本教程内容旨在帮助没有基础的同学快速掌握 numpy 的常用功能,保证日常绝大多数场景的使用。可作为机器学习或深度学习的先修课程,也可作为快速备查手册。
值得一提的是,深度学习的各大框架很多 API 和 numpy 也是一脉相承的哦,可以说 numpy 玩儿熟了,几个深度学习框架的不少 API 也同时学会了。本文是教程的「第一部分」,从实际的代码应用出发,讲解了Numpy创建到统计的操作。
开源项目地址:https://github.com/datawhalechina/powerful-numpy
注:B站有作者倾情讲解的视频教程(B站观看人数破万啦٩(๑>◡二次元的Datawhale搜索「巨硬的Numpy」,获取一手讲解。
使用说明:内容中⭐(1-5个)表示重要程度,越多越重要;⚠️ 表示需要特别注意的提示:使用过程中无须过多关注 API 各种参数细节,教程提供的用法足以应付绝大部分场景,更深入的可自行根据需要探索或学习后续的教程。
# 导入 library
import numpy as np
# 画图工具
import matplotlib.pyplot as plt
创建和生成
本节主要介绍 array 的创建和生成。为什么会把这个放在最前面呢?主要有以下两个方面原因:
首先,在实际工作过程中,我们时不时需要验证或查看 array 相关的 API 或互操作。同时,有时候在使用 sklearn,matplotlib,PyTorch,Tensorflow 等工具时也需要一些简单的数据进行实验。
所以,先学会如何快速拿到一个 array 是有很多益处的。本节我们主要介绍以下几种常用的创建方式:
使用列表或元组
使用 arange
使用 linspace/logspace
使用 ones/zeros
使用 random
从文件读取
其中,最常用的一般是 linspace/logspace 和 random,前者常常用在画坐标轴上,后者则用于生成「模拟数据」。举例来说,当我们需要画一个函数的图像时,X 往往使用 linspace 生成,然后使用函数公式求得 Y,再 plot;当我们需要构造一些输入(比如 X)或中间输入(比如 Embedding、hidden state)时,random 会异常方便。
从 python 列表或元组创建
⭐⭐ 重点掌握传入 list 创建一个 array 即可:np.array(list)
⚠️ 需要注意的是:「数据类型」。如果您足够仔细的话,可以发现下面第二组代码第 2 个数字是「小数」(注:Python 中 1. == 1.0),而 array 是要保证每个元素类型相同的,所以会帮您把 array 转为一个 float 的类型。
# 一个 list
np.array([1,2,3])
array([1, 2, 3])
# 二维(多维类似)
# 注意,有一个小数哦
np.array([[1, 2., 3], [4, 5, 6]])
array([[1., 2., 3.],
[4., 5., 6.]])
# 您也可以指定数据类型
np.array([1, 2, 3], dtype=np.float16)
array([1., 2., 3.], dtype=float16)
# 如果指定了 dtype,输入的值都会被转为对应的类型,而且不会四舍五入
lst = [
[1, 2, 3],
[4, 5, 6.8]
]
np.array(lst, dtype=np.int32)
array([[1, 2, 3],
[4, 5, 6]], dtype=int32)
# 一个 tuple
np.array((1.1, 2.2))
array([1.1, 2.2])
# tuple,一般用 list 就好,不需要使用 tuple
np.array([(1.1, 2.2, 3.3), (4.4, 5.5, 6.6)])
array([[1.1, 2.2, 3.3],
[4.4, 5.5, 6.6]])
# 转换而不是上面的创建,其实是类似的,无须过于纠结
np.asarray((1,2,3))
array([1, 2, 3])
np.asarray(([1., 2., 3.], (4., 5., 6.)))
array([[1., 2., 3.],
[4., 5., 6.]])
使用 arange 生成
⭐⭐
range 是 Python 内置的整数序列生成器,arange 是 numpy 的,效果类似,会生成一维的向量。我们偶尔会需要使用这种方式来构造 array,比如:
- 需要创建一个连续一维向量作为输入(比如编码位置时可以使用)
- 需要观察筛选、抽样的结果时,有序的 array 一般更加容易观察
⚠️ 需要注意的是:在 reshape 时,目标的 shape 需要的元素数量一定要和原始的元素数量相等。
np.arange(12).reshape(3, 4)
array([[ 0, 1, 2, 3],
[ 4, 5, 6, 7],
[ 8, 9, 10, 11]])
# 注意,是小数哦
np.arange(12.0).reshape(4, 3)
array([[ 0., 1., 2.],
[ 3., 4., 5.],
[ 6., 7., 8.],
[ 9., 10., 11.]])
np.arange(100, 124, 2).reshape(3, 2, 2
array([[[100, 102],
[104, 106]],
[[108, 110],
[112, 114]],
[[116, 118],
[120, 122]]])
# shape size 相乘要和生成的元素数量一致
np.arange(100., 124., 2).reshape(2,3,4)
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
in
----> 1 np.arange(100., 124., 2).reshape(2,3,4)
ValueError: cannot reshape array of size 12 into shape (2,3,4)
使用 linspace/logspace 生成
⭐⭐⭐
OK,这是我们遇到的第一个比较重要的 API,前者需要传入 3 个参数:开头,结尾,数量;后者需要额外传入一个 base,它默认是 10。
⚠️ 需要注意的是:第三个参数并不是步长。
np.linspace
# 线性
np.linspace(0, 9, 10).reshape(2, 5)
array([[0., 1., 2., 3., 4.],
[5., 6., 7., 8., 9.]])
np.linspace(0, 9, 6).reshape(2, 3)
array([[0. , 1.8, 3.6],
[5.4, 7.2, 9. ]])
# 指数 base 默认为 10
np.logspace(0, 9, 6, base=np.e).reshape(2, 3)
array([[1.00000000e+00, 6.04964746e+00, 3.65982344e+01],
[2.21406416e+02, 1.33943076e+03, 8.10308393e+03]])
# _ 表示上(最近)一个输出
# logspace 结果 log 后就是上面 linspace 的结果
np.log(_)
array([[0. , 1.8, 3.6],
[5.4, 7.2, 9. ]])
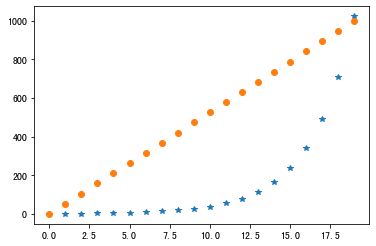
下面我们更进一步看一下:
N = 20
x = np.arange(N)
y1 = np.linspace(0, 10, N) * 100
y2 = np.logspace(0, 10, N, base=2)
plt.plot(x, y2, '*');
plt.plot(x, y1, 'o');
# 检查每个元素是否为 True
# base 的 指数为 linspace 得到的就是 logspace
np.alltrue(2 ** np.linspace(0, 10, N) == y2)
True
⚠️ 补充:关于 array 的条件判断
# 不能直接用 if 判断 array 是否符合某个条件
arr = np.array([1, 2, 3])
cond1 = arr > 2
cond1
array([False, False, True])
if cond1:
print("这不行")
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
in
----> 1 if cond1:
2 print("这不行")
ValueError: The truth value of an array with more than one element is ambiguous. Use a.any() or a.all()
# 即便你全是 True 它也不行
arr = np.array([1, 2, 3])
cond2 = arr > 0
cond2
array([ True, True, True])
if cond2:
print("这还不行")
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
in
----> 1 if cond2:
2 print("这还不行")
ValueError: The truth value of an array with more than one element is ambiguous. Use a.any() or a.all()
# 咱们只能用 any 或 all,这个很容易犯错,请务必注意。
if cond1.any():
print("只要有一个为True就可以,所以——我可以")
只要有一个为True就可以,所以——我可以
if cond2.all():
print("所有值为True才可以,我正好这样")
所有值为True才可以,我正好这样
使用 ones/zeros 创建
⭐
创建全 1/0 array 的快捷方式。需要注意的是 np.zeros_like 或 np.ones_like,二者可以快速生成给定 array 一样 shape 的 0 或 1 向量,这在需要 Mask 某些位置时可能会用到。
⚠️ 需要注意的是:创建出来的 array 默认是 float 类型。
np.ones(3)
array([1., 1., 1.])
np.ones((2, 3))
array([[1., 1., 1.],
[1., 1., 1.]])
np.zeros((2,3,4))
array([[[0., 0., 0., 0.],
[0., 0., 0., 0.],
[0., 0., 0., 0.]],
[[0., 0., 0., 0.],
[0., 0., 0., 0.],
[0., 0., 0., 0.]]])
# 像给定向量那样的 0 向量(ones_like 是 1 向量)
np.zeros_like(np.ones((2,3,3)))
array([[[0., 0., 0.],
[0., 0., 0.],
[0., 0., 0.]],
[[0., 0., 0.],
[0., 0., 0.],
[0., 0., 0.]]])
使用 random 生成
⭐⭐⭐⭐⭐
如果要在这一节选一个最重要的 API,那一定是 random 无疑了,这里我们只介绍几个比较常用的「生产」数据相关的 API。它们经常用于随机生成训练或测试数据,神经网路初始化等。
⚠️ 需要注意的是:这里我们统一推荐使用新的 API 方式创建,即通过 np.random.default_rng() 先生成 Generator,然后再在此基础上生成各种分布的数据(记忆更加简便清晰)。不过我们依然会介绍就的 API 用法,因为很多代码中使用的还是旧的,您可以混个眼熟。
# 0-1 连续均匀分布
np.random.rand(2, 3)
array([[0.42508994, 0.5842191 , 0.09248675],
[0.656858 , 0.88171822, 0.81744539]])
# 单个数
np.random.rand()
0.29322641374172986
# 0-1 连续均匀分布
np.random.random((3, 2))
array([[0.17586271, 0.5061715 ],
[0.14594537, 0.34365713],
[0.28714656, 0.40508807]])
# 指定上下界的连续均匀分布
np.random.uniform(-1, 1, (2, 3))
array([[ 0.66638982, -0.65327069, -0.21787878],
[-0.63552782, 0.51072282, -0.14968825]])
# 上面两个的区别是 shape 的输入方式不同,无伤大雅了
# 不过从 1.17 版本后推荐这样使用(以后大家可以用新的方法)
# rng 是个 Generator,可用于生成各种分布
rng = np.random.default_rng(42)
rng
Generator(PCG64) at 0x111B5C5E0
# 推荐的连续均匀分布用法
rng.random((2, 3))
array([[0.77395605, 0.43887844, 0.85859792],
[0.69736803, 0.09417735, 0.97562235]])
# 可以指定上下界,所以更加推荐这种用法
rng.uniform(0, 1, (2, 3))
array([[0.47673156, 0.59702442, 0.63523558],
[0.68631534, 0.77560864, 0.05803685]])
# 随机整数(离散均匀分布),不超过给定的值(10)
np.random.randint(10, size=2)
array([6, 3])
# 随机整数(离散均匀分布),指定上下界和 shape
np.random.randint(0, 10, (2, 3))
array([[8, 6, 1],
[3, 8, 1]])
# 上面推荐的方法,指定大小和上界
rng.integers(10, size=2)
array([9, 7])
# 上面推荐的方法,指定上下界
rng.integers(0, 10, (2, 3))
array([[5, 9, 1],
[8, 5, 7]])
# 标准正态分布
np.random.randn(2, 4)
array([[-0.61241167, -0.55218849, -0.50470617, -1.35613877],
[-1.34665975, -0.74064846, -2.5181665 , 0.66866357]])
# 上面推荐的标准正态分布用法
rng.standard_normal((2, 4))
array([[ 0.09130331, 1.06124845, -0.79376776, -0.7004211 ],
[ 0.71545457, 1.24926923, -1.22117522, 1.23336317]])
# 高斯分布
np.random.normal(0, 1, (3, 5))
array([[ 0.30037773, -0.17462372, 0.23898533, 1.23235421, 0.90514996],
[ 0.90269753, -0.5679421 , 0.8769029 , 0.81726869, -0.59442623],
[ 0.31453468, -0.18190156, -2.95932929, -0.07164822, -0.23622439]])
# 上面推荐的高斯分布用法
rng.normal(0, 1, (3, 5))
array([[ 2.20602146, -2.17590933, 0.80605092, -1.75363919, 0.08712213],
[ 0.33164095, 0.33921626, 0.45251278, -0.03281331, -0.74066207],
[-0.61835785, -0.56459129, 0.37724436, -0.81295739, 0.12044035]])
总之,一般会用的就是2个分布:均匀分布和正态(高斯)分布。另外,size 可以指定 shape。
rng = np.random.default_rng(42)
# 离散均匀分布
rng.integers(low=0, high=10, size=5)
array([0, 7, 6, 4, 4])
# 连续均匀分布
rng.uniform(low=0, high=10, size=5)
array([6.97368029, 0.94177348, 9.75622352, 7.61139702, 7.86064305])
# 正态(高斯)分布
rng.normal(loc=0.0, scale=1.0, size=(2, 3))
array([[-0.01680116, -0.85304393, 0.87939797],
[ 0.77779194, 0.0660307 , 1.12724121]])
从文件读取
⭐
这小节主要用于加载实现存储好的权重参数或预处理好的数据集,有时候会比较方便,比如训练好的模型参数加载到内存里用来提供推理服务,或者耗时很久的预处理数据直接存起来,多次实验时不需要重新处理。
⚠️ 需要注意的是:存储时不需要写文件名后缀,会自动添加。
# 直接将给定矩阵存为 a.npy
np.save('./data/a', np.array([[1, 2, 3], [4, 5, 6]]))
# 可以将多个矩阵存在一起,名为 `b.npz`
np.savez("./data/b", a=np.arange(12).reshape(3, 4), b=np.arange(12.).reshape(4, 3))
# 和上一个一样,只是压缩了
np.savez_compressed("./data/c", a=np.arange(12).reshape(3, 4), b=np.arange(12.).reshape(4, 3))
# 加载单个 array
np.load("data/a.npy")
array([[1, 2, 3],
[4, 5, 6]])
# 加载多个,可以像字典那样取出对应的 array
arr = np.load("data/b.npz")
arr["a"]
array([[ 0, 1, 2, 3],
[ 4, 5, 6, 7],
[ 8, 9, 10, 11]])
arr["b"]
array([[ 0., 1., 2.],
[ 3., 4., 5.],
[ 6., 7., 8.],
[ 9., 10., 11.]])
# 后缀都一样,你干脆当它和上面的没区别即可
arr = np.load("data/c.npz")
arr["b"]
array([[ 0., 1., 2.],
[ 3., 4., 5.],
[ 6., 7., 8.],
[ 9., 10., 11.]])
统计和属性
本节我们从 array 的基本统计属性入手,对刚刚创建的 array 进一步的了解。主要包括以下几个方面:
都是描述性统计相关的指标,对于我们从整体了解一个 array 很有帮助。其中,用到最多的是尺寸相关的「shape」,最大、最小值,平均值、求和等。
本节的内容非常简单,您只需要特别关注(记住)两个重要的特性:
- 按维度(指定 axis)求结果。一般0表示列1表示行,可以用「沿着行/列操作」这样理解,不确定时可以拿个例子试一下。
另外,为了便于操作,我们使用一个随机生成的 array 作为操作对象;同时,我们指定了 seed,这样每次运行,每个人看到的结果都是一样的。一般我们在训练模型时,往往需要指定 seed,这样才能在「同等条件」下进行调参。
# 先创建一个 Generator
rng = np.random.default_rng(seed=42)
# 再生成一个均匀分布
arr = rng.uniform(0, 1, (3, 4))
arr
array([[0.77395605, 0.43887844, 0.85859792, 0.69736803],
[0.09417735, 0.97562235, 0.7611397 , 0.78606431],
[0.12811363, 0.45038594, 0.37079802, 0.92676499]])
尺寸相关
⭐⭐
这一小节主要包括:维度、形状和数据量,其中形状 shape 我们用到的最多。
⚠️ 需要注意的是:size 不是 shape,ndim 表示有几个维度。
# 维度,array 是二维的(两个维度)
arr.ndim
2
np.shape
# 形状,返回一个 Tuple
arr.shape
(3, 4)
# 数据量
arr.size
12
最值分位
⭐⭐⭐
这一小节主要包括:最大值、最小值、中位数、其他分位数,其中『最大值和最小值』我们平时用到的最多。
⚠️ 需要注意的是:分位数可以是 0-1 的任意小数(表示对应分位),而且分位数并不一定在原始的 array 中。
arr
array([[0.77395605, 0.43887844, 0.85859792, 0.69736803],
[0.09417735, 0.97562235, 0.7611397 , 0.78606431],
[0.12811363, 0.45038594, 0.37079802, 0.92676499]])
# 所有元素中最大的
arr.max()
0.9756223516367559
np.max/min
# 按维度(列)最大值
arr.max(axis=0)
array([0.77395605, 0.97562235, 0.85859792, 0.92676499])
# 同理,按行
arr.max(axis=1)
array([0.85859792, 0.97562235, 0.92676499])
# 是否保持原来的维度
# 这个需要特别注意下,很多深度学习模型中都需要保持原有的维度进行后续计算
# shape 是 (3,1),array 的 shape 是 (3,4),按行,同时保持了行的维度
arr.min(axis=1, keepdims=True)
array([[0.43887844],
[0.09417735],
[0.12811363]])
# 保持维度:(1,4),原始array是(3,4)
arr.min(axis=0, keepdims=True)
array([[0.09417735, 0.43887844, 0.37079802, 0.69736803]])
# 一维了
arr.min(axis=0, keepdims=False)
array([0.09417735, 0.43887844, 0.37079802, 0.69736803])
# 另一种用法,不过我们一般习惯使用上面的用法,其实两者一回事
np.amax(arr, axis=0)
array([0.77395605, 0.97562235, 0.85859792, 0.92676499])
# 同 amax
np.amin(arr, axis=1)
array([0.43887844, 0.09417735, 0.12811363])
# 中位数
# 其他用法和 max,min 是一样的
np.median(arr)
0.7292538655248584
# 分位数,按列取1/4数
np.quantile(arr, q=0.25, axis=0)
array([0.11114549, 0.44463219, 0.56596886, 0.74171617])
# 分位数,按行取 3/4,同时保持维度
np.quantile(arr, q=0.75, axis=1, keepdims=True)
array([[0.79511652],
[0.83345382],
[0.5694807 ]])
# 分位数,注意,分位数可以是 0-1 之间的任何数字(分位)
# 如果是 1/2 分位,那正好是中位数
np.quantile(arr, q=1/2, axis=1)
array([0.73566204, 0.773602 , 0.41059198])
平均求和标准差
⭐⭐⭐
这一小节主要包括:平均值、累计求和、方差、标准差等进一步的统计指标。其中使用最多的是「平均值」。
arr
array([[0.77395605, 0.43887844, 0.85859792, 0.69736803],
[0.09417735, 0.97562235, 0.7611397 , 0.78606431],
[0.12811363, 0.45038594, 0.37079802, 0.92676499]])
np.average
# 平均值
np.average(arr)
0.6051555606435642
# 按维度平均(列)
np.average(arr, axis=0)
array([0.33208234, 0.62162891, 0.66351188, 0.80339911])
# 另一个计算平均值的 API
# 它与 average 的主要区别是,np.average 可以指定权重,即可以用于计算加权平均
# 一般建议使用 average,忘掉 mean 吧!
np.mean(arr, axis=0)
array([0.33208234, 0.62162891, 0.66351188, 0.80339911])
np.sum
# 求和,不多说了,类似
np.sum(arr, axis=1)
array([2.76880044, 2.61700371, 1.87606258])
np.sum(arr, axis=1, keepdims=True)
array([[2.76880044],
[2.61700371],
[1.87606258]])
# 按列累计求和
np.cumsum(arr, axis=0)
array([[0.77395605, 0.43887844, 0.85859792, 0.69736803],
[0.8681334 , 1.41450079, 1.61973762, 1.48343233],
[0.99624703, 1.86488673, 1.99053565, 2.41019732]])
# 按行累计求和
np.cumsum(arr, axis=1)
array([[0.77395605, 1.21283449, 2.07143241, 2.76880044],
[0.09417735, 1.0697997 , 1.8309394 , 2.61700371],
[0.12811363, 0.57849957, 0.94929759, 1.87606258]])
# 标准差,用法类似
np.std(arr)
0.28783096517727075
# 按列求标准差
np.std(arr, axis=0)
array([0.3127589 , 0.25035525, 0.21076935, 0.09444968])
# 方差
np.var(arr, axis=1)
array([0.02464271, 0.1114405 , 0.0839356 ])
文献和资料








