大家好,文本数据的处理,对于一个风控策略或者算法,我觉得是必须要掌握的技能,有人说,我的风控并不涉及到文本?我觉得这片面了,在非内容风控领域,文本知识也是非常有用的。
用户昵称、地址啥的,这种绝大部分风控场景都能遇到
关系网络的节点向量化,基本也是文本处理的思路
行为序列,也能用文本的知识去处理,能捕捉非常有趣模式
在这里开个系:20大风控文本分类算法,之前已经写的差不多了,慢慢更新,今天是第一讲。本系列主要介绍了风控场景下文本分类的基本方法,对抗文本变异,包括传统的词袋模型、循环神经网络,也有常用于计算机视觉任务的卷积神经网络,以及 RNN + CNN,试验完一遍,基本能搞定大部分的文本分类以及文本变异对抗问题。算是个保姆级的入门教程。
数据集和预处理
本文用一个风险弹幕数据集做实验,该数据集包含19670条明细数据,每一行都用 1(垃圾文本)和 0(正常文本)进行了标记。需要数据集的关注:小伍哥聊风控,后台回复【弹幕】获取
目标:针对直播间中存在的大量涉黄涉暴弹幕,进行垃圾分类,将弹幕中不合法的内容进行识别并屏蔽。
正常弹幕示例
新人主播,各位老板多多关注ᚠᚠᚠ 0
50077你卖我 0
看看五雷咒的威力 0
垃圾弹幕示例
网站++沜买的私聊我 1
安 KMD555 买-P-微 1
抠逼加薇2928046748抠逼加薇2928046748抠逼。 1

数据读取和查看
import os import pandas as pdpath = '/Users/wuzhengxiang/Documents/DataSets/TextCnn'os.chdir(path)data = pd.read_csv('text_all.csv')
#对数据进行随机打乱data = data.sample(frac=1, random_state=42)print(data.shape)(19670, 2)
#查看0-1的比例,可以看出来,数据集基本上平衡data['label'].value_counts()1 98820 9788
#查看前10行的数据data.head(10)text label17036 郑 29526 Q 77544 15426 葩葩葩l 014173 网站盘需要买的私聊我. 1
14582 买家秀和卖家秀?01730 1776看v 01444 我又没送你谢我干啥ᚠ 010439 7645 55562筘 02448 伽韦 sx111505 珂视频箹 Ku 110423 影薇 w2753636 111782 胸还没有寒磊的 大ᚠ 还奶子疼!0
# 对文本进行分字data['text'] = data['text'].apply(lambda x: ' '.join(x))data.head()

数据读取了,我们就要进行预处理,很多文本分类的预处理,上来就直接去除各种特殊字符,但是在风控中,我们不能这么操作,因为很多文本的信息,都是包含在特殊字符里面,甚至说特殊字符比正常文本的信息含量还要高。这里暂时不做处理,后续再提高模型精度的时候我们再进行处。
将数据集进行分割,80%用于训练,20%用于测试:
from sklearn.model_selection import train_test_split x_train, x_test, y_train, y_test = \ train_test_split(data['text'], data['label'], test_size=0.2, random_state=42 ) print(x_train.shape, x_test.shape, y_train.shape, y_test.shape) (15736,) (3934,) (15736,) (3934,)
字符级的tfidf+逻辑回归
1、什么是N-Gram?
n-gram 是从一个句子中提取的N 个(或更少)连续单词的集合,这一概念中的“单词”,也可以替换为“字符”,这个概念听起来比较抽象,下面来看一个简单的例子,考虑句子“小伍哥最靓”。
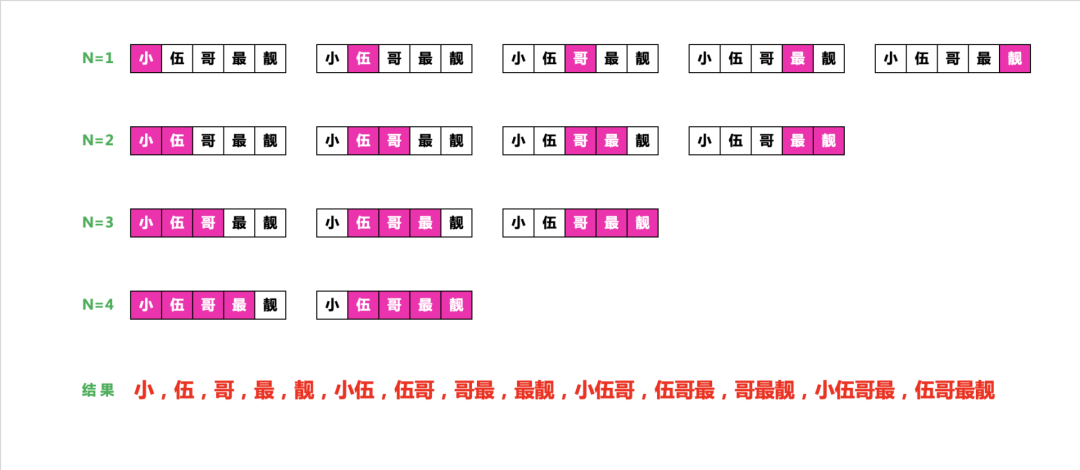
它可以被分解为以下二元语法(2-grams)的集合。
{'小 ; 伍 ; 哥 ; 最 ; 靓 ; 小伍 ; 伍哥 ; 哥最 ; 最靓'}
也可以被分解为以下三元语法(3-grams)的集合。
{小 ; 伍 ; 哥 ; 最 ; 靓 ; 小伍 ; 伍哥 ; 哥最 ; 最靓 ; 小伍哥 ; 伍哥最 ; 哥最靓'}
这样的集合分别叫作二元语法袋(bag-of-2-grams)及三元语法袋(bag-of-3-grams)。这里袋(bag)这一术语指的是,我们处理的是标记组成的集合,而不是一个列表或序列,即标记没有特定的顺序,这一系列分词方法叫作词袋(bag-of-words)。
上面是汉语的文本级的,当然对于英语或者汉语拼音,我们可以做成字符级的,下面以cold这个单词为例,得到如下的词袋组合

那么,什么是 n-gram 呢?我们拿下面👇🏻这句话举例。
2、为什么要用NGram?
能够捕捉顺序关系数据,对于单个文本【小,伍,哥】和【哥,伍,小】是等价的,而N-Gram则是不等价的,而很多场景或者文本,顺序是至关重要。能够捕捉片段信息,每个连续的片段都进行评估,更有利于发现更多可迁移的策略,类似于CNN的平移不变性,或者数TextCNN 的滑窗效果。分字或者分词后进行关联规则挖掘,并不能获得这种比较长的片段信息。
分类模型构建
这里比较关键的参数ngram_range=(1, 5) ,直接就得到了5元的n-gram,,非常强大,token_pattern=r"(?u)\b\w+\b"这个参数解决中文的分词问题,如果不加,默认的得不到一元的词。外国佬写的包,对中文不大友好。
from sklearn.feature_extraction.text import TfidfVectorizer from sklearn.linear_model import LogisticRegression from sklearn.metrics import accuracy_score, auc, roc_auc_score import joblib
vectorizer_word = TfidfVectorizer(
max_features=800000, token_pattern=r"(?u)\b\w+\b", min_df=1, analyzer='word', ngram_range=(1, 5) ) vectorizer_word.fit(x_train) tfidf_train = vectorizer_word.transform(x_train) tfidf_test = vectorizer_word.transform(x_test) len(vectorizer_word.vocabulary_)
逻辑回归模型的训练lr_word = LogisticRegression( solver='sag', verbose=2) lr_word.fit(tfidf_train, y_train) joblib.dump(lr_word, 'lr_word_ngram.pkl')
model = joblib.load(filename="lr_word_ngram.pkl") y_pred_word = lr_word.predict(tfidf_test) print(accuracy_score(y_test, y_pred_word)) 0.9405185561769192
第一个模型就得到了0.9405185561769192的准确率,这个开局还是不错的,可以看到,一个简单的逻辑回归模型,威力还是非常巨大的,为什么能够这么厉害,主要是特征提取的方法,捕获了大量的信息片段,和CNN的扫描逻辑基本一致,但是计算复杂度缺要小很多,因此,逻辑回归+tfidf是文本分类非常好的基模型,有利于快速的上线。
··· END ···
- 机器学习交流qq群955171419,加入微信群请扫码










