由于最近经济紧张,昨晚还突然跳出一个想法:要不把公众号卖了吧,因为前几天的确有人来询价。冷静几分钟又考虑了一下,还是自个留着了,当我推送技术文章的时候,我有时候还可以记录一下心情,比如去年大概这时候创立的公众号,到现在还真的收获了很多东西,所以自个留着了,有时候还可以赚点生活费啥的。收获了快乐,但也失去了快乐
有时候我们会看到一些回归得到的图形,绘制出了置信区间的阴影区域,虽然Python中的seaborn中有regplot可以实现,比如去官网看看就知道了,并且很容易指定显示什么水平的置信区间
But,除了seaborn之外还有没有其他的方法把置信区间计算出来,然后fill_between出来呢,答案是可以的,其实原理还是比较easy的,只需要理解这个原理就好了。
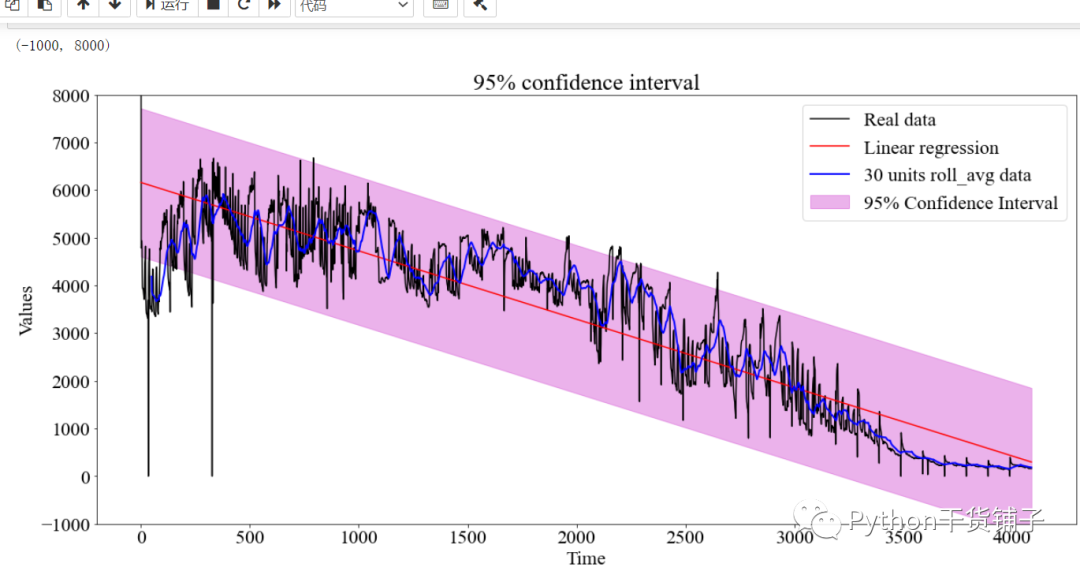
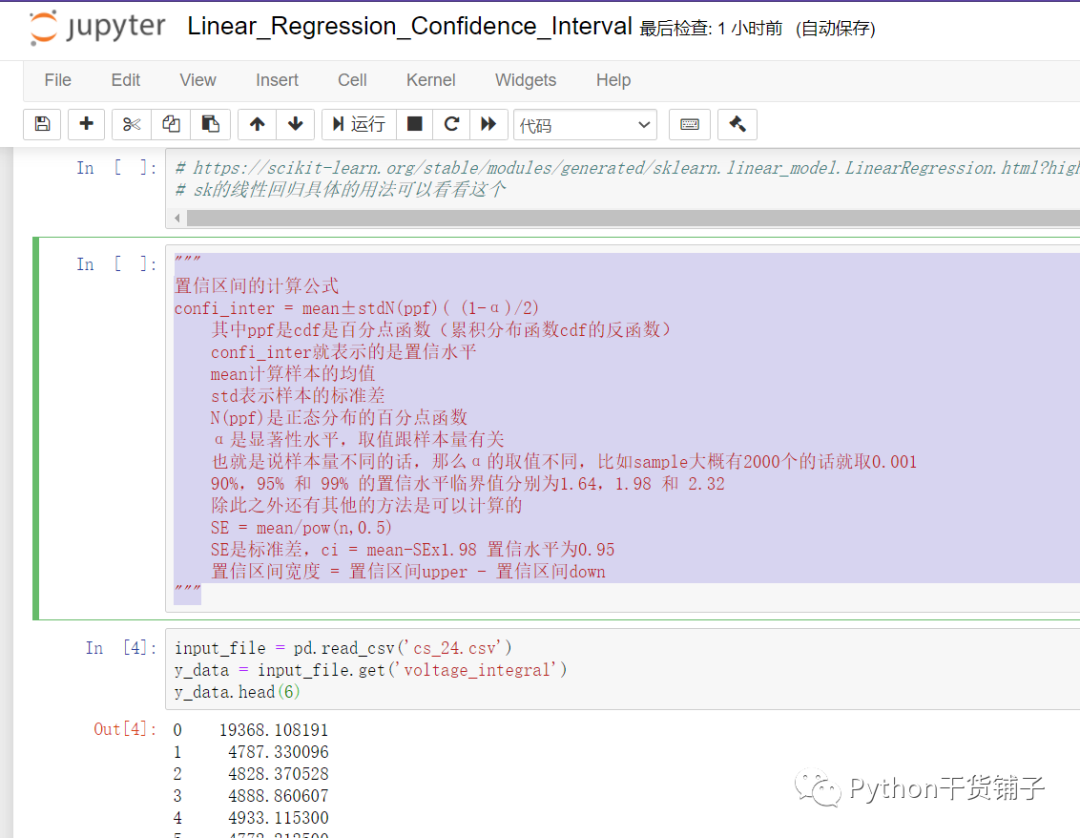
置信区间可计算,可以通过公式计算
"""
置信区间的计算公式
confi_inter = mean±stdN(ppf)( (1-α)/2)
其中ppf是cdf是百分点函数(累积分布函数cdf的反函数)
confi_inter就表示的是置信水平
mean计算样本的均值
std表示样本的标准差
N(ppf)是正态分布的百分点函数
α是显著性水平,取值跟样本量有关
也就是说样本量不同的话,那么α的取值不同,比如sample大概有2000个的话就取0.001
90%,95% 和 99% 的置信水平临界值分别为1.64,1.98 和 2.32
除此之外还有其他的方法是可以计算的
SE = mean/pow(n,0.5)
SE是标准差,ci = mean-SEx1.98 置信水平为0.95
置信区间宽度 = 置信区间upper - 置信区间down
"""
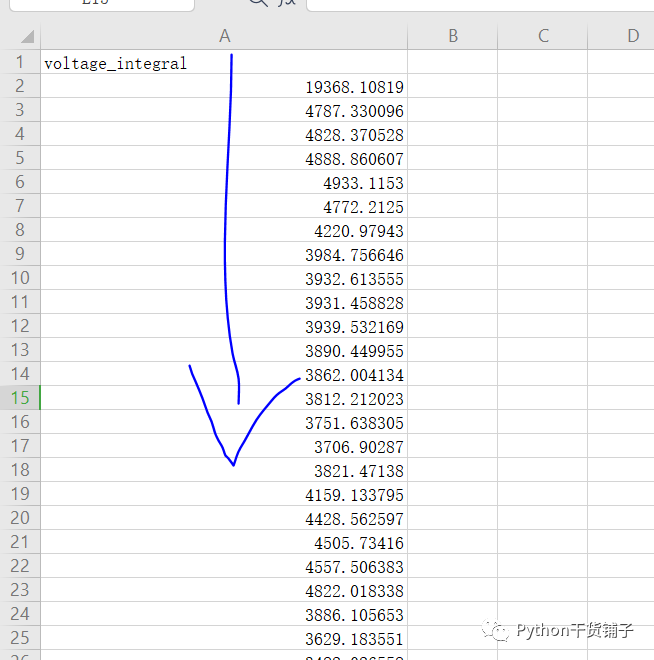
测试使用的电子表格数据是一个一维的,就这么一列,你想几列就几列也可以
导入相关的计算,读取数据和绘制的包
# 基于Python的线性回归制作置信区间from sklearn.linear_model import LinearRegressionimport numpy as npimport pandas as pdimport matplotlib.pyplot as pltfrom scipy.stats.stats import pearsonrfrom scipy import stats
# https://scikit-learn.org/stable/modules/generated/sklearn.linear_model.LinearRegression.html?highlight=linear#sklearn.linear_model.LinearRegression# sk的线性回归具体的用法可以看看这个
我们需要根据原始的cvs数据中的那一列来生成一个横坐标。reshape(-1,1)把生成的x数据reshape到一列去
x_data = np.arange(0,len(y_data), 1)# 由于cvs中的数据只有一列值,所以我们根据这一列值的长度生成一个x序列值作为横坐标x_data_composed = x_data.reshape(-1,1)# reshape(-1,1)把生成的x数据reshape到一列去
绘制出原始数据和利用sk拟合出来的数据看看长什么鬼样子
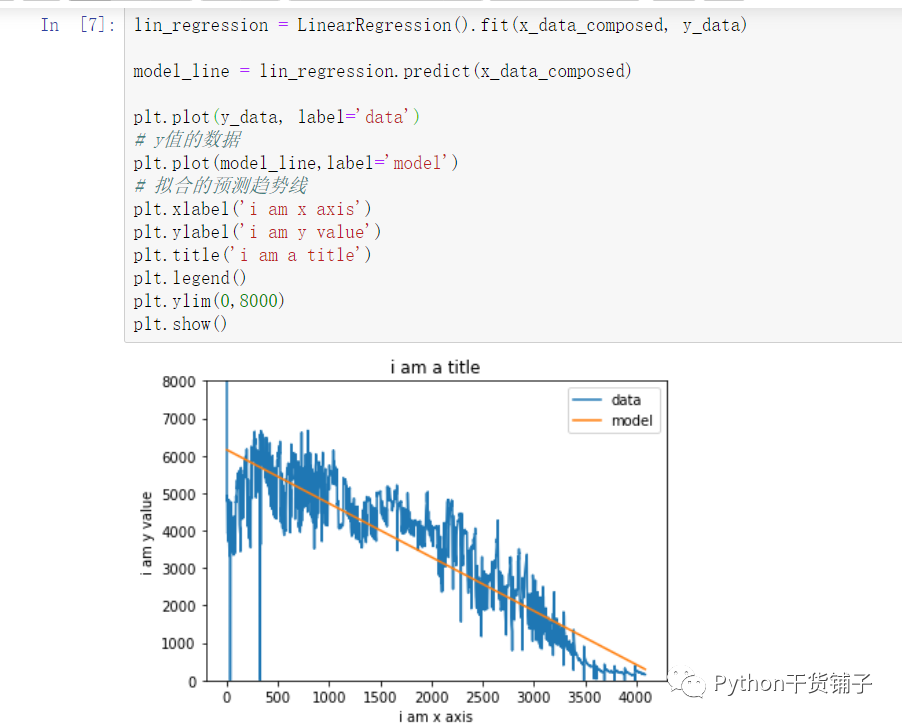
def get_prediction_interval(prediction, y_test, test_predictions, alpha=.95):
sum_errs = np.sum((y_test - test_predictions)**2) stdev = np.sqrt(1 / (len(y_test) - 2) * sum_errs) one_minus_alpha = 1 - alpha ppf_lookup = 1 - (one_minus_alpha / 2) z_score = stats.norm.ppf(ppf_lookup)
interval = z_score * stdev
lower, upper = prediction - interval, prediction + interval return lower, prediction, upper
开始计算置信区间的上下边界,其中的代号前面说过了,比如那个ppf。
lower_a1 = []upper_a2 = []
for i in model_line: lower, prediction, upper = get_prediction_interval(i, y_data, model_line) lower_a1.append(lower) upper_a2.append(upper)
需要是list列表才能使用append()方法,把遍历出来的数据添加到新的列表中去。
最后就是把计算的结果绘制出来看看效果了
plt.rcParams['font.family'] = 'Times New Roman'plt.rcParams['font.size'] = 22plt.figure(figsize=(20,9))
mavg = y_data.rolling(window=50).mean()
plt.fill_between(np.arange(0,len(y_data),1),upper_a2, lower_a1, color='m',label='95% Confidence Interval', alpha=0.3)plt.plot(np.arange(0,len(y_data),1),y_data,color='k',label='Real data')plt.plot(model_line,'r',label='Linear regression')plt.plot(x_data_composed,mavg,color='b',label='30 units roll_avg data',lw=2)plt.title('95% confidence interval')plt.legend()plt.xlabel('Time')plt.ylabel('Values')plt.ylim(-1000,8000)
所以最后的原理是什么呢?-------就是计算出置信区间的上下界,然后老套路fill_between()给它们绘制出来就行了。fill_between(x,y1,y2),x就是横坐标,后面两个是line,就在这两个线之间fill就行了
看到这了,老铁点个赞和在看呗,别忘记分享喔











