原标题NanoNets : How to use Deep Learning when you have Limited
Data,作者Sarthak Jain。
我觉得人工智能就像是去建造一艘火箭飞船。你需要一个巨大的引擎和许多燃料。如果你有了一个大引擎,但燃料不够,那么肯定不能把火箭送上轨道;如果你有一个小引擎,但燃料充足,那么说不定根本就无法成功起飞。所以,构建火箭船,你必须要一个巨大的引擎和许多燃料。
深度学习(创建人工智能的关键流程之一)也是同样的道理,火箭引擎就是深度学习模型,而燃料就是海量数据,这样我们的算法才能应用上。——吴恩达
使用深度学习解决问题的一个常见障碍是训练模型所需的数据量。对大数据的需求是因为模型中有大量参数需要学习。
以下是几个例子展示了最近一些模型所需要的参数数量:

深度学习模型的详细信息
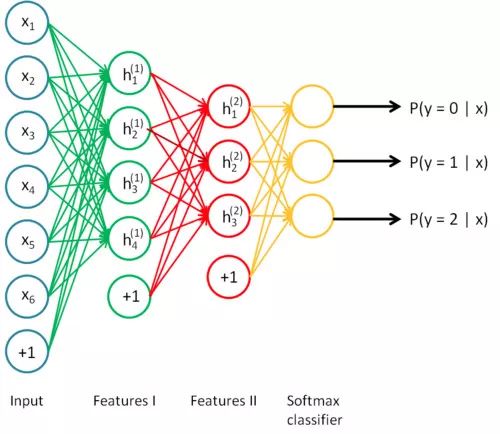
神经网络又名深度学习,是可以堆叠起来的层状结构(想想乐高)
深度学习只不过是大型神经网络,它们可以被认为是流程图,数据从一边进来,推理或知识从另一边出来。
你可以拆分神经网络,把它拆开,从任何你喜欢的地方取出推理。你可能没有得到任何有意义的东西,但你依然可以这么做,例如Google
DeepDream。
模型大小 ∝ 数据大小 ∝ 问题复杂度
在所需的数据量和模型的大小之间有一个有趣的近乎线性的关系。
基本的推理是,你的模型应该足够大,以便捕捉数据中的关系(例如图像中的纹理和形状,文本中的语法和语音中的音素)以及问题的具体细节(例如类别数量)。模型早期的层捕捉输入的不同部分之间的高级关系(如边缘和模式)。后面的层捕捉有助于做出最终决策的信息,通常能够帮助在想要的输出间进行区分。因此,如果问题的复杂性很高(如图像分类),参数数量和所需数据体量也非常大。
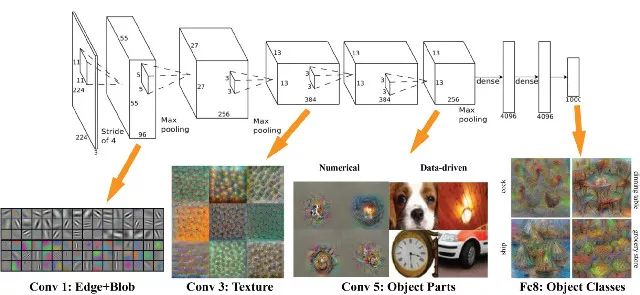
AlexNet在每一步能够看到什么
迁移学习来解围!
在处理一个您的特定领域的问题时,通常无法找到构建这种大小模型所需的数据量。
然而,训练一个任务的模型捕获数据类型中的关系,并且可以很容易地再用于同一个领域中的不同问题。 这种技术被称为迁移学习。
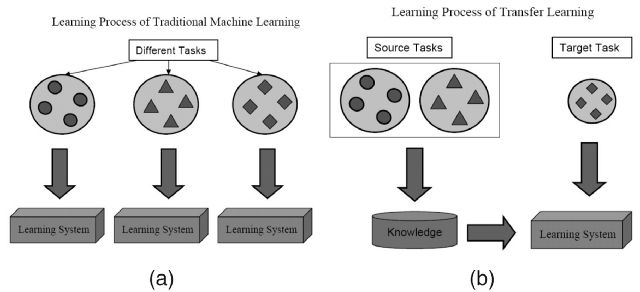
转移学习就像没有人试图保留但却保存的最好的秘密一样。 业内人人都知道,但外界没有人知道。
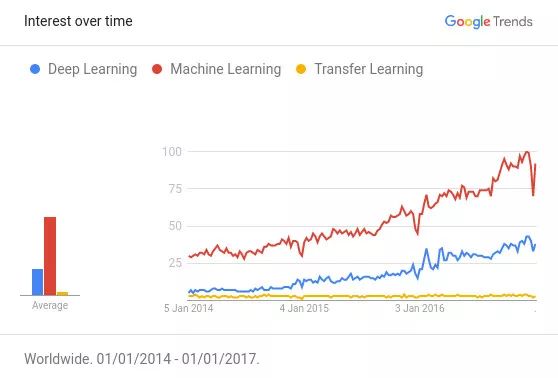
Google 趋势机器学习 vs 深度学习 vs 迁移学习
参考Awesome — Most Cited Deep Learning Papers,看看深度学习中的顶级论文:
引用最多的深度学习论文,超过50%的论文使用某种形式的转移学习或预训练。
转移学习变得越来越适用于资源有限(数据和计算)的人们,但不幸的是,这个想法还没有得到应有的社会化。 最需要它的人还不知道它。
如果深度学习是圣杯,数据是守门人,转移学习是关键。
通过转移学习,我们可以采用已经在大型现成数据集上训练好的预训练模型(在完全不同的任务上进行训练,输入相同但输出不同)。
然后尝试查找输出可重复使用特征的图层。 我们使用该层的输出作为输入特征来训练需要更少参数的小得多的网络。
这个较小的网络已经从预训练模型了解了数据中的模式,现在只需要了解它与你特定问题的关系。 猫咪检测模型可以被重利用于梵高作品重现的模型就是这样训练的。
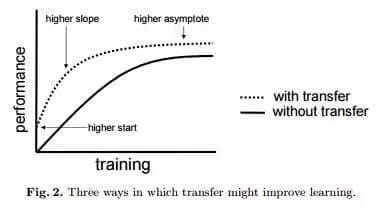
使用转移学习的另一个主要优势是模型的泛化效果很好。
较大的模型倾向于过度拟合数据(即对数据进行建模而不是对潜在的现象建模),并且在对未见数据进行测试时效果不佳。
由于转移学习允许模型看到不同类型的数据,因此它更好地学习了世界的基本规则。
把过拟合看做是记忆而不是学习。—— James Faghmous
由于迁移学习导致的数据减少
假设想结束蓝黑礼服vs白金礼服的争论。你开始收集验证的蓝黑礼服和白金礼服的图像。如果想自己建立一个像上文提到的那样精确的模型(有140百万个参数)。为了训练这个模型,你需要找到120万张图像,这是一个不可能完成的任务。
所以可以试试迁移学习。
计算一下使用迁移学习解决该问题所需要的参数数量:
参数数量 = [输入大小 + 1] * [输出大小 + 1]
= [2048+1]*[1+1]~ 4098 个参数
我们看到参数数量从1.4×10⁸减少到4×10³,这是5个数量级。 所以我们要收集不到一百个连衣裙的图像,这样应该还好。唷!
如果你不耐烦,等不及要找出衣服的实际颜色,向下滚动,看看如何建立自己的礼服模型。
· · ·
转移学习的分步指南——使用与情感分析相关的实例
在这个实例中我们有72个电影评论
1、62个没有分配情绪,这些将被用于预先模型
2、8个分配了情绪,它们将被用于训练模型
3、2个分配了情绪,它们将被用于测试模型
由于我们只有8个有标记的句子(那些有感情相关的句子),我们首先直接训练模型来预测上下文。
如果我们只用8个句子训练一个模型,它会有50%的准确率(50%如同用抛硬币进行决策)。
为了解决这个问题,我们将使用转移学习,首先在62个句子上训练一个模型。 然后,我们使用第一个模型的一部分,并在其基础上训练情感分类器。
使用8个句子进行训练,并在剩下的2个句子上进行测试时,模型会产生100%的准确率。
步骤一
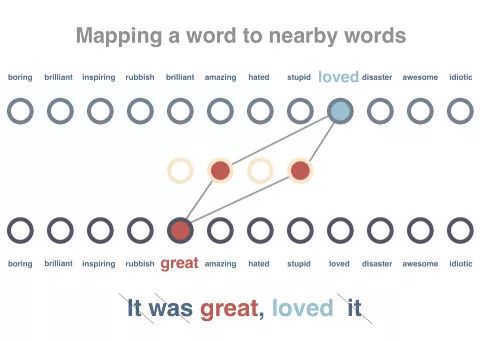
我们将训练一个对词语之间的关系进行建模的网络。将句子中的一个词语传递进去,并尝试预测该词语出现在同一个句子中。在下列的代码中嵌入的矩阵大小为vocabulary
x embedding_size,其中存储了代表每个词语的向量(这里的大小为“4”)。

Github地址:
https://gist.github.com/sjain07/98266a854d19e01608fa13d1ae9962e3#file-pretraining_model-py
步骤二
我们会对这个图标进行训练,让相同上下文中出现的词语可以获得类似的向量表征。我们会对这些句子进行预处理,移除所有停止词并标记他们。随后一次传递一个词语,
尽量缩短该词语向量与周边词语之间的距离,并扩大与上下文不包含的随机词语之间的距离。
Github地址:https://gist.github.com/sjain07/3e9ef53a462a9fc065511aeecdfc22fd#file-training_the_pretrained_model-py
步骤三
随后我们会试着预测句子索要表达的情绪。目前已经有10个(8个训练用,2个测试用)句子带有正面和负面的标签。由于上一步得到的模型已经包含从所有词语中习得的向量,并且这些向量的数值属性可以代表词语的上下文,借此可进一步简化情绪的预测。
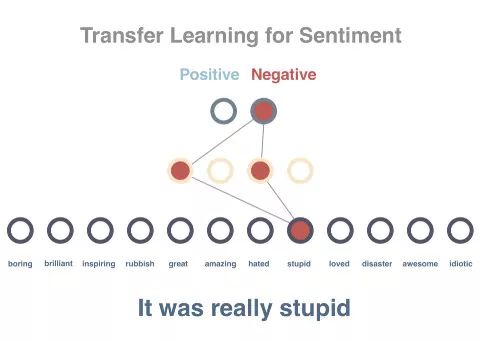
此时我们并不直接使用句子,而是将句子的向量设置为所含全部词语的平均值(这一任务实际上是通过类似LSTM的技术实现的)。句子向量将作为输入传递到网络中,输出结果为内容为正面或负面的分数。我们用到了一个隐藏的中间层,并通过带有标签的句子对模型进行训练。如你所见,虽然每次只是用了10个样本,但这个模型实现了100%的准确度。
Github地址:https://gist.github.com/sjain07/a45ef4ff088e01abbcc89e91b030b380#file-training_the_sentiment_model-py
虽然这只是个示例,但可以发现在迁移学习技术的帮助下,精确度从50%飞速提升至100%。若要查看完整范例和代码请访问下列地址:
https://gist.github.com/prats226/9fffe8ba08e378e3d027610921c51a78
迁移学习的一些真实案例
图像识别:图像增强、风格转移、对象检测、皮肤癌检测。
文字识别:Zero Shot翻译、情绪分类。
迁移学习实现过程中的难点
虽然可以用更少量的数据训练模型,但该技术的运用有着更高的技能要求。只需要看看上述例子中硬编码参数的数量,并设想一下要在模型训练完成前不断调整这些参数,迁移学习技术使用的难度之大可想而知。
1、迁移学习技术目前面临的问题包括:
2、找到预训练所需的大规模数据集
3、决定用来预训练的模型
4、两种模型中任何一种无法按照预期工作都将比较难以调试
5、不确定为了训练模型还需要额外准备多少数据
6、使用预训练模型时难以决定在哪里停止
7、在预训练模型的基础上,确定模型所需层和参数的数量
8、托管并提供组合后的模型
9、当出现更多数据或更好的技术后,对预训练模型进行更新
数据科学家难觅。找到能发现数据科学家的人其实一样困难 --Krzysztof Zawadzki
让迁移学习变得更简单
亲身经历过这些问题后,我们开始着手通过构建支持迁移学习技术的云端深度学习服务,并尝试通过这种简单易用的服务解决这些问题。该服务中包含一系列预训练的模型,我们已针对数百万个参数进行过训练。你只需要上传自己的数据(或在网络上搜索数据),该服务即可针对你的具体任务选择最适合的模型,在现有预训练模型的基础上建立新的NanoNet,将你的数据输入到NanoNet中进行处理。
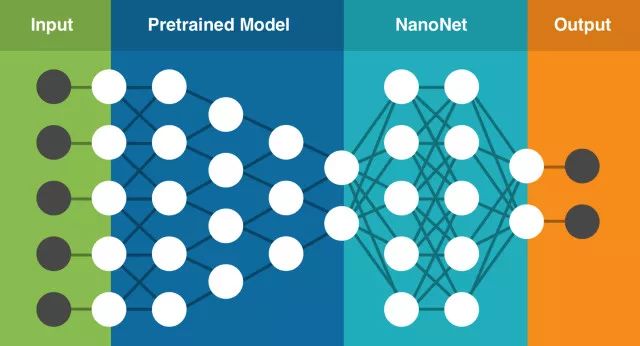
NanoNets的迁移学习技术(该架构仅为基本呈现)
构建你的首个NanoNet(图像分类)
1、在这里选择你要处理的分类。
2、 一键点击开始搜索网络并构建模型(你也可以上传自己的图片)。

3、 解决蓝金裙子的争议(模型就绪后,我们会通过简单易用的Web界面让你上传测试图片,同时还提供不依赖特定语言的API)。


这些情况我们都经历过。你精通机器学习的相关概念,并能将其应用于机器学习模型。打开浏览器搜索相关数据,很可能会找到一系列数据以及上百幅相关照片。
你会想起大部分流行的数据集拥有数以千计的图片(甚至更多)。你也会想起有人曾说过拥有大规模的数据集对性能至关重要。你会感到失望,非常想知道:在有限的数据量下,顶级神经网络能不能很好地工作?
回答是肯定的,但在见证奇迹之前,我们需要思考一些基本问题。
为什么需要大量的数据

常用的神经网络的参数数量。
当你训练一个机器学习模型时,你实际做工作的是调参,以便将特定的输入(一副图像)映像到输出(标签)。我们优化的目标是使模型的损失最小化,
以正确的方式调节优化参数即可实现这一目标。
成功的神经网络拥有数以百万计的参数!
自然,如果你有大量参数,就需要提供你的机器学习模型同比例的实例,以获得优秀的性能。你需要的参数数量与需要执行的任务复杂性也成比例。
在没有大量数据情况下,如何获取更多数据?
其实,你并不需要添加大量的图像到你的数据集,为什么?
因为,神经网络从一开始就不是智能的,例如,缺乏训练的神经网络会认为下面这3个网球是不同的、独立的图像。

完全一样的网球,神经网络的解释却不同。
所以,为了获得更多数据,我们仅需要对已有的数据集做微小的调整。比如翻转、平移或旋转。神经网络会认为这些数据是不同的。
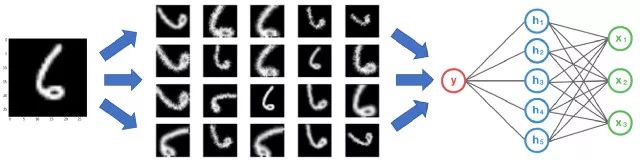
运动中的数据增强
一个卷积神经网络有一个称作不变性的性质,即使卷积神经网络被放在不同方向上,它也能进行对象分类。更具体的说,卷积神经网络对平移、视角、尺寸或照度(或以上组合)保持不变性。
这就是数据增强的本质前提。在现实世界中,我们可能会有一组在有限的条件下拍摄的图像
。但是,我们的目标应用可能是在多变的环境中,例如,不同的方向、位置、比例、亮度等。我们通过使用经综合修改过的数据来训练神经网络,以应对这些情形。
即使拥有大量数据,再增强数据也是有帮助的吗?
当然。这会有助于增加数据集中相关数据的数量。 这与神经网络的学习方法相关,让我通过一个例子来说明。

假设数据集中的两个类。左边的代表品牌A(福特),右边的代表品牌B(雪佛兰)。
假设完成了训练,并且输入上面的图像,即品牌A。但是你的神经网络输出认为它是品牌B的汽车!使用先进的神经网络不是应该有95%的正确率吗?我不是夸大其词,类似的事情在过去也发生过。

福特汽车(品牌A),但面向右侧。
为什么会发生这种现象?因为这是大多数机器学习算法就是这么工作的。它会寻找区分一个类和另一个类的最明显特征。在这个例子中
,这个特征就是所有品牌A的汽车朝向左边,所有品牌B的汽车朝向右边。
神经网络的好坏取决于输入的数据。
我们如何预防这种现象发生?
我们需要减少数据集中不相关特征的数量。对上面的汽车类型分类器来说,一个最简单的解决办法就是为数据集中的每种类别都添加朝向不同方向的汽车照片。更好的办法是,你只需要将现有的数据集中的照片水平翻转,使汽车朝向另一侧。现在,用新的数据集训练神经网络,你就会得到你想要的结果。
通过增强数据集,可以防止神经网络学习到不相关的模式,根本上提升整体性能。
准备开始
在我们深入研究各种增强技术之前,我们必须先考虑一个问题。
在机器学习过程中的什么位置进行数据增强?
答案相当明显:在向模型输入数据之前增强数据集,对吗?是的,但你有两个选项,一个是预先进行所有必要的变换,从根本上增加数据集的规模。另外一个是小批量执行变换,仅仅在输入机器学习模型之前。
第一项被称为离线增强。这个方法常被用于相对较小的数据集。因为你最终会通过一个与执行的转换数量相等的因子来增加数据集的大小(例如,通过翻转所有图像,数据集数量会增加2倍)。
第二个选项称为在线增强,或称为动态增强。主要应用于规模较大的数据集,因为你无法负担数据量爆炸性增长。反而,你可以通过对即将输入模型的小批量数据的执行相应的变化。很多机器学习架构已经支持在线增强,并可以利用GPU进行加速。
常用的增强技术
在这一节,我们将介绍一些基础但功能强大的增强技术,这些技术目前被广泛应用。在我们讲述这些技术之前,为简单起见,让我们做一个假设,即我们不需要关心图片边界之外的东西。如果使用下面的技术,我们的假设将是有效的。
如果使用的技术关注图像边界之外的区域,将会发生什么呢?在这种情况下,我们需要插入一些信息。在讨论完数据增强的类型后我们在详细讨论这一问题。
我们为每个技术都定义了一个增强因子,用以增强数据集(也成为数据增强因子)。
1. 翻转
你可以水平或垂直翻转图像。一些架构并不支持垂直翻转图像。但,垂直翻转等价于将图片旋转180再水平翻转。下面就是图像翻转的例子。

从左侧开始分别是:原始图像,水平翻转图像,垂直翻转图像。
可以通过执行下面的命令完成图像翻转。

2. 旋转
关于这个操作,需要注意的一个关键问题是,在旋转之后,图像维度可能不会被保留。如果是正方型图像,旋转90度之后图像的尺寸会被保存。如果图像是长方形,旋转180度之后图像尺寸也会保存。
但用更小的角度旋转图像,将会改变最终图像的尺寸。在下面的章节中我们将会看到如何解决这个问题。下面是方形图像旋转90度的例子。

当我们从左到右移动时,图像相对于前一个图像顺时针旋转90度。
你可以执行下面的任一命令完成图像旋转。 数据增强因子 = 2 到 4x

3. 缩放
图像可以被放大或缩小。放大时,放大后的图像尺寸会大于原始尺寸。大多数图像处理架构会按照原始尺寸对放大后的图像进行裁切。我们将在下一章节讨论图像缩小,因为图像缩小会减小图像尺寸,这使我们不得不对图像边界之外的东西做出假设。下面是图像缩放的例子。

从左边开始分别为:原始图像,图像向外缩放10%,图像向外缩放20%。
通过下面的命令执行图像缩放。数据增强因子=任意。

4. 裁剪
与缩放不同,我们随机从原始图像中采样一部分。然后将这部分图像调整为原始图像大小。这个方法更流行的叫法是随机裁剪。下面是随机裁剪的例子。如果你靠近了看,你会注意到裁剪和缩放两种技术之间的区别。

从左侧开始分别为:原始图像,从左上角裁剪出一个正方形部分,然后从右下角裁剪出一个正方形部分。剪裁的部分被调整为原始图像大小。
通过下面的TensorFlow命令你可以执行随机裁剪。 数据增强因子=任意。

5. 平移
平移是将图像沿X或Y方向(或者同时沿2个方向)移动。在下面的例子中,
我们假设在图像边界之外是黑色的背景,也同步被移动。这一数据增强方法非常有用,因为大多数对象有可能分布在图像的任何地方。这迫使你的卷积神经网络需要看到所有地方。
从左侧开始分别为:原始图像,图像翻转到右侧,图像向上翻转。
在TensorFlow中,可以通过如下命令完成图像平移。数据增强因子=任意。

6. 高斯噪声
过拟合(Overfitting)经常会发生在神经网络试图学习高频特征(即非常频繁出现的无意义模式)的时候,而学习这些高频特征对模型提升没什么帮助。
那么如何处理这些高频特征呢?一种方法是采用具有零均值特性的高斯噪声,它实质上在所有频率上都能产生数据点,可以有效的使高频特征失真,减弱其对模型的影响。
但这也意味着低频的成分(通常是你关心的特征)同时也会受到影响,但是神经网络能够通过学习来忽略那些影响。事实证明,通过添加适量的噪声能够有效提升神经网络的学习能力。
一个“弱化”的版本是椒盐噪声,它以随机的白色和黑色像素点呈现并铺满整个图片。这种方式对图像产生的作用和添加高斯噪声产生的作用是一样的,只是效果相对较弱。

从左侧开始分别为:原始图像,增加了高斯噪声的图像,添加了椒盐噪声的图像。
在 TensorFlow 中,你可以使用以下的代码给图片添加高斯噪声。数据增强因子(Data Augmentation Factor)= 2x。

高级增强技术
现实世界中,自然状态下的数据,存在于各种各样的状况之中, 不能用上述简单的方法来处理。例如,
进行照片中的景观识别的任务。景观可以是任何自然中的东西:冰冻寒带草原、草原、森林等等。听起来像是个很直接的分类任务对吧?基本没问题,除了一件事外。我们忽略了照片中的一个关键特征,
而这个特征将会影响到模型的表现——照片拍摄的季节。
如果我们的神经网络不明白某些景观可以存在于各种条件下(雪、潮湿、明亮等), 它可能会错误地将冰冻的湖畔标记为冰川或者把沼泽标记为湿地。
缓解这种情况的一种方法是添加更多的图片,这样我们就可以解释所有季节性变化。但这是一项艰巨的任务。扩展我们的数据增强概念,想象一下,人为地产生不同季节的效果会有多酷?
条件型生成对抗网络,了解一下
并不用深入了解繁杂的细节,条件型生成对抗网络就能将一张图片从一个领域转换到另一个领域中去。假如你觉得这听上去太模棱两可了,它本身并不是这样;事实上这是一种强大的神经网络
! 下面是一个应用条件型生成对抗网络(Conditional GANs)将夏日风光的图片转换为冬季风景的例子。

用CycleGAN 改变季节
(Github: https://junyanz.github.io/CycleGAN/)
上述方法是鲁棒的(Robust), 但是属于计算密集型,需要耗费大量的计算性能。一个更廉价的选择是所谓的神经风格迁移(Neural Style
Transfer)。它抓住了一个图像的纹理/气氛/外观 (又名, "风格"), 并将其与其他内容混合在一起。使用这种强大的技术,
我们产生的效果类似于我们的条件型生成对抗网络所产生的效果(事实上, 这个方法是在 cGANs 发明之前就被提出来了!)。
这种方法唯一的缺点在于输出结果看起来太有艺术感了,以至于显得不那么真实。但是,在譬如深度学习的图像风格转换方面还是具有独特的优势,至少它的输出结果给人留下了深刻印象。

深度照片风格转移。
注意如何在数据集上产生我们想要的效果。
(来源:https://arxiv.org/abs/1703.07511)
由于我们并不关注其内部的工作原理,所以我们没有深入探索这些技术。事实上,我们可以使用现有训练好的模型再加上一点迁移学习的“神奇力量”来进行数据增强。
插值简介
如果想平移一个没有黑色背景的图像时候该怎么办?向内部缩放呢?旋转一个特定的角度?在完成这些变换之后,我们需要保持原始图像的大小。由于我们的图像没有包含其边界之外的区域的任何信息,我们得做一些假设。一般来说,我们会假定图像边界之外的部分的每一个像素点的值都是常数
0 (RGB值为 0 表示黑色)。这样,在对图像进行变换之后,在图像没有覆盖的地方会得到一块黑色的区域。

从左侧开始分别为:逆时针旋转45度的图像,右侧翻转的图像和向内缩放的图像。
但是,那个假设是不是就一定正确呢?在现实世界中,大多数情况下那个假设是不适用的。图像处理和机器学习框架提供的一些标准的处理方式,你可以决定如何填充未知的空间。

从左侧开始分别为:常数,边缘,反射,对称和包裹模式。
它们的定义如下:
1. 常量填充
最简单的插值方法是用某个常量值填充未知区域。这可能不适用于自然图像, 但可以用于在单色背景下拍摄的图像。
2. 边缘扩展
将图像边缘的值扩展到边界以外。这个方法可用于轻微的平移的图像。
3. 反射
图像像素值沿图像边界进行反射。这种方法对于包含树木、山脉等的连续或自然背景是有用的。
4. 对称
此方法类似于反射,除了在反射边界上进行边缘像素拷贝。通常,反射和对称可以交替使用,但在处理非常小的图像或图案时,差异将是可见的。
5. 包裹
在超出图像边界的部分重复填充图像,仿佛在进行图像平铺。这种方法不像其他的那样普遍使用, 因为它对很多场景都没有意义。
除此之外,你还可以设计自己的方法来处理未定义的空间, 但通常以上这些方法对大多数分类问题都有很好的效果。
使用了这些所有的技术,能保证机器学习算法的鲁棒性吗?
如果你用的是正确的方法,那这个问题的答案是 Yes !
什么?你问正确方法是什么?嗯,有时不是所有的增强技术都对数据集有意义。再考虑一下我们的汽车例子。下面是可以修改图像的一些方法。

第一个图像(从左边开始)是原始图像,第二个图像是水平翻转的,第三个图像旋转了180度,最后一个图像旋转了90度(顺时针)。
当然, 他们是同一辆车的照片, 但你的目标应用可能永远不会看到在这些方向的汽车。
例如,如果你要分类在路上的随机车辆,只有第二个图像对数据集来说是有意义的。但是,如果你拥有一家处理车祸的保险公司,而你也想识别车祸中颠倒的、撞坏的车,
那么第三张图片是有意义的。最后一个图像可能对上述两种情况都没有意义。
关键是, 在使用增强技术的同时,我们必须确保不增加无关的数据.。
这样做真的值得吗?
你也许正期待着能有一些结果来。有道理,我也做了这一点。让我先通过一个小示例来证明数据增强的确能够产生作用。不信的话,你可以复现这个实验来验证。
让我们创建两个神经网络, 将数据分类到四类中的一个:
猫、狮子、豹或者老虎。区别在于,一个不会使用数据增强,而另一个将使用数据增强。可以从此链接下载数据集。
如果你查看了数据集,你会发现里面训练集和测试集中每一类都只有50张图片。很明显,我们不能对特定的一个分类器使用增强技术。公平起见,我们使用迁移学习让模型能够应对数据稀缺问题。

数据库里的四个分类
对于没有进行数据增强的神经网络,我们将使用 VGG19 网络结构。在参考这个 VGG19
实现的基础上,我用TensorFlow实现了我们的第一个神经网络。一旦你克隆了我的 Github Repo, 你就可以从这里 得到数据集以及从这里 下载
VGG19. npy (用于迁移学习) 。完成上述工作后,就可以运行模型来验证性能了。
不过, 为数据增强编写额外的代码确实是费时费力的工作。所以, 构建我们的第二个模型过程中,我使用了
Nanonets。它内部实现了转移学习和数据扩充,可以用最少的数据量提供最佳的结果。所有你需要做的只是上传的数据到他们的网站,并等待他们的服务器训练完毕就可以了(通常约30分钟)。你要知道,这对我们进行对比实验多么完美。
完成训练后,你可以对其 API 请求调用来计算测试的准确性。你可以在GitHub repo中找到对应的示例代码片段 (不要忘记在代码段中插入模型的
ID)。

对比结果令人印象深刻不是吗?事实上,大多数模型在更多的数据上可以表现更良好。为了提供一个具体的证明,可仔细看看下面这张表。它显示了 Cifar 10
(C10) 和 Cifar 100 (C100) 数据集上常用的神经网络的错误率。C10+ 和 C100+ 列是进行数据增强后的错误率。
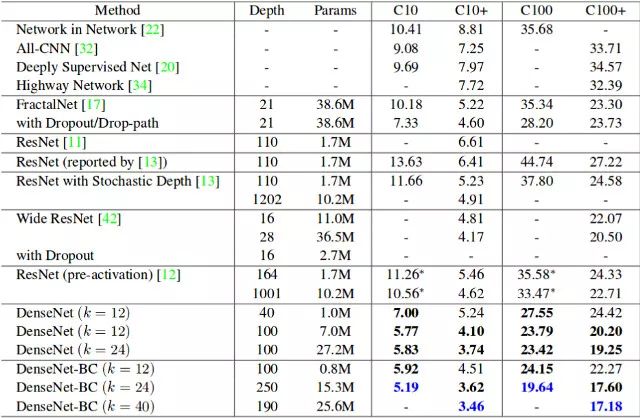
Cifar 10 和 Cifar 100 数据集上的表现
网络大数据
(ID:raincent_com)
网络大数据 www.raincent.com
致力于打造中国最专业的网络大数据科学门户网站。

识别二维码,关注网络大数据








