭菜特好骗。
曾经我十分勤勤恳恳的做了几十个模型,后来发现几十个跑的挺不错的模型出来的结论全都是一厢情愿的自己骗自己,都没有什么卵用——理论特厉害,实盘亏精光。有效果可能是假的,跑的再好可能也是假的。而更好笑的是,市面某一本教量化的书,Machine Learning中的Training Set和Validation Set测试结果跑出了一个不高不低的成绩就敢直接用了,甚至模型放到书里面。这届韭菜很好学,卖的还很好。

这些东西是和Over-fitting、code bug等技术层面的失误没有任何关系,因此强化学习(Reinforcement Learning)在Quant中也大行其道。(Quant的工作就是设计并实现金融的数学模型(主要采用计算机编程),包括衍生品定价,风险估价或预测市场行为等)
并不是没有人尝试打开机器学习、深度学习的黑箱,如顾险峰老师试图用几何打开Wasserstein GAN[3]的黑箱[4]——用Briener势函数来代替深度神经网络这个黑箱
,从而使得整个系统变得透明。推开黑箱,对最优化理论的功夫的要求极深,甚至其中有很多内容也许尚不能用现有定理证明。

这种情况也是十分的哭笑不得——应用跑的比底层理论更快。而反而需要数学领域加紧发展才能逐渐打开深度学习的黑箱。而机器学习也同样的陷入了“LightGBM帝国主义”[6],在Kaggle竞赛中得奖的清一色只有两种情况,第一种是用神经网络,第二种是Handcrafted feature engineering,主要就是用XGBoost。
后来Microsoft的LightGBM[6]横空出世,跑的比XGBoost更快更好了,瞬间就成了LightGBM的天下了。手工特征加LightGBM,打遍天下无敌手。然而问【你为啥用啊?】或者【为啥LightGBM效果就这么好啊?】——不知道啊。
复杂性要求不同
传统科学有一个很经典的评价标准——奥卡姆剃刀法则(如无必要,勿增实体),认为科学应该用相对更简单的方式来表述。因此统计学模型的设计是有一个复杂性的考虑的——即使更复杂的模型效果更好,也不能采用之。

这句话我在两年前还不大能够理解,后来我在翻一本科学史的研究的著作时看到了这样的一则故事:日心说初期,其精准度比不上托勒密天文体系。然而托勒密天文体系其模型的复杂度远在日心说之上,浩如烟海的解释以及分析,最后被简单的几大定律给一网打尽。出于这般考虑,传统统计分析,要求统计模型的复杂度限制在一定的范围之内。
在传统的统计分析中,会强调参数的可解释性。与机器学习相比,统计模型中可能有许多参数,算法并不真正关心这些参数。机器学习的模型越来越可怕,我在下面放了从LeNet到ResNet的网络图大家可以感受一下模型的发展历程。
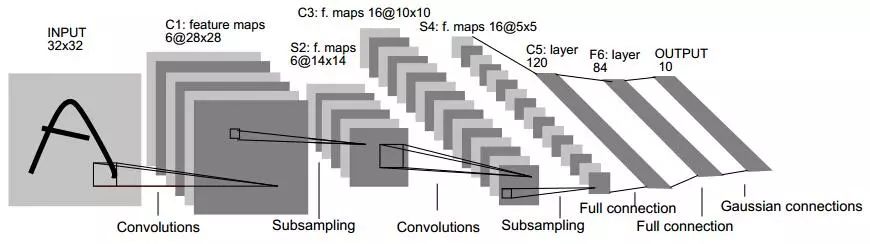
LeNet(1986)
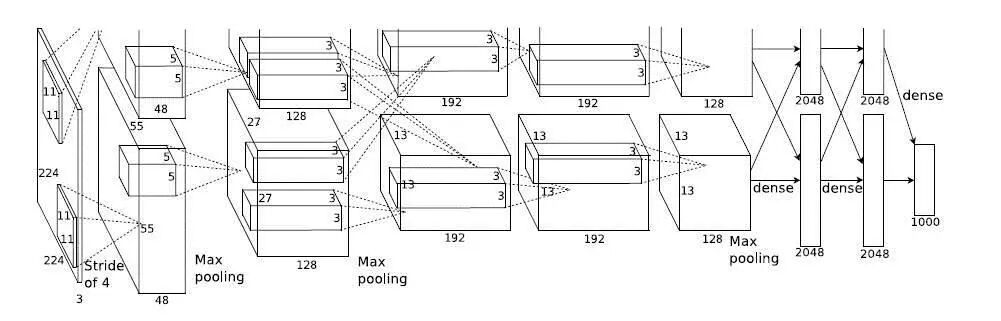
AlexNet(2012)
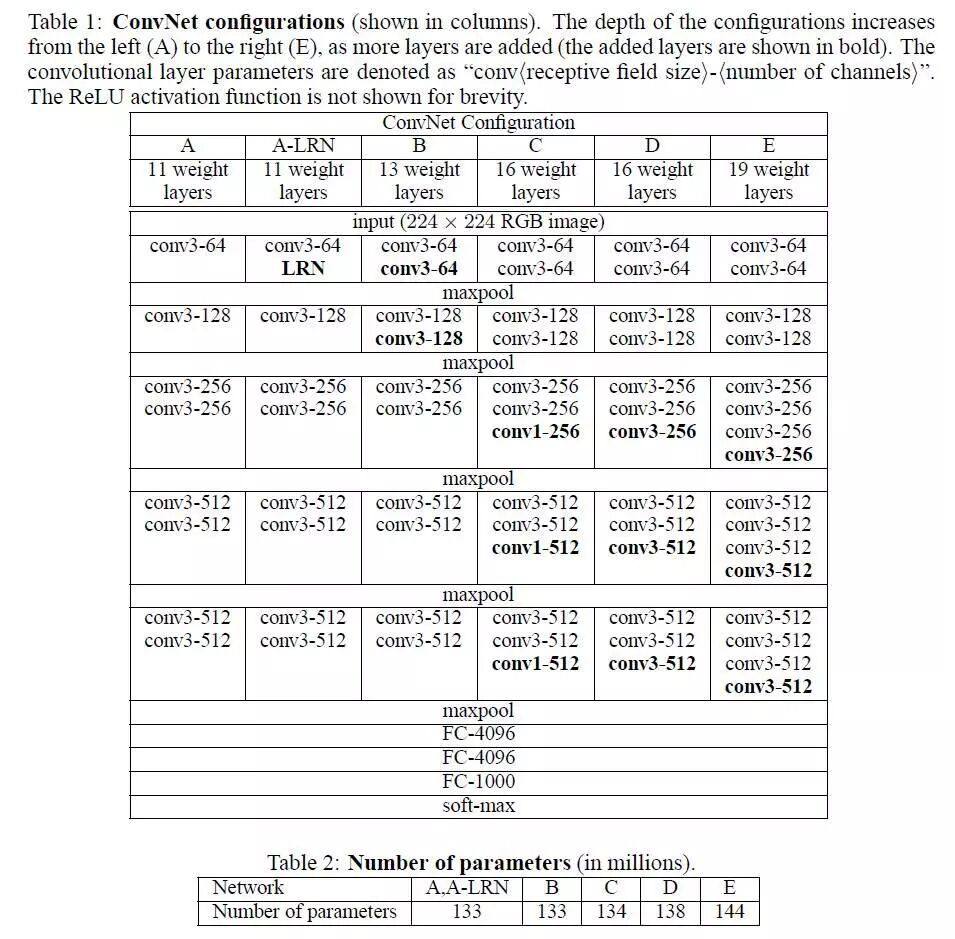
VGG(2014)
模型的深度往下走,复杂度直线上升。然而深度学习发展到现在,控制复杂性和提高泛化性上大致可分为两个大方向:
我在台湾的一个朋友在做一个深度学习的项目的时候十分骄傲的跟我说他建了1048层的网络,然后用非常豪华的GPU阵容去Train整个模型,他说完之后我就默默的在心里的小本本写上“这二货对深度学习一无所知”。虽然如此,机器学习不去担心模型的复杂性,而是去担心模型是不是发力过猛导致over-fitting,最后的结果就成了一个调参师。
这种奇葩的情况不免让我想到了中学时代做光学实验的时候,那时我对焦距的计算一无所知,而上课睡觉的我总是不理解为什么在做实验的时候要在我面前放一打草稿纸,因为我直接上手摆弄透镜去了,最后总能靠感觉一点点逼近一个不错的答案。作为一个结果导向的东西,深度学习、机器学习还真的和这方面很像。
机器学习的硬伤
机器学习虽然不对过程有太高的要求,但是也有一个很明显的弊端,业界有言曰:“垃圾进垃圾出”,假如你的数据噪音(Noise)很大或者其与结果的相关性极低,那么用这个数据完成的机器学习的模型也极有可能非常的差。
当数据本身成为问题之后,一切将很轻松的被颠覆——因此机器学习花了大量的功夫在做Feature上。

统计本身就是个为了得到一个General Rule,也就是通过了Hypotheses的证明之后的Conclusion本身。这个Conclusion本身可以作为一个指导意见。而机器学习则是拿着模型带着走,针对具体的问题用具体的模型,拍进输入得到想要的输出。统计得到的结果本身可以作为一种解释,无数的研究便是由统计验证得到的结论作为研究的基础。
概率论的特殊性
相比机器学习与统计,概率论与二者之差别较为明显。概率论是可以不需要任何数据就可以直接进行研究,而统计、机器学习,不能。不依靠任何数据,就意味着这个学科对数学、对纯理论有更高的要求——它更多地注重分析概率的背后的数理关系。统计学的支撑可能就是一条大数定律,而概率论的支持则有如测度论等很多不同的东西。
Reference:
1. Tom Mitchell, The Discipline of MachineLearning 2016.
2. Real Life Data Science, courser
3. Martin Arjovsky, Soumith Chintala, Léon Bottou. Wasserstein GAN.
4. Na Lei, Kehua Su, Li Cui, Shing-Tung Yau,Xianfeng Gu. A Geometric View of Optimal Transportation and Generative Model.
5. Xianfeng Gu, Feng Luo, Jian Sun andShing-Tung Yau, Variational Principles forMinkowski Type Problems, DiscreteOptimal Transport, and Discrete Monge-Ampere Equations, Vol. 20, No. 2, pp.383-398, Asian Journal of Mathematics (AJM), April 2016.
6. Andrew Fogg. Anthony Goldbloom gives youthe secret to winning Kaggle competitions. https://www.import.io/post/how-to-win-a-kaggle-competition/
7. Yu Shi, Jian Li, Zhize Li. GradientBoosting With Piece-Wise Linear Regression Trees. Annals of statistics, 2001 – JSTOR
8. Wang H, Zhou Z, Li Y, et al. Comparison ofmachine learning methods for classifying mediastinal lymph node metastasis ofnon-small cell lung cancer from 18F-FDG PET/CT images[J]. 2017, 7.
9. Krizhevsky A, Sutskever I, Hinton G E.ImageNet Classification with Deep Convolutional Neural Networks [J]. Advancesin Neural Information Processing Systems, 2012, 25(2):2012.
10. Franc¸ois Chollet. Xception: Deep Learning with DepthwiseSeparable Convolutions. CVPR 2016
11. Hao Li, Zheng Xu, Gavin Taylor, TomGoldstein. Visualizing the Loss Landscape of Neural Nets. ArXiv 2017.
— 完 —

快点扫我~
长按上面二维码,关注优达学城(Udacity)订阅号,回复关键字【学习资料】,获取来自硅谷的,包括【前端开发技能清单】、【大数据求职指南】、【机器学习求职指南】、【Tableau学习PDF】等一系列独家豪华学习资料,让你不落人后!

如果你也是想看看自己的极限在哪里,想通过学习掌握自己的命运方向,那么我们有一个很棒的活动推荐给你——「UdaMeet」,详情戳:阅读全文









