MLNLP ( 机器学习算法与自然语言处理 )社区是国内外知名自然语言处理社区,受众覆盖国内外NLP硕博生、高校老师以及企业研究人员。
社区的愿景 是促进国内外自然语言处理,机器学习学术界、产业界和广大爱好者之间的交流,特别是初学者同学们的进步。
来源 | https://www.zhihu.com/question/540433389/answer/2551517886
0、Flip、RandomFlip(随机翻转)
翻转,是最实在的,最基础的数据增广方法,简单,但是最有效。
1、cutout(裁剪)
随机删除图像中的一个矩形区域,可以得到较好的训练结果,其实类似于dropout的操作
2、mixup (混合提升)
mixup的作用是使得对数据的理解更具有线性化,破除由于数据分布不均匀,带来的误差。
3、mosaic(随机马赛克增强)
极大丰富了检测物体的背景,一张顶几张!
还有类似于cutmix,还有很多tricks,还有代码这些就不细致的展开了,大家可以参考一下,以上方法有的是可以组合使用


这里是mmdet武器库中的一些数据增强方法
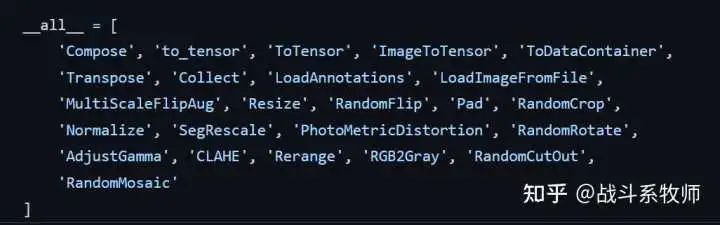
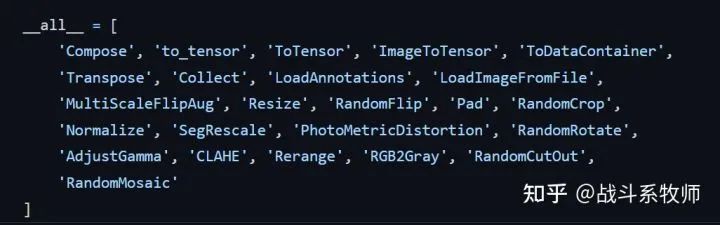
4、Backbone 和 Heads 的不同学习率 (LR)
因为Backbone和Heads在结构上的差异,使用不同的学习率是可以有效的使得网络整理达到更好,更稳定的收敛效果。
5、多loss加权混合
一般会用在分割比较多,常见的有focal loss+Dice loss这类的,主要解决的问题也是类内不平衡叠加上样本数量不平衡等一系列问题。但是要注意的是,loss函数的组合的权重是需要自己去摸索的,目前我还不能找到一种普遍适用的自动化寻参方法,所以我建议大家仔细分析,保证组合后的损失函数下降不平衡导致的损失函数的倾斜化。
6、带权重CEloss,类平衡损失(多类别问题)
对于不同数量的类别,我们会选择对损失函数加权的方法进行处理,让样本数量少的类别也能得到足够的重视。
传送门,如果大家觉得好用,别忘了给个star:https://github.com/open-mmlab/mmsegmentation/blob/master/docs/en/tutorials/training_tricks.md
7、余弦退火算法
经典,有实验结果表明,效果挺好的。
8、SWA
SWA是一种通过随机梯度下降改善深度学习模型泛化能力的方法,而且这种方法不会为训练增加额外的消耗,这种方法可以嵌入到Pytorch中的任何优化器类中。主要还是用于稳定模型的训练。
9、seed(42)
随机种子数42,为啥是42,如同为啥一个星期有7天,而我要上7天班一样,没啥道理,但是就是要这样干。
10、推理过程中的TTA增强
TTA主要在测试时,对于测试数据集进行不同方向的预测后将预测的模型进行组合,在不改变模型内部参数的情况下,对效果进行提升,有点费推理时间,但是好用。
我记得在kaggle上有种方法是叫call back,也就是自己给自己的测试集打个label放进训练,非常不讲武德。我还记得有一次有人用这种方法在一个分类比赛中,别人ACC:94,他们直接干上了98,非常离谱。其实还有个比较常用的一个技巧是多模融合,通常会跑几个模型,然后加在一起融合,在不计算和要求推理时间的条件下。他要模型多大,就做大概多少个模型,你就会发现,你们在单模,我多模,完全就是三个臭皮匠顶一个诸葛亮。大家对于tricks其实可以用,但是论文里面,如果是用tricks,work的话,是不能发的,所以大家多回到模型研究,tricks只是点缀的一些技巧罢了。

扫描二维码添加小助手微信
即可申请加入自然语言处理/Pytorch等技术交流群关于我们
MLNLP社区 ( 机器学习算法与自然语言处理 ) 是由国内外自然语言处理学者联合构建的民间学术社区,目前已经发展为国内外知名自然语言处理社区,旗下包括 万人顶会交流群、AI臻选汇、AI英才汇 以及 AI学术汇 等知名品牌,旨在促进机器学习,自然语言处理学术界、产业界和广大爱好者之间的进步。社区可以为相关从业者的深造、就业及研究等方面提供开放交流平台。欢迎大家关注和加入我们。











