Mointoring Scientific Python Usage on a Supercomputer
Thomas R, Stephey L, Greiner A, et al. Monitoring Scientific Python Usage on a Supercomputer[C]. Proceedings of the 20th Python in Science Conference (SciPy 2021). 2021. 101 - 109
本文发表于 SciPy 2021 会议,介绍如何监控高性能计算机上的 Python 库的使用情况,并对监控数据进行分析。
注:以下正文部分翻译自论文,并根据笔者个人理解有所删改整合
正文
本文包含两个主要内容:
介绍
工作负载分析 (Workload analysis) 是收集和整理数据以构建应用程序和用户如何真正与系统交互和利用系统的画像的过程。可以用于:
全面、定量的工作负载分析是使 NERSC 成为高效的科学超级计算机中心的 关键 工具。
NERSC 中 Python 的用途包括:
编排模拟试验
注:NWPC 使用 ecFlow 的 Python API 构建 NWP 业务系统
运行复杂数据处理管道
注:NWPC 越来越多使用 Python 处理模式数据
管理人工智能工作流
注:NWPC 正在使用 Python 构建使用人工智能算法的业务系统
可视化大型数据集
注:使用 Python 开发可视化工具的难度远远低于桌面应用,笔者已从 C++/Qt 转型 Python
…
相关研究
使用 software environment modules 统计:注入 module load 操作。劣势:.bashrc 中加载包会带来错误数据,也无法获取 Python 包导入信息。
编译连接过程添加信息到可执行文件头,作业调度器执行程序时读取信息。ALTD [Fah10],XALT [Agr14]
使用 Python 内置特性 sitecustomize 和 atexit,在程序退出时检查 sys.modules 变量。限制:异常中止时无法记录。[Mac 17]
本文使用 非侵入性工具 + 用户跟进 相结合的策略。
方法
本文目标是收集所有 Python 环境的使用信息,NERSC 的 Python 环境,
默认 Python 环境,通过 module 提供。用户可以使用 conda 创建自己的 conda 环境
共享 Python 环境,使用 conda 创建,或用户自行安装的环境
Cray Python 环境,包可以由工作人员或用户使用 Spack 安装
Shifter,使用用户自定义 Python 环境的 Docker 镜像
注:CMA PI 上可以使用前两种环境
本文使用 [Mac17] 中的方法,并略有修改,捕获数据的架构如下图所示
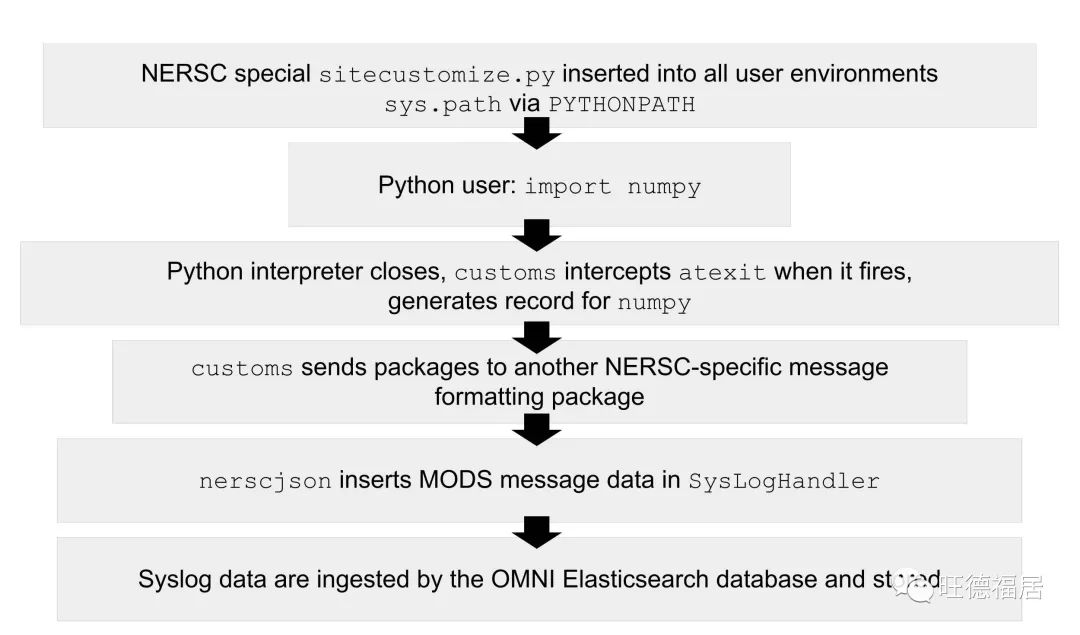
捕获 Python 使用数据的基础架构,图片来自论文
捕获 Python 使用数据:
将 customs 包安装到计算节点,避免在大规模集群中启动 Python 时非常糟糕的性能
配置默认用户环境,通过 PYTHONPATH 将 sitecustomize 添加到 sys.path 中。Shifter 容器通过挂载镜像方式引入监控包
用户执行 Python 代码,包含导入语句:import numpy
Python 解释器关闭,atexit 触发 customs,为 numpy 生成记录
customs 将包记录发送给另一个 NERSC 定制的消息格式化包
nerscjson 将 MODS 消息数据插入到 SysLogHandler
Syslog 数据被 OMNI Elasticsearch 数据库摄取并存储
本文选择 opt-out 模式
Customs
Customs 包:使用 sitecustomize 逻辑,用于检查和报告特性 Python 包的导入情况。
三个基本组件:
Check:代表 Python 包名的一个简单对象,可以调用,检查包是否在给定字典 (sys.modules) 中存在
Inspector:Check 对象容器,用于将每个 Check 应用到 sys.modules 并返回包含的包名
Reporter:接收报名列表并执行某项操作的抽象类,执行操作与具体实现有关
注册函数 register_exit_hook:用于 sitecustomize.py 中。接收两个函数:包名称列表,Reporter 类型
消息日志和存储
nerscjson:轻量级消息日志抽象层
消费 JSON 消息,并转发给连接 NERSC OMNI (Operations Monitoring and Notification Infrastructure) 的传输层。
目前通过 SysLogHandler 实现,消息发送给对应的 Elasticsearch 索引。在计算节点使用 Cray Lightweight Log Manager (LLM) 实现消息转发,其他节点使用 syslog。未来考虑使用 Apache Kafka 或 Lightweight Distributed Metrics Service。
包筛选:只发送备选列表中的 50 个 Python 库,减少发送量。
表 1 附加监控元数据
| 字段 | 描述 |
|---|
executable | 进程使用的 Python 可执行程序路径 |
is_compute | 是否运行在计算节点中 |
is_shifter | 是否运行在 Shifter 容器中 |
is_staff | 用户是否是 NERSC 员工 |
job_id | Slurm 作业 ID |
main | 应用路径,如果存在 |
num_nodes | 作业节点数 |
qos | 批处理作业队列 |
repo | 批处理作业记账 (charge account) |
subsystem | 系统分区或集群 |
system | 系统名称 |
username | 用户句柄 |
MPI 处理:为减少 MPI 程序的消息发送量,阻止非零 MPI rank 或 SLURM_PROCID 进程发送消息。
附加关键信息:包含足够的额外信息。其他诸如使用 multiprocessing 的并行应用更难去重,将在分析阶段进行。
与现有数据关联:通过 Slurm 作业数据 (job_id),身份 (username) 或 banking (repo) 与现有数据对接。
检测消息是否有遗漏:定时发送 canary jobs,统计一定时间内接收到的个数。
原型、产品和发布
分析工具:Python
NERSC 已有 Kibana 服务,但不方便处理重复数据。选择 Python 生态系统处理数据。
交互数据分析:Jupyter Notebook
特点:
记录分析过程
编写文档
分享,其他用户可以重新执行或重新生成结果
注:NERSC 已有 JupyterHub,而 NWPC 尚未建立公共使用的 JupyterHub,期望 CMADaaS 能面向全体用户提供 Jupyter 托管服务
交互效率:CPU vs GPU
虽然数据可以放入内存中,或者使用多个计算节点使用 CPU 分析,但 GPU 可以比 CPU 使用更少的节点分析数据。
使用 Dask-cuDF 和 cuDF 进行交互分析,原型开发和数据探索
使用 Dask-CUDA 构建 GPU 集群
Jupyter 笔记本使用 BatchSpawner 从 JupyterHub 中启动
输入数据为 compressed Parquet 格式,使用 Dask-cuDF 直接载入到 GPU 内存中。
输入数据来自 OMNI,使用 Python Elasticsearch API 提取并转换成 Parquet 格式保存
注:从一种格式转为便于分析的另一种格式,例如从 ElasticSearch 数据库转为 Parquet 文件,可以用于归档 ES 库中的历史数据。
从原型到生成环境
将数据分析的原型代码转为生产代码的两种方案:
将 Notebook 代码转换脚本
将 Notebook 扩展成生产工具
本文选择第二种方式,使用 Papermill 执行参数化脚本
注:笔者不推荐在生产环境中使用 Notebook,使用脚本更容易促使开发者对代码进行整合和复用
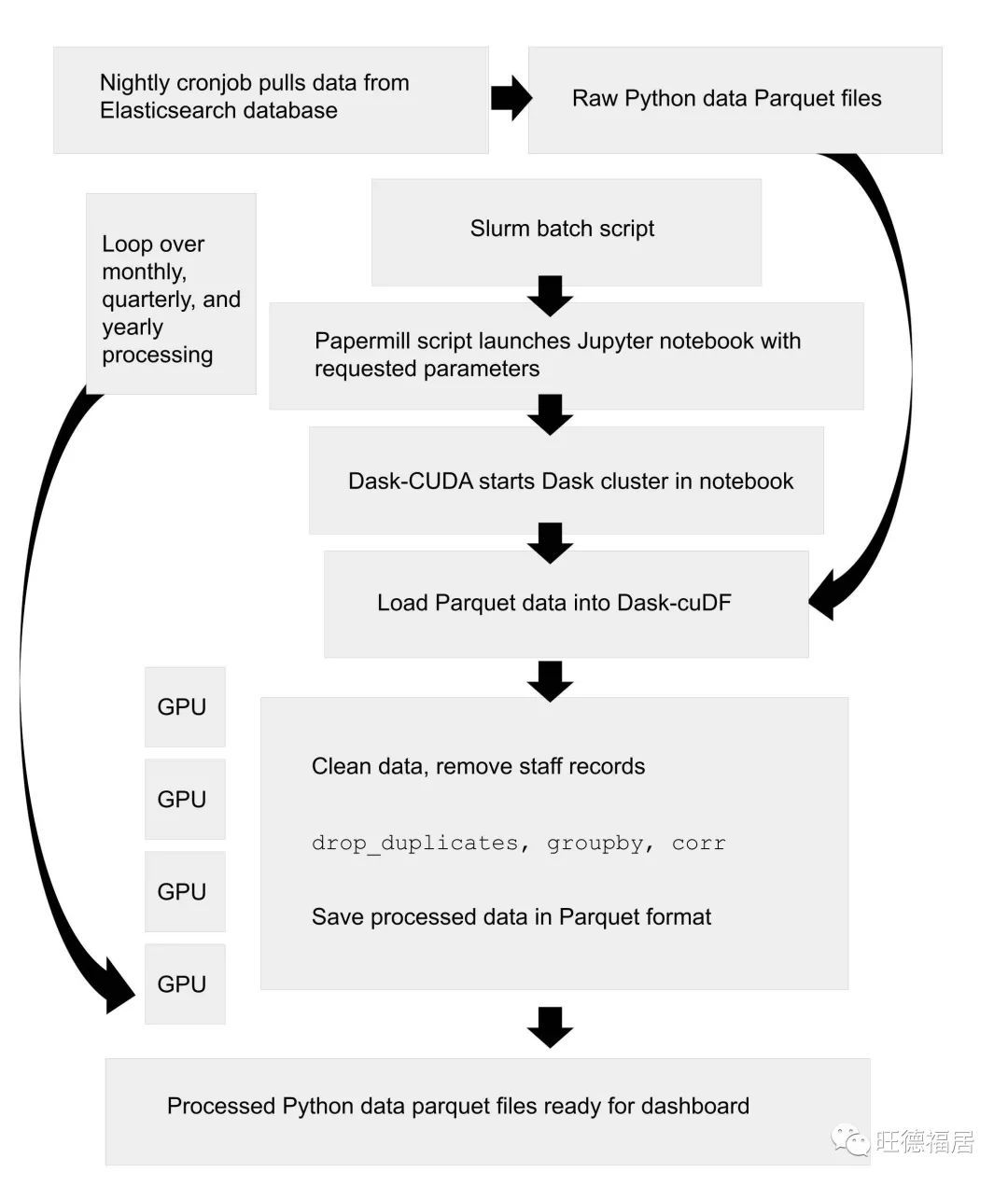
处理和分析 Python 使用数据的工作流,图片来自论文
可视化:Voila
使用 Voila 将 Jupyter 笔记本渲染为独立的 Web 服务。本文使用 NERSC 的 Docker CAAS 平台 Spin 运行面板,Spin 在 HPC 外部,不包含 GPU 节点,但挂载 NERSC Gobal Filesystem。
注:缺少全局文件系统导致 HPC 与外部局域网沟通不畅,可惜从现有规划看未来依然不会采用类似的方案
优化
单个笔记本中执行 GPU 和 CPU 计算。使用元数据标签区分不同的类型
第一部分:Dask 集群,GPU 工具处理数据
第二部分:归约数据,使用 CPU 进行面板可视化
Vaex 处理数据,利用 CPU 多线程并行机制,代替 Pandas。Seaborn + Matplotlib 实现绘图。
使用单个镜像管理数据分析和数据可视化的 Python 环境。
结果
注:本节图片均来自论文
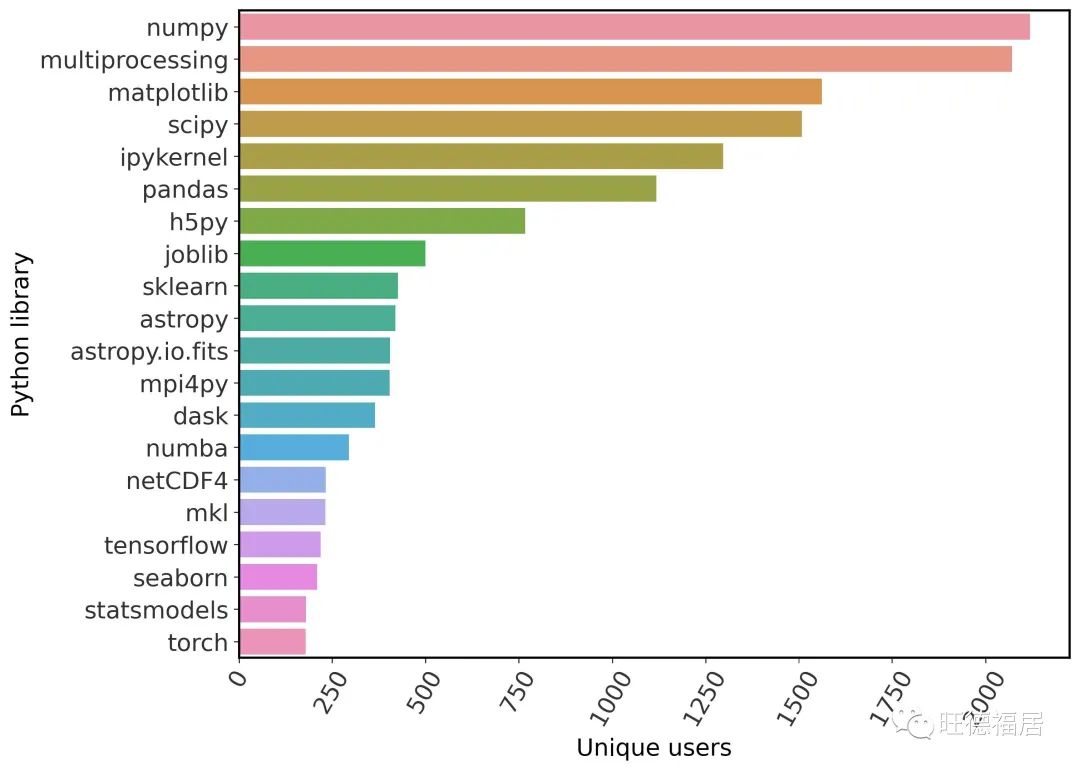
NERSC 跟踪的前 20 位 Python 库,根据用户去重
Tensorflow 和 PyTorch 使用量低主要是因为只有 18 个 GPU 节点,同时用户提交 ML 训练任务可能中途意外退出而没有触发 atexit。
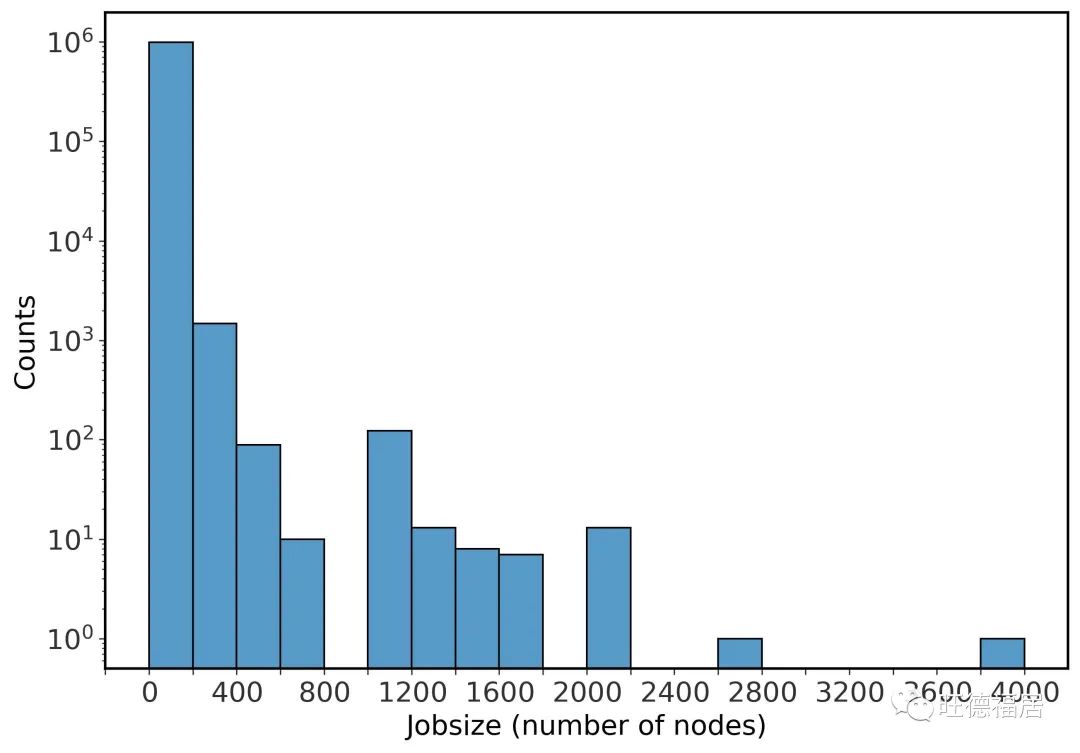
使用 Python 的批处理作业使用节点数分布
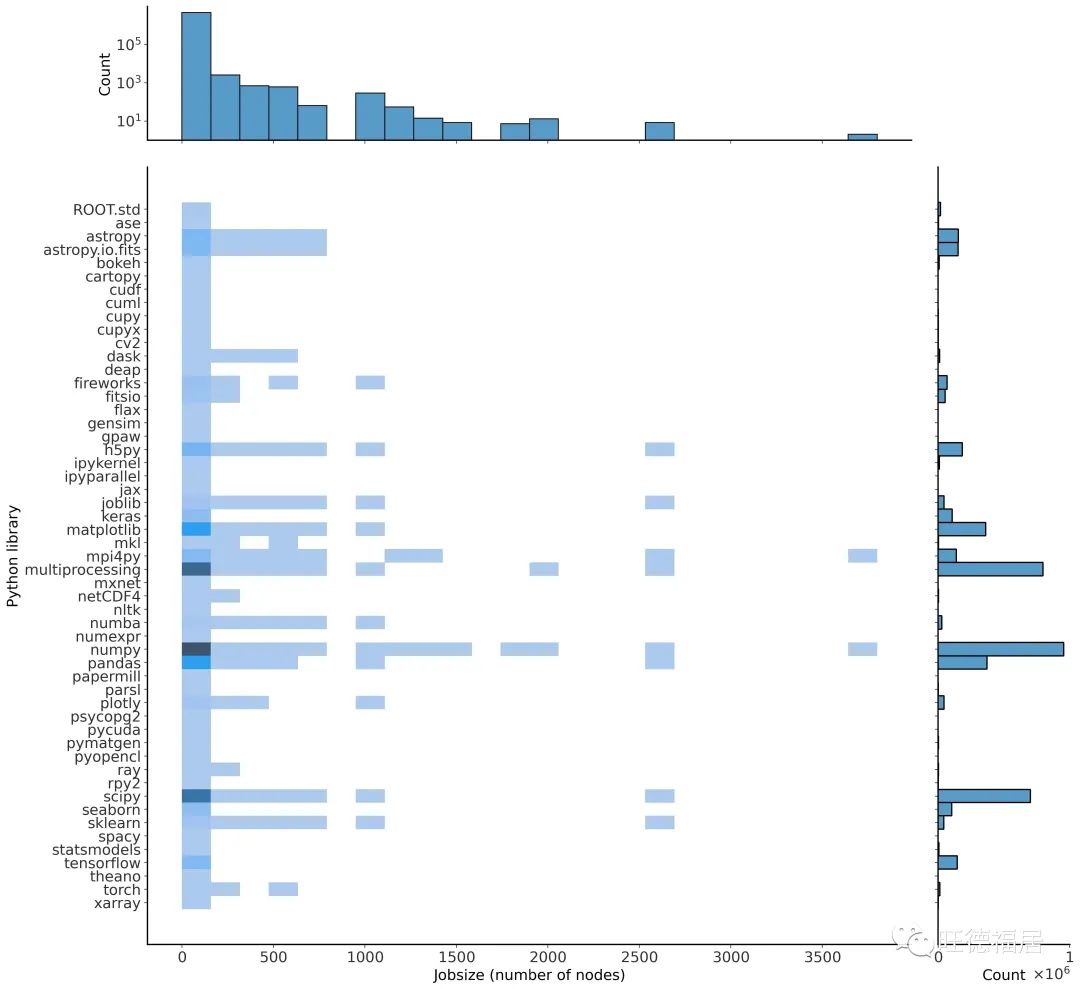
Python 包计数与作业节点的二维直方图。
x 轴 (右) 显示包总数,y 轴 (顶部) 显示以对数刻度显示的总作业计数。在这里,我们测量的是作业中使用的独特包的数量,而不是作业的数量,因此这些数据无法直接与图 3 或图 4 进行比较。
mpi4py 和 NumPy 数量最多。Dask 使用在 500 或更少的节点中,似乎不如 mpi4py 更有扩展性。
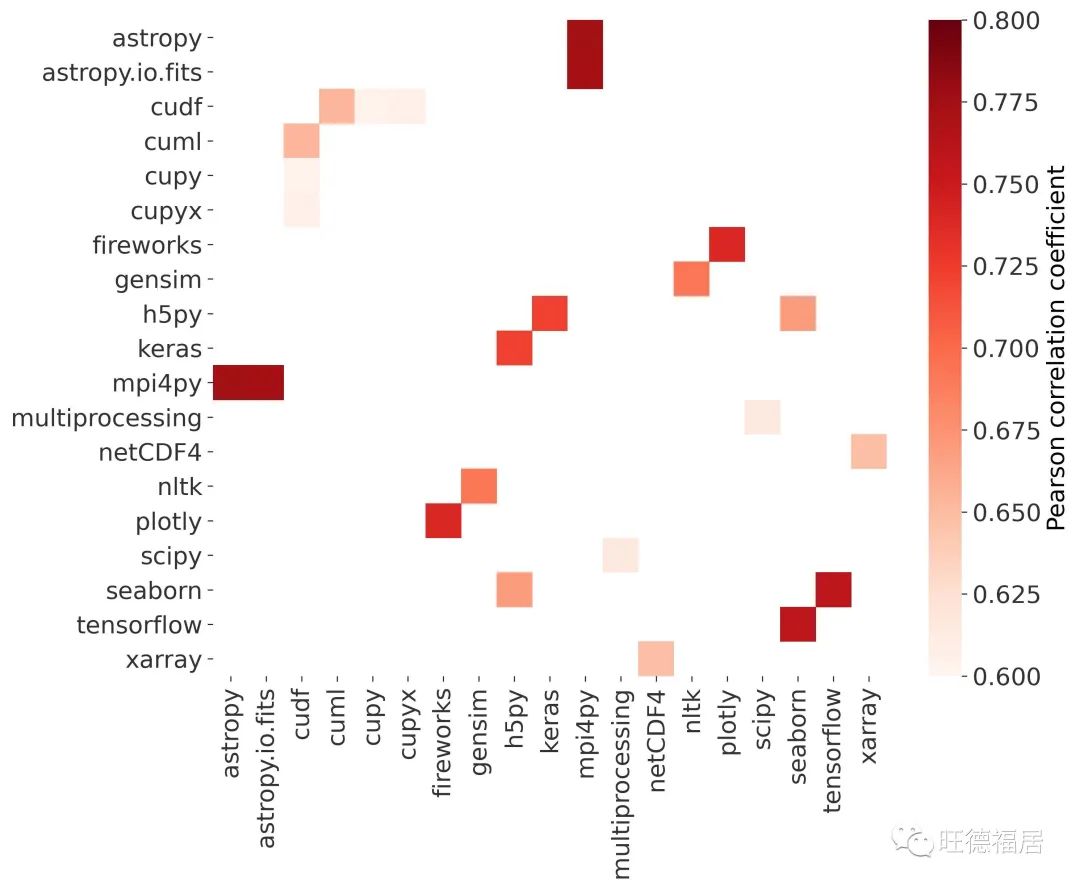
同一作业中跟踪的 Python 库的 Pearson 相关系数。
每个库在作业中只计算一次。上图显示了 0.6 和 0.8 之间的相关系数值,以突出显示包具有强关系但没有明确依赖关系的机制。相互关联的库:
mpi4py 和 AstroPy
Seaborn 和 Tensorflow
FireWorks 和 Plotly
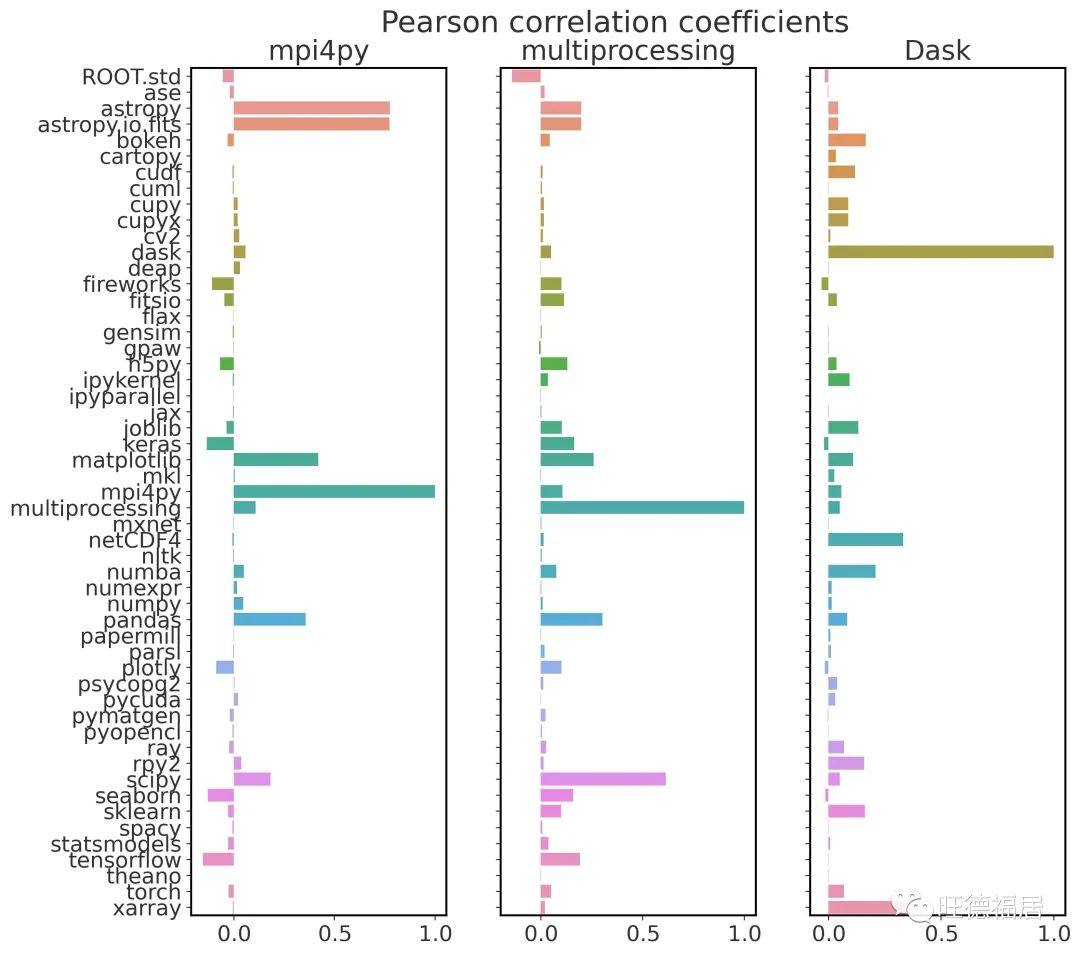
mpi4py (左)、多处理 (中) 和 Dask (右) 的 Pearson 相关系数值,以及我们目前跟踪的所有其他 Python 库。
注:关联性可能来自库内部的调用,而用户自身并没有显示调用某个库。比如 Dask 与 Xarray,multiprocessing 与 SciPy。
讨论
论文发现用户倾向于使用自己的 Python 版本,用户常常需要比统一管理的 Python 环境更新版本的包。论文认为,与其将此作为应该更频繁地更新 NERSC 提供的 Python 环境的提示,不如寻找新的方法让用户能够更好地管理自己的软件,这已成为首要任务。包括继续提供对 Conda 环境的轻松访问、集中安装的位置 (即通过协作共享) 以及改进对容器化环境的支持。但是,作者们也一直在重新评估如何最好地支持用户的需求。
注:CMA 即将转为内外分离的网络架构,意味着桌面电脑无法同时连接互联网和 HPC 网络,在 HPC 上将无法通过代理方式从互联网更新 Python 包。如果不引入其他机制,用户自行安装 Python 环境将变得更加困难。
仅有 17% 用户使用基于 OpenMP threaded, optimized Intel MKL 的 Numpy,SciPy,scikit-learn 和 NumExpr 库。用户倾向于使用 mpi4py 库实现并行,并使用 conda-forge 安装软件包 (使用 OpenBLAS),愿意牺牲一部分效率而选择更方便的安装。
本文分析方法存在一些陷阱:
目前仅收集预定义列表中的包使用数据
用户可以选择关闭数据收集
应用到达墙钟时间退出,不会触发数据收集过程
虚假导入问题,导入而没有实际使用
总结
开发一个 Python 包用于统计关键科学 Python 包的导入使用情况。
本文方法可以推广到任意 Python 数据科学数据管道。
未来将基于用户分组,使用 NLP 和 ML 分析用户使用 Python 存在的潜在问题,并使用收集到的数据向用户提供使用建议。
https://mods.nersc.gov/public/
参考文献
部分参考文献
监控
[Bau19] E. Bautista, et al., Collecting, Monitoring, and Analyzing Facility and Systems Data at the National Energy Research Scientific Computing Center, 48th International Conference on Parallel Processing: Workshops (ICPP 2019), Kyoto, Japan, 2019. https://doi.org/10.1145/3339186.3339213
[Mac17] C. MacLean. Python Usage Metrics on Blue Waters Proceedings of the Cray User Group, Redmond, WA, 2017.
[Mcl11] R. McLay, K.W. Schulz,W. L. Barth, and T. Minyard, Best practices for the deployment and management of production HPC clusters in State of the Practice Reports, SC11, Seattle, WA, 2011. https://doi.acm.org/10.1145/2063348.2063360
工作流
[Bab19] Y. Babuji, et al., Parsl: Pervasive Parallel Programming in Python, 28th ACM International Symposium on High-Performance Parallel and Distributed Computing (HPDC), Phoenix, AZ, 2019. https://doi.org/10.1145/3307681.3325400
[Jai15] Jain, A., et al., FireWorks: a dynamic workflow system designed for high-throughput applications. Concurrency Computat.: Pract. Exper., 27: 5037–5059, 2015. https://doi.org/10.1002/cpe.3505
工具
[Gam15] T. Gamblin, et al., The Spack Package Manager: Bringing Order to HPC Software Chaos, in Supercomputing 2015, SC15, Austin, TX, 2015. https://doi.org/10.1145/2807591.2807623
讨论
本文介绍了数据收集和分析的一种通用方法,使用不同的工具栈进行获取和分析。
该方式与笔者在 NWPC 消息平台中采用的方法大体相同。不同之处在于,论文使用 Python 实现两个步骤,而 NWPC 消息平台使用 Golang 获取并保存数据,使用 Python 分析数据。
论文在数据获取方面的技术更多涉及操作系统层面,不适合 NWPC 消息平台这种单纯的应用软件,因为笔者没有管理员权限,无法使用操作系统底层服务。
论文在数据分析方面的技术则非常适合引入到 NWPC 消息平台中。包括
如果进一步开发 NWPC 消息平台,可以参考本论文对数据分析部分进行优化。
参考
论文原文
http://conference.scipy.org/proceedings/scipy2021/pdfs/rollin_thomas.pdf
Python 使用情况:
https://mods.nersc.gov/public/

题图由Gerhard G. 在 Pixabay 上发布、











