
©PaperWeekly 原创 · 作者 | 王馨月
学校 | 四川大学本科生
研究方向 | 自然语言处理

摘要
深度学习彻底改变了计算机视觉、自然语言理解、语音识别、信息检索等领域。然而,随着深度学习模型的逐步改进,它们的参数数量、延迟、训练所需的资源等都大幅增加。因此,关注模型的这些内存印迹指标,而不仅仅是其质量,也变得很重要。我们提出并推动了深度学习中的效率问题,然后对模型效率的五个核心领域(跨度建模技术、基础设施和硬件)及其开创性工作进行了全面综述。我们还提供了一个基于实验的指南和代码,供从业者优化他们的模型训练和部署。我们相信这是高效深度学习领域的第一次全面综述,覆盖从建模技术到硬件支持的模型效率领域。我们希望这份调查能够为读者提供思维模型和对该领域的必要理解,以应用通用效率技术立即获得显着改进,并为他们提供进一步研究和实验的想法,以获得额外的收获。
论文标题:
Efficient Deep Learning: A Survey on Making Deep Learning Models Smaller, Faster, and Better
论文作者:
Gaurav Menghani
论文链接:
https://arxiv.org/abs/2106.08962

引言
在过去十年中,使用神经网络进行深度学习一直是训练新机器学习模型的主要方法。它的崛起通常归功于 2012 年的 ImageNet 竞赛。那一年,多伦多大学的一个团队提交了一个深度卷积网络(AlexNet,以首席开发者 Alex Krizhevsky 的名字命名),表现优于下一个最好的提交结果 41%。作为这项开创性工作的结果,人们竞相使用越来越多的参数和复杂性来创建更深层次的网络。VGGNet、Inception、ResNet 等几个模型架构在随后几年的 ImageNet 比赛中相继打破了之前的记录,同时它们的内存印迹(模型大小、延迟等)也在不断增加。在自然语言理解(NLU)中也有这种影响,其中主要是基于 attention 层的 Transformer 架构激发了 BERT、GPT-3 等通用语言编码器的开发。BERT 在发布时就击败了 11 个 NLU 基准测试。GPT-3 也已通过其 API 在行业的多个地方使用。这些领域的共同点是模型占用空间的快速增长以及与训练和部署它们相关的成本(如图)。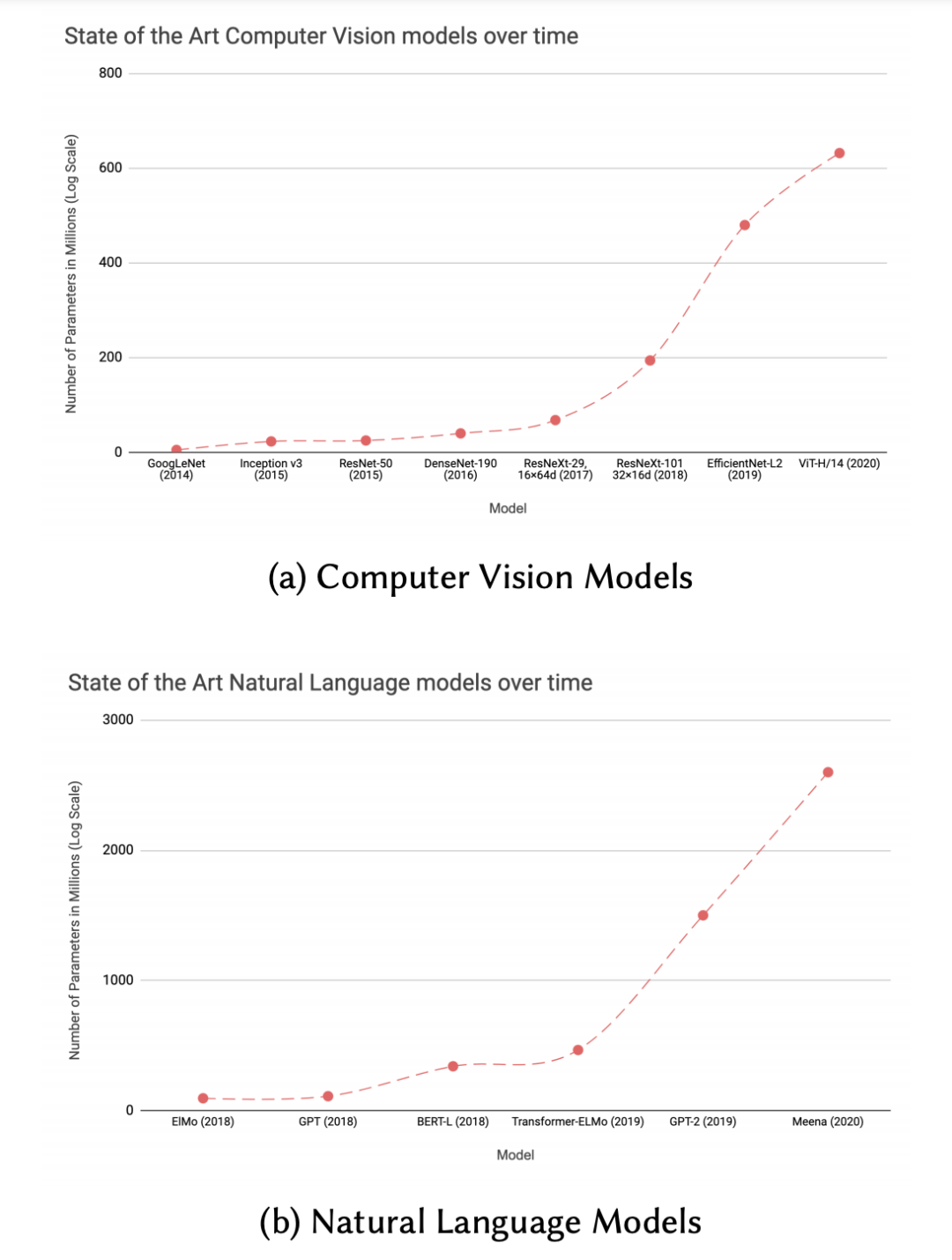
由于深度学习研究一直专注于改进现有技术,因此图像分类、文本分类等基准的逐步改进与网络复杂度、参数数量和所需的训练网络所需资源量以及预测的延迟的增加相关。例如,GPT-3 包含 1750 亿个参数,仅训练一次迭代就需要花费数百万美元。这不包括实验/尝试不同超参数组合的成本,这在计算上也很昂贵。虽然这些模型在训练它们的任务上表现良好,但它们不一定足够有效,无法在实际生活中直接部署。深度学习从业者在训练或部署模型时可能会面临以下挑战。

高效深度学习
围绕上述挑战的共同主题是效率。我们可以进一步分解如下:- 推断效率:这主要处理部署推断模型(计算给定输入的模型输出)的人会提出的问题。模型小吗?速度快吗?更具体地说,模型有多少参数,磁盘大小是多少,推断过程中的 RAM 消耗,推理延迟等。
- 训练效率:这涉及训练模型的人会问的问题,例如模型训练需要多长时间?有多少设备?该模型可以放入内存中吗?它还可能包括诸如模型需要多少数据才能在给定任务上实现所需性能的问题。
如果要给我们两个模型,在给定的任务上表现同样出色,我们可能希望选择一个在上述任一方面或理想情况下在上述两个方面都表现更好的模型。如果要在推断受限的设备(例如移动和嵌入式设备)或昂贵的设备(云服务器)上部署模型,则可能更值得关注推断效率。同样,如果要使用有限或昂贵的训练资源从头开始训练大型模型,开发专为提高训练效率而设计的模型会有所帮助。无论优化目标是什么,我们都希望实现帕累托最优。这意味着我们选择的任何模型都是我们关心的权衡的最佳选择。如图,绿点代表帕累托最优模型,其中其他模型(红点)在相同的推理延迟下均无法获得更好的准确性,反之亦然。帕累托最优模型(绿点)共同构成了我们的帕累托前沿(pareto-frontier)。根据定义,帕累托前沿中的模型比其他模型更有效,因为它们在给定的权衡下表现最好。因此,当我们寻求效率时,我们应该考虑在帕累托前沿上发现和改进。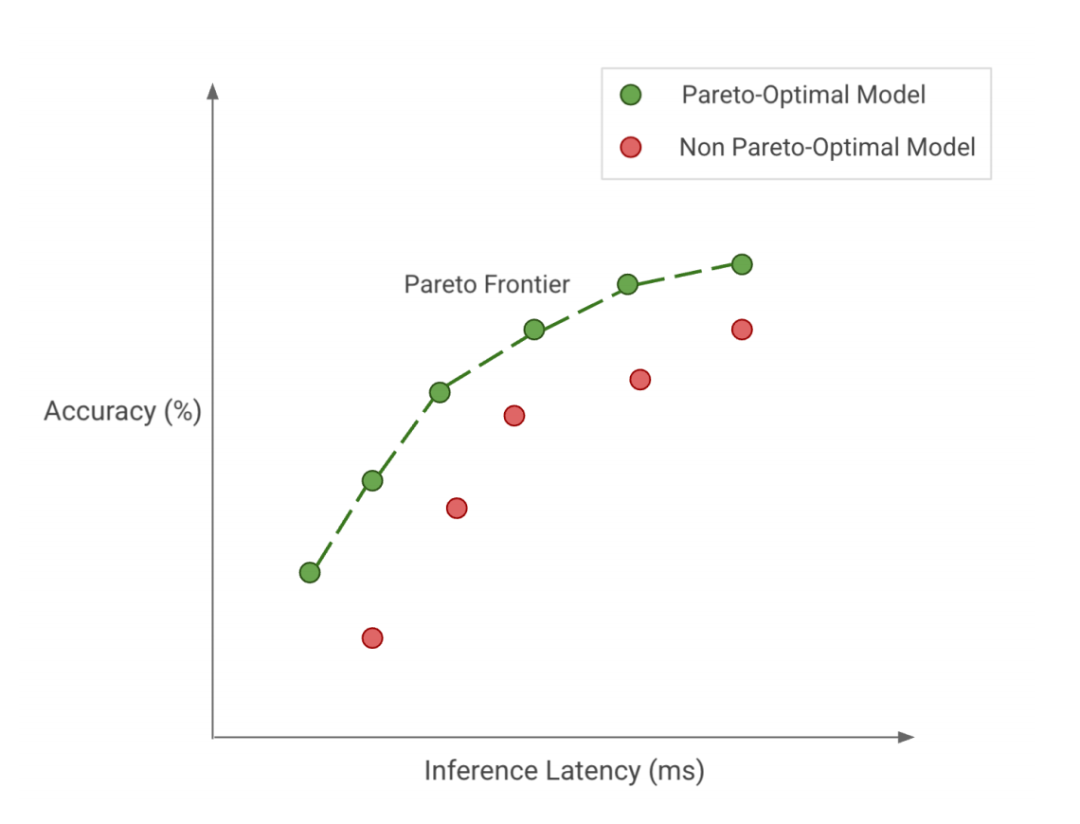
为了实现这一目标,我们建议转向一组算法、技术、工具和基础设施的组合,它们可以协同工作,以允许用户训练和部署关于模型质量及其内存印迹的帕累托最优模型。
总结
在本文中,我们首先展示了深度学习模型的快速增长,并说明了当今训练和部署模型的人必须对效率做出隐式或显式决策的事实。然而,模型效率的前景是广阔的。为了解决这个问题,我们为读者设计了一个心智模型,让他们围绕模型效率和优化的多个重点领域进行思考。核心模型优化技术的综述使读者有机会了解最新技术、在建模过程中应用这些技术,和/或将它们用作探索的起点。基础设施部分还列出了使高效模型的训练和推理成为可能的软件库和硬件。最后,我们展示了一部分明确且可操作的见解并辅以代码,供从业者用作该领域的指南。本节有望提供具体且可操作的要点,以及在优化用于训练和部署的模型时要考虑的权衡。总而言之,我们认为通过本篇综述,我们让读者具备了必要的理解能力,可以分解从次优模型到满足他们对质量和内存印迹的模型所需的步骤。

如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
📝 稿件基本要求:
• 文章确系个人原创作品,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬,具体依据文章阅读量和文章质量阶梯制结算
📬 投稿通道:
• 投稿邮箱:hr@paperweekly.site
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02)快速投稿,备注:姓名-投稿

△长按添加PaperWeekly小编
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。












