作者信息:
华校专,曾任阿里巴巴资深算法工程师、智易科技首席算法研究员,现任腾讯高级研究员,《Python 大战机器学习》的作者。
编者按:
算法工程师必备系列更新啦!继上次推出了算法工程师必备的数学基础后,小编继续整理了必要的机器学习知识,全部以干货的内容呈现,哪里不会学哪里,老板再也不用担心你的基础问题!
注意:【深度学习】基础知识--循环神经网络 RNN(上)
四、常见 RNN 变种
4.1 双向 RNN
前面介绍的RNN 网络隐含了一个假设:时刻 t 的状态只能由过去的输入序列 ,以及当前的输入 来决定。
实际应用中,网络输出 可能依赖于整个输入序列。如:语音识别任务中,当前语音对应的单词不仅取决于前面的单词,也取决于后面的单词。因为词与词之间存在语义依赖。
双向 RNN 就是为了解决这种双向依赖问题,它在需要双向信息的应用中非常成功。如:手写识别、语音识别等。
代表通过时间向未来移动的子 RNN的状态,向右传播信息;
代表通过时间向过去移动的子 RNN 的状态,向左传播信息。
t 时刻的输出 同时依赖于过去、未来、以及时刻 t 的输入 。
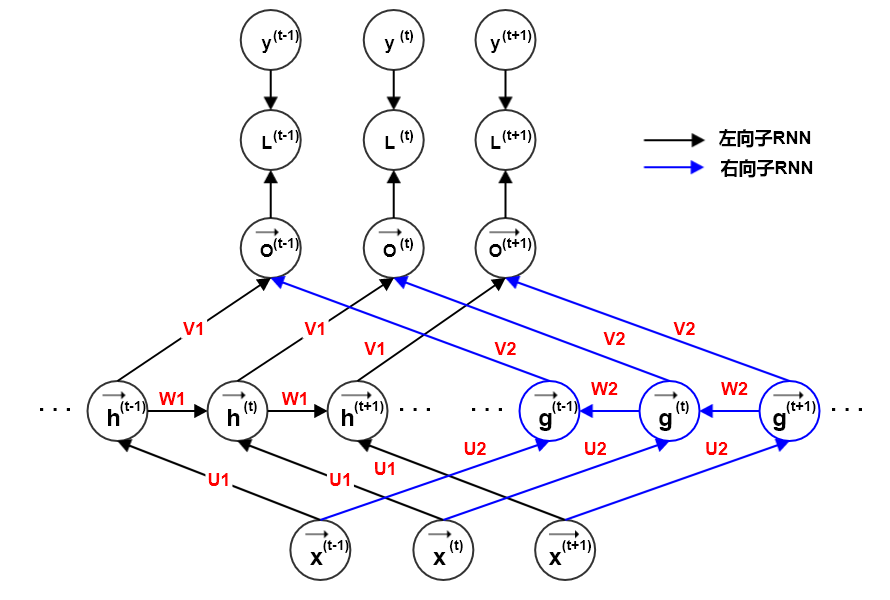
如果输入是 2 维的(如图像),则双向 RNN 可以扩展到4个方向:上、下、左、右。
每个子 RNN 负责一个时间移动方向,t 时刻的输出 同时依赖于四个方向、以及时刻 t 的输入 。
与CNN 相比:
RNN 可以捕捉到大多数局部信息,还可以捕捉到依赖于远处的信息;CNN 只能捕捉到卷积窗所在的局部信息。RNN计算成本通常更高,而CNN
的计算成本较低。
4.2 深度 RNN
前述RNN中的计算都可以分解为三种变换:从输入 到隐状态 的变换、从前一个隐状态 到下一个隐状态 的变换、从隐状态 到输出 的变换。这三个变换都是浅层的,即:由一个仿射变换加一个激活函数组成。
事实上,可以对这三种变换中引入深度。实验表明:引入深度会带来好处。
- 方式二:在这三种变换中,各自使用一个独立的
MLP(可能是较浅的,也可能是较深的)。 - 方式三:在第二种方式的基础上,类似
ResNet 的思想,在 “隐状态-隐状态” 的路径中引入跳跃连接。
通过将RNN的隐状态分为多层来引入深度:如下所示,隐状态有两层:
和 。隐状态层中层次越高,对输入提取的概念越抽象。
在这三种变换中,各自使用一个独立的MLP(可能是深度的),如下图所示。
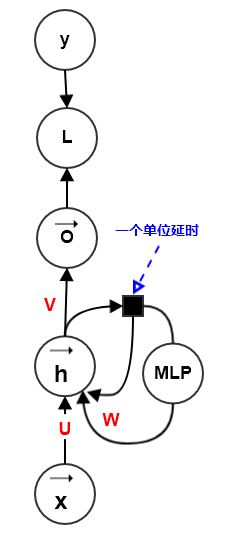
该方法有一个主要问题:额外深度将导致从时间步 t 到时间步 t+1 的最短路径变得更长,这可能导致优化困难而破坏学习效果。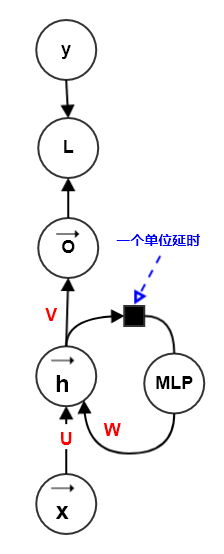
4在第二种方式的基础上,类似ResNet 的思想,在 “隐状态-隐状态” 的路径中引入跳跃连接,从而缓解最短路径变得更长的问题。
由于 中存在常量部分 ,因此 LSTM 可以缓解梯度消失。
由于各种门的存在,因此 中的非常量部分会被缩小,因此可以缓解梯度爆炸。
- 也可以选择使用
cell 状态 作为这些门的额外输入。此时 就多了额外的权重参数,这些参数对应于 的权重和偏置。
4.3.2 GRU
GRU 的单个门控单元同时作为遗忘门和输入门,整个 GRU 模型只有两个门:更新门、复位门。GRU 不再区分cell的状态 和cell 的输出 。
由于 中存在常量部分 ,因此 GRU 可以缓解梯度消失。* 由于各种门的存在,因此 中的非常量部分会被缩小,因此可以缓解梯度爆炸。
4.3.3 讨论
在LSTM 与 GRU 中有两种非线性函数:sigmoid 与 tanh。
sigmoid用于各种门,是因为它的阈值为 0~1,可以很好的模拟开关的关闭程度。
tanh 用于激活函数,是因为它的阈值为 ,它的梯度的阈值为 。
如果使用sigmoid 作为激活函数,则其梯度范围为 ,容易发生梯度消失。
如果使用relu 作为激活函数,则前向传播时,信息容易爆炸性增长。另外relu 激活函数也会使得输出只有大于等于0 的部分。
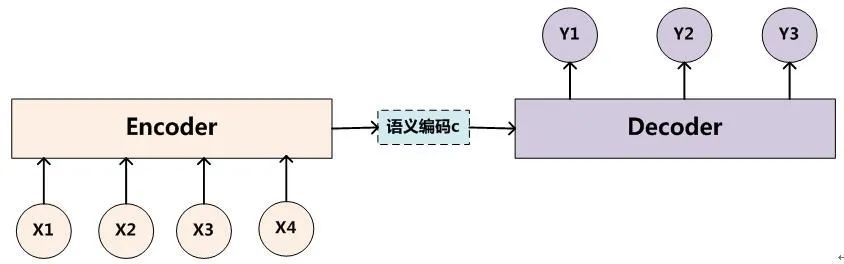
4.4 编码-解码架构
前面介绍的多长度输入序列的模式中,输出序列和输入序列长度相同。实际任务中,如:语音识别、机器翻译、知识问答等任务,输出序列和输入序列长度不相等。编码-解码 架构就是为了解决这类问题。设输入序列为 ,输出序列为 。长度 。设 C 为输入的一个表达representation ,包含了输入序列的有效信息。
它可能是一个向量,也可能是一个固定长度的向量序列。
如果 C 是一个向量序列,则它和输入序列的区别在于:序列C 是定长的、较短的;而输入序列是不定长的、较长的。整个编码-解码 结构分为:编码器,解码器。
编码器(也叫作读取器,或者输入RNN):处理输入序列。编码器的最后一个状态 通常就是输入序列的表达C, 并且作为解码器的输入向量。
解码器(也叫作写入器,或者输出RNN):处理输入的表达C 。解码器有三种处理C 的方式:输入 C 作为每个时间步的输入、输入 C 作为初始状态 且每个时间步没有额外的输入、结合上述两种方式。
- 输入序列长度 \tau_x 和输出序列长度 \tau_y 可以不同。
- 对于编码器与解码器隐状态是否具有相同尺寸并没有限制,它们是相互独立设置的。
编码-解码架构的主要缺点:编码器RNN输出的上下文C的维度太小,难以恰当的概括一个长的输入序列的完整信息。可以通过引入attention机制来缓解该问题。
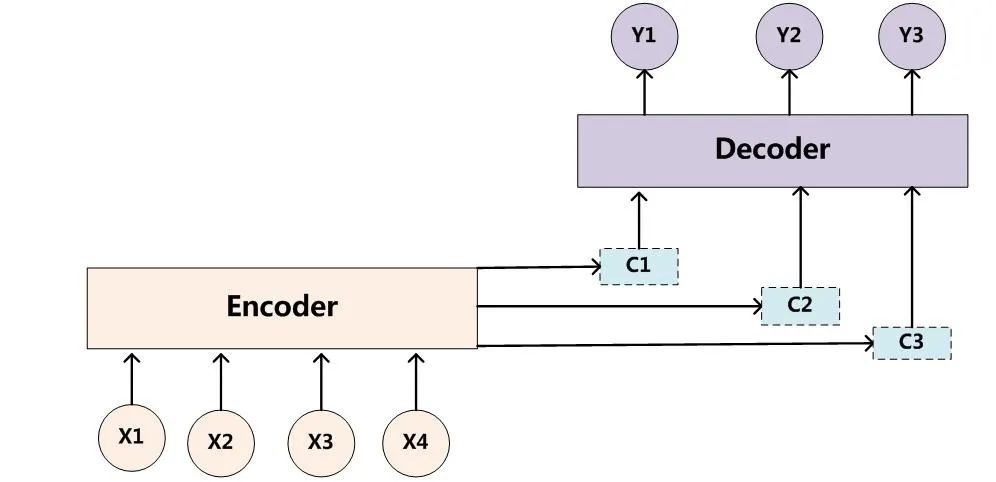
4.5 attention
attention 是一种提升 encoder - decoder 模型效果的机制,一般称作 attention mechanism 。
attention 被广泛用于机器翻译、语音识别、图像标注Image Caption 等领域。如:机器翻译中,为句子中的每个词赋予不同的权重。
attention 本身可以理解为一种对齐关系,给出了模型输入、输出之间的对齐关系,解释了模型到底学到了什么知识。
在机器翻译中,解释了输入序列的不同位置对输出序列的影响程度。如下图所示为机器翻译中,输入-输出的 attention 矩阵。

在图像标注中,解释了图片不同区域对输出文本序列的影响程度。如下图所示为图像标注中,影响输出单词的图像块。

设输入序列为 ,输出序列为 ,长度 。设encoder 的隐向量为 ,decoder 的隐向量为 。
对于传统的 encoder-decoder 模型,decoder 的输入只有一个向量,该向量就是输入序列经过encoder编码的上下文向量 。通常将 encoder 的最后一个隐单元的隐向量
作为上下文向量。
对于 attention encoder-decoder 模型,decoder 的输入是一个向量序列,序列长度为 。decoder位置 i 的输入是采用了 attention 机制的上下文向量 ,不同位置的上下文向量不同。
上下文向量
由 encoder 的所有隐向量加权得到: 。其中 。
4.5.3 Hierarchical attention
在论文《Hierarchical Attention Networks for Document Classification》 中提出了分层 attention 用于文档分类。论文提出了两个层次的 attention:
- 第一个层次是对句子中每个词进行
attention,即 word attention。 - 第二个层次是对文档中每个句子进行
attention,即 sentence attention 。
—— 完 ——

- 机器学习交流qq群955171419,加入微信群请扫码











