因为我们需要不断计算输出与实际值的偏差来修改参数(相差越多修改的幅度越大),所以我们需要用误差函数(Error function,也称损失函数,loss function)来衡量训练集所有样本最终预测值与实际值的误差大小。

其中 y^i 为预测结果,yi 为实际结果。
这个表达式衡量的是训练集所有样本最终预测值与实际值的误差大小,仅与输出层的预测类别有关,但这个预测值取决于前面几层中的参数。如果我们不想将狗认为是猫,就需要让这个误差函数达到最小值。
梯度下降算法是其中一种使误差函数最小化的算法,也是 ANN 模型训练中常用的优化算法,大部分深度学习模型都是采用梯度下降算法来进行优化训练。给定一组函数参数,梯度下降从一组初始参数值开始,迭代移向一组使损失函数最小化的参数值。这种迭代最小化是使用微积分实现的,在梯度的负方向上采取渐变更改。使用梯度下降的典型例子是线性回归。随着模型迭代,损失函数逐渐收敛到最小值。
由于梯度表达的是函数在某点变化率最大的方向,通过计算偏导数得到,所以使用梯度下降方式,会极大地加快学习进程。
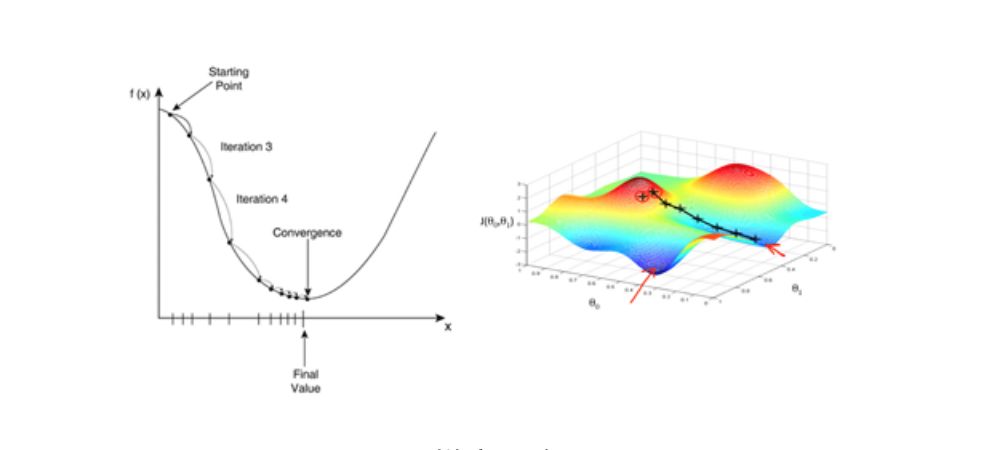
梯度下降
在实际操作中,理论上要先检查最后一层中的权重值和偏移量会如何影响结果。将误差函数 E 求偏导,就能看出权重值和偏移量对误差函数的影响。
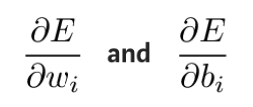
可以通过链式求导法则来计算这些偏导数,得出这些参数变化对输出的影响。求导公式如下:
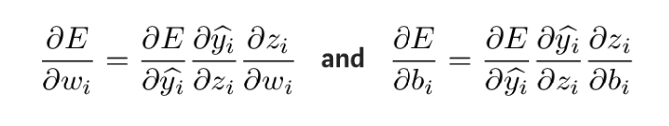
为得到上述表达式中的未知量,将 zi 分别对 wi 和 bi 求偏导:
 然后反向计算误差函数关于每一层权重值和偏移量的偏导数,并通过梯度下降法来更新调整后的权重值和偏移量,直到出错的最初层为止。
然后反向计算误差函数关于每一层权重值和偏移量的偏导数,并通过梯度下降法来更新调整后的权重值和偏移量,直到出错的最初层为止。
这个过程就是反向传播算法,又称 BP 算法,它将输出层的误差反向逐层传播,通过计算偏导数来更新网络参数使得误差函数最小化,从而让 ANN 算法得出符合预期的输出。
目前,反向传播主要应用于有监督学习下的 ANN 算法。







