点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达

Mathematically, A convolution is an integration function that expresses the amount of overlap of one function g as it is shifted over another function f. 数学上,卷积是一个积分函数,表示一个函数g在另一个函数f上移位时的重叠量。
Intutively, A convolution acts as a blender that mixes one function with another to give reduced data space while preserving the information. 凭直觉,卷积就像一个搅拌机,将一个函数与另一个函数混合,在保留信息的同时减少数据空间。
In terms of Neural Networks and Deep Learning: 卷积在神经网络和深度学习方面的特征:
卷积是带有可学习参数的过滤器(矩阵/向量),用于从输入数据中提取低维特征;
它们具有保存输入数据点之间的空间或位置关系的属性;
卷积神经网络通过加强相邻层神经元之间的局部连接模式来利用空间-局部相关性;
卷积是在输入上应用滑动窗口(一个有可学习权值的过滤器)的概念,并产生一个加权和(权值和输入)作为输出的步骤。加权和是作为下一层输入的特征空间。
例如,在人脸识别问题中,前几个卷积层学习输入图像中关键点的存在性,下一个卷积层学习边缘和形状,最后一个卷积层学习人脸。在本例中,首先将输入空间降为低维空间(表示点/像素的信息),然后将该空间降为包含(边/形状)的另一个空间,最后降为对图像中的人脸进行分类。卷积可以应用于N维。
接下来就列举在学习工作中常见的种卷积网络结构,尽量图文并茂,多多使用动图;偷偷的告诉你,这是面试必备的内容哦,我们继续往后看,大约需要5min。
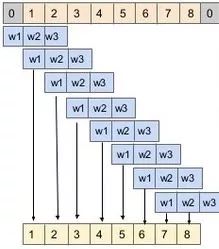
最简单的卷积是一维卷积,通常用于序列数据集(但也可以用于其他用例)。它们可以用于从输入序列中提取局部1D子序列,并在卷积窗口内识别局部模式。下图展示了如何将一维卷积滤波器应用于序列以获得新的特征。1D卷积的其他常见用法出现在NLP领域,其中每个句子都表示为单词序列。
在图像数据集上,CNN架构中使用的大多是二维卷积滤波器。二维卷积的主要思想是通过卷积滤波器向2个方向(x,y)移动,从图像数据中计算出低维特征。输出形状也是一个二维矩阵。
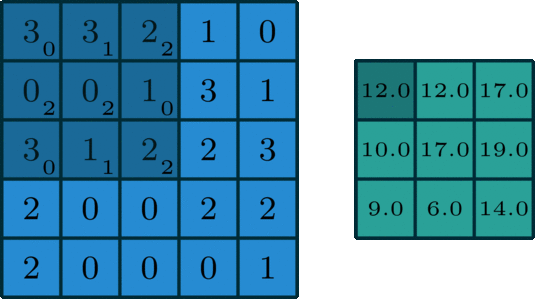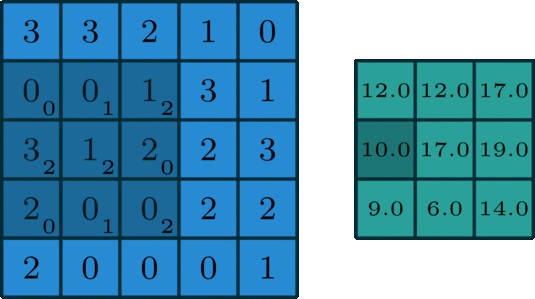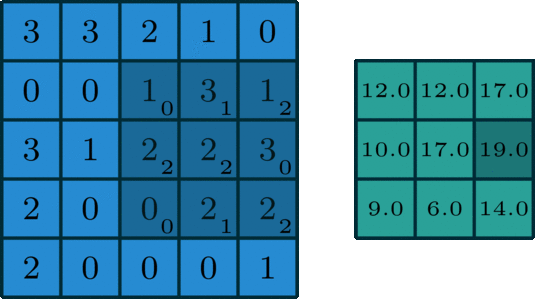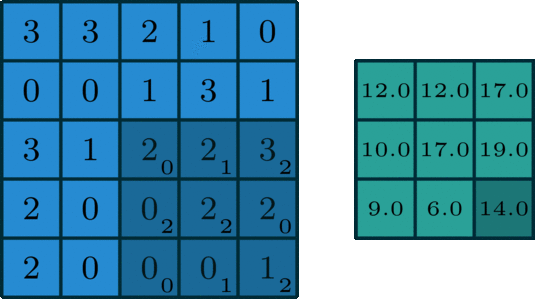
1、单通道卷积
在深度学习中,卷积是元素先乘法后加法。对于具有1个通道的图像,卷积如下图所示。这里的滤波器是一个3x3矩阵,元素为[[0,1,2],[2,2,0],[0,1,2]]。过滤器在输入端滑动。在每个位置,它都在进行元素乘法和加法。每个滑动位置最终都有一个数字。最终输出是3 x 3矩阵。
2、多通道卷积
在许多应用程序中,我们处理的是具有多个通道的图像。典型的例子是RGB图像。每个RGB通道都强调原始图像的不同方面。
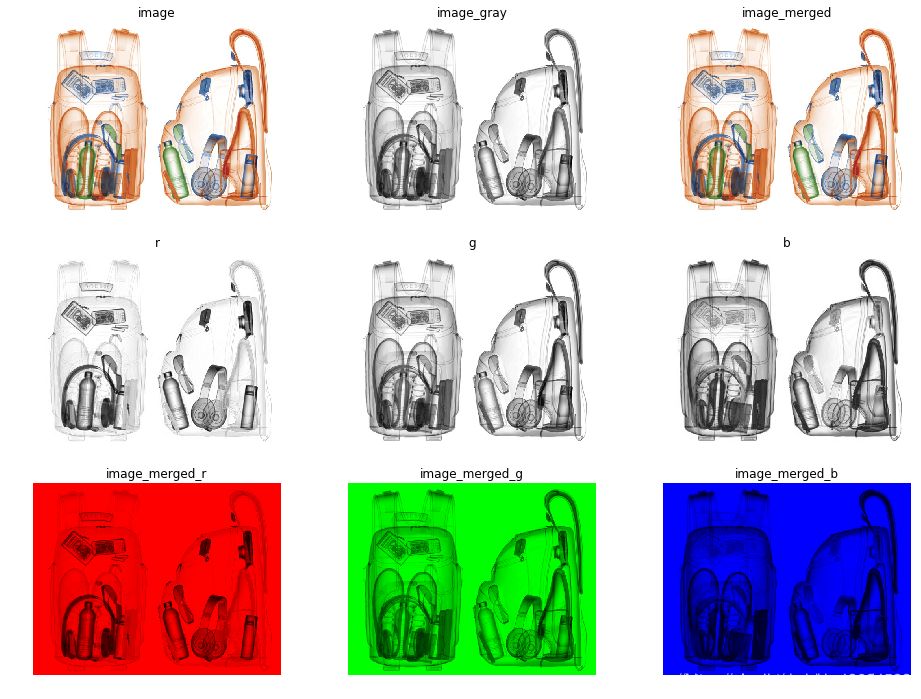
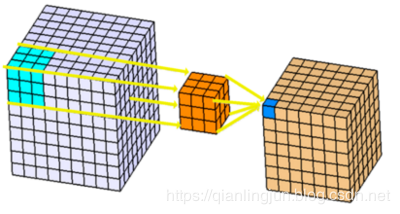
下图使多通道卷积过程更清晰。输入层是一个5 x 5 x 3矩阵,有3个通道。滤波器是3 x 3 x 3矩阵。首先,过滤器中的每个内核分别应用于输入层中的三个通道,并相加;然后,执行三次卷积,产生3个尺寸为3×3的通道。
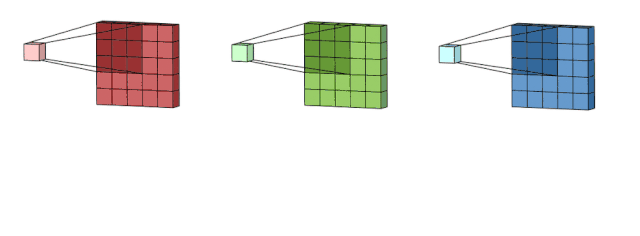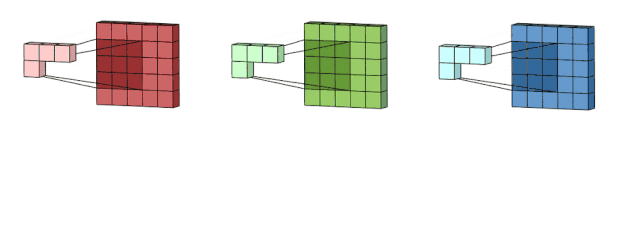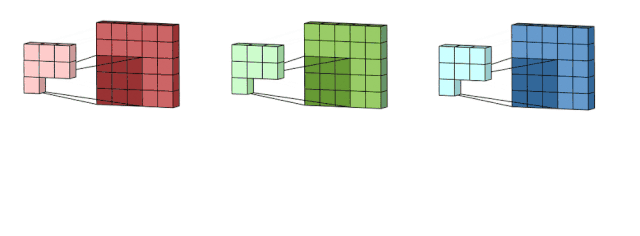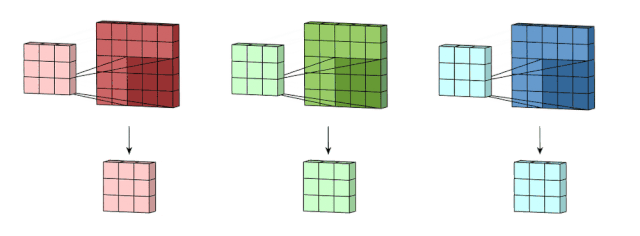
多通道2D卷积的第一步:滤波器中的每个内核分别应用于输入层中的三个通道。
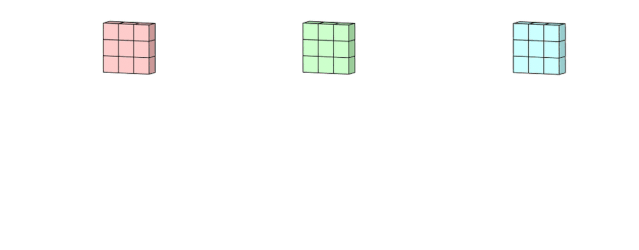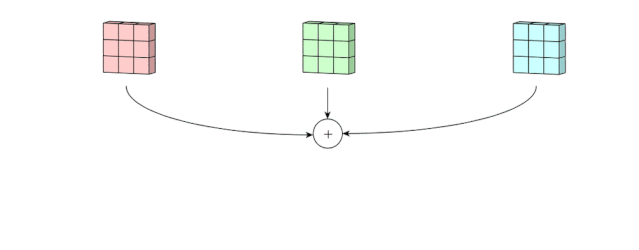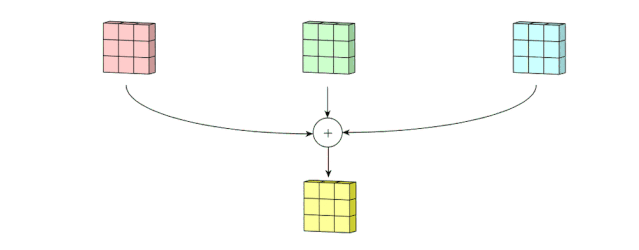
多通道的2D卷积的第二步:然后将这三个通道相加在一起(逐元素加法)以形成一个单通道。
三维卷积对数据集应用三维滤波器,滤波器向3个方向(x, y, z)移动,计算低层特征表示。它们的输出形状是一个三维的体积空间,如立方体或长方体。在视频、三维医学图像等事件检测中有一定的应用价值。它们不仅限于三维空间,还可以应用于二维空间输入,如图像。
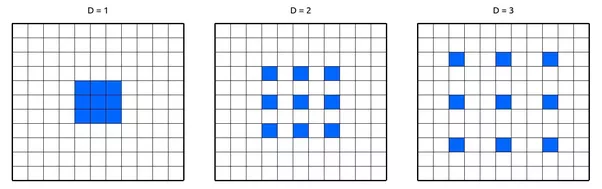
空洞卷积(dilated convolution)
空洞卷积定义内核中值之间的间距。在这种类型的卷积中,由于间距的原因,内核的接受度增加,例如,一个3 * 3的内核,其膨胀率为2,其视野与一个5 * 5的内核相同。复杂性保持不变,但在本例中生成了不同的特性(观察一个大的感受野,而不增加额外的成本)。
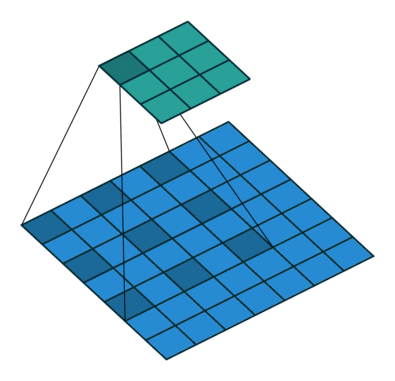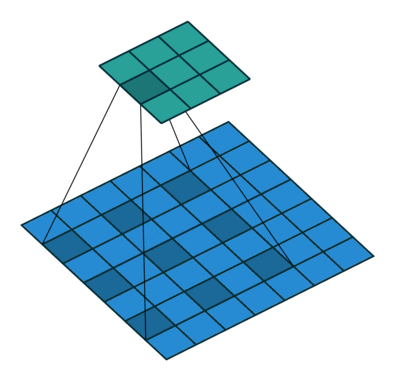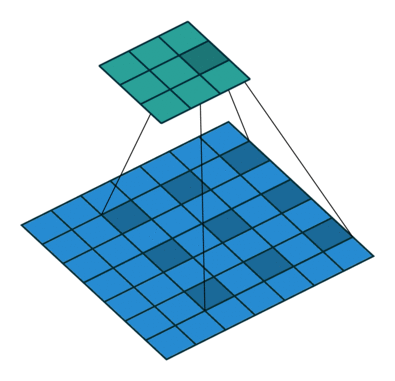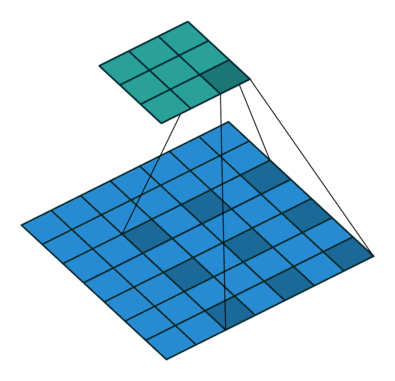
对于许多应用程序和许多网络架构,我们经常希望进行与正常卷积相反方向的转换,即我们希望执行上采样。一些示例包括生成高分辨率图像并将低维特征映射映射到高维空间,例如自动编码器或语义分段。
传统上,可以通过应用插值方案或手动创建规则来实现上采样。然而,神经网络之类的现代架构可以让网络本身自动地学习正确的转换,而无需人为干预。
对于下图中的示例,我们使用3 x 3内核在2 x 2输入上应用转置卷积,使用单位步幅填充2 x 2边框,上采样输出的大小为4 x 4。
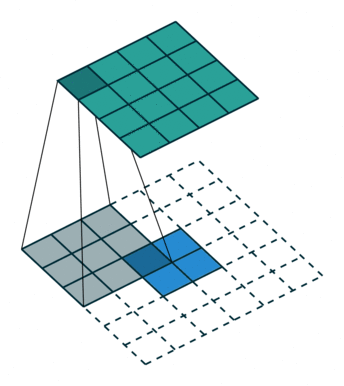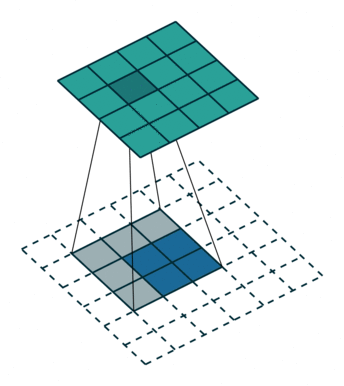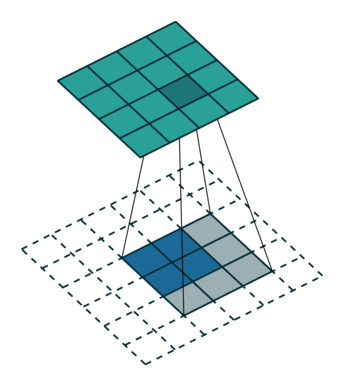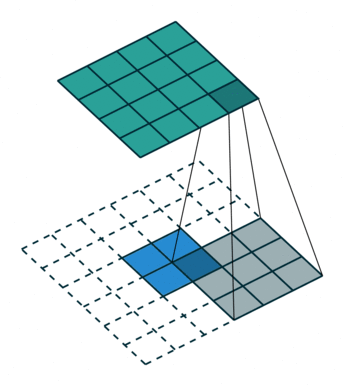
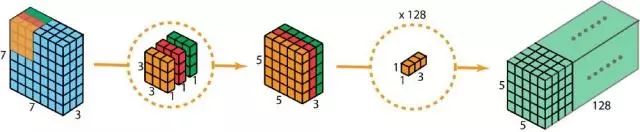
首先,我们将深度卷积应用于输入层。我们不是在2D卷积中使用尺寸为3 x 3 x 3的单个滤波器,而是分别使用3个内核。每个滤波器的大小为3 x 3 x 1.每个内核与输入层的1个通道进行卷积(仅1个通道,而不是所有通道!)。
每个这样的卷积提供尺寸为5×5×1的图。然后我们将这些图堆叠在一起以创建5×5×3图像。在此之后,我们的输出尺寸为5 x 5 x 3.我们现在缩小空间尺寸,但深度仍然与以前相同。
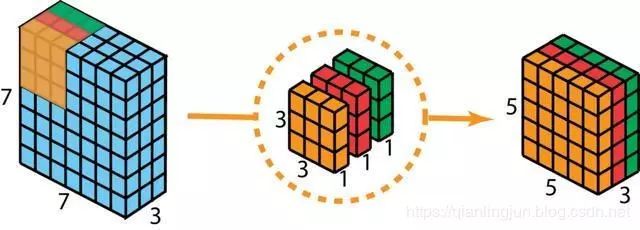
深度可分卷积 - 第一步:我们分别使用3个内核,而不是在2D卷积中使用大小为3 x 3 x 3的单个滤波器。每个滤波器的大小为3 x 3 x 1。每个内核与输入层的1个通道进行卷积(仅1个通道,而不是所有通道)。每个这样的卷积提供尺寸为5×5×1的图。然后我们将这些图堆叠在一起以创建5×5×3图像。在此之后,我们的输出尺寸为5 x 5 x 3。
作为深度可分离卷积的第二步,为了扩展深度,我们应用1x1卷积,内核大小为1x1x3。将5 x 5 x 3输入图像与每个1 x 1 x 3内核进行对比,可提供大小为5 x 5 x 1的映射。
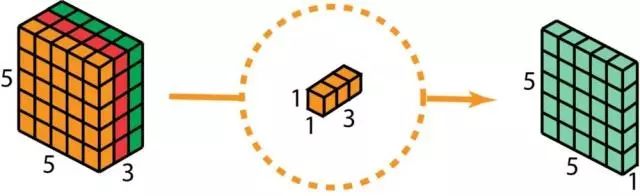
因此,在应用128个1x1卷积后,我们可以得到一个尺寸为5 x 5 x 128的层。
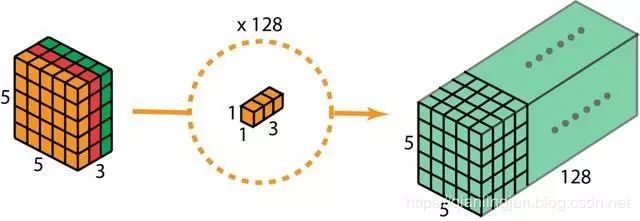
通过这两个步骤,深度可分离卷积还将输入层(7 x 7 x 3)转换为输出层(5 x 5 x 128)。深度可分离卷积的整个过程如下图所示。
那么,深度可分离卷积的优势是什么?效率!与2D卷积相比,对于深度可分离卷积,需要更少的操作。
让我们回顾一下2D卷积示例的计算成本。有128个3x3x3内核移动5x5次。这是128 x 3 x 3 x 3 x 5 x 5 = 86,400次乘法。
可分离的卷积怎么样?在第一个深度卷积步骤中,有3个3x3x1内核移动5x5次。那是3x3x3x1x5x5 = 675次乘法。在1 x 1卷积的第二步中,有128个1x1x3内核移动5x5次。这是128 x 1 x 1 x 3 x 5 x 5 = 9,600次乘法。
因此,总体而言,深度可分离卷积需要675 + 9600 = 10,275次乘法。这只是2D卷积成本的12%左右!
1 x 1卷积中将一个数字乘以输入层中的每个数字。如果输入层有多个通道,此卷积会产生有趣的作用。下图说明了1 x 1卷积如何适用于尺寸为H x W x D的输入层。在滤波器尺寸为1 x 1 x D的1 x 1卷积之后,输出通道的尺寸为H x W x 1.如果我们应用N这样的1 x 1卷积然后将结果连接在一起,我们可以得到一个尺寸为H x W x N的输出层。
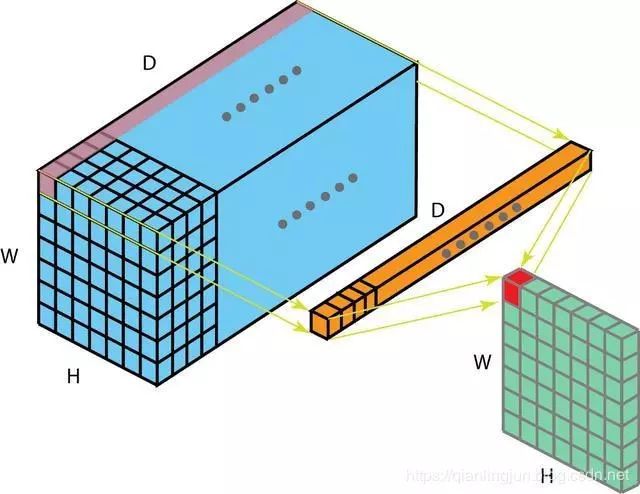
最初,在网络网络文件中提出了1 x 1卷积。然后,他们在Google Inception 被高度使用1 x 1卷积的一些优点是:降低维度以实现高效计算高效的低维嵌入或特征池卷积后再次应用非线性。
在上图中可以观察到前两个优点。在1 x 1卷积之后,我们显着地减小了尺寸。假设原始输入有200个通道,1 x 1卷积会将这些通道(功能)嵌入到单个通道中。第三个优点是在1 x 1卷积之后,可以添加诸如ReLU的非线性激活,非线性允许网络学习更复杂的功能。
2012年,在AlexNet论文中引入了分组卷积。实现它的主要原因是允许通过两个具有有限内存(每个GPU 1.5 GB内存)的GPU进行网络训练。下面的AlexNet在大多数层上显示了两个独立的卷积路径。它正在跨两个GPU进行模型并行化(当然,如果有更多的GPU,可以进行多GPU并行化)。
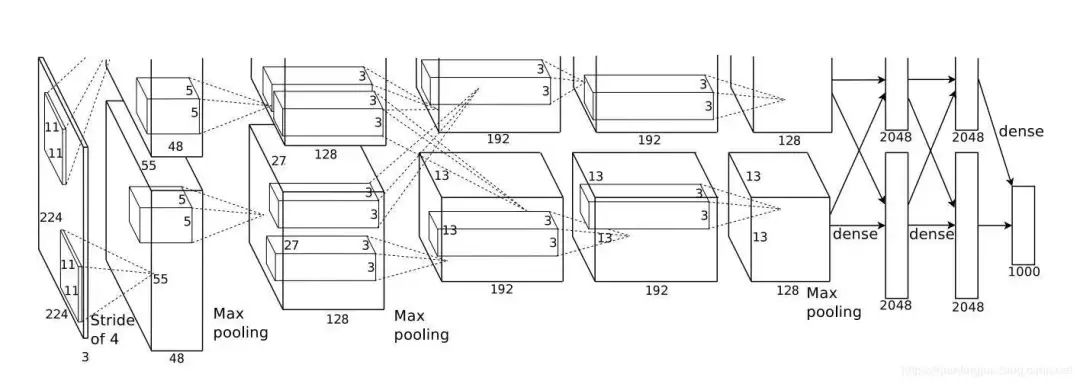
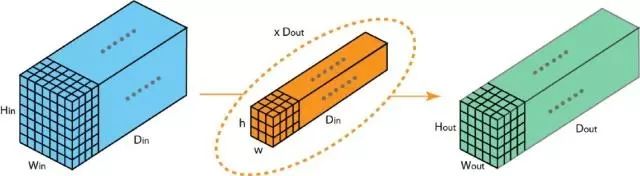
在这里,我们描述分组卷积如何工作。首先,传统的2D卷积遵循以下步骤。在此示例中,通过应用128个滤波器(每个滤波器的大小为3 x 3 x 3),将大小为(7 x 7 x 3)的输入层转换为大小为(5 x 5 x 128)的输出层。
或者在一般情况下,通过应用Dout内核(每个大小为 h x w x Din)将大小(Hin x Win x Din)的输入层变换为大小(Hout x Wout x Dout)的输出层。
在分组卷积中,过滤器被分成不同的组。每组负责具有一定深度的传统2D卷积,如下图。
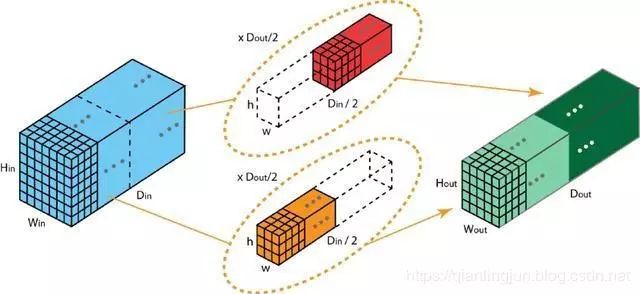
以上是具有2个滤波器组的分组卷积的说明。在每个滤波器组中,每个滤波器的深度仅为标称2D卷积的深度的一半。它们具有深度Din/2。每个滤波器组包含Dout/2滤波器。
第一个滤波器组(红色)与输入层的前半部分([:,:0:Din/2])卷积,而第二个滤波器组(蓝色)与输入层的后半部分卷积([:,:,Din/2:Din])。因此,每个过滤器组都会创建Dout / 2通道。总的来说,两组创建2 x Dout/2 = Dout频道。然后,我们使用Dout通道将这些通道堆叠在输出层中。
PS参考附录:
给大家介绍一个卷积过程的可视化工具,这个项目是github上面的一个开源项目:https://github.com/vdumoulin/conv_arithmetic
https://baijiahao.baidu.com/s?id=1625255860317955368&wfr=spider&for=pc
https://www.kaggle.com/shivamb/3d-convolutions-understanding-use-case/data
下载1:OpenCV-Contrib扩展模块中文版教程
在「小白学视觉」公众号后台回复:
扩展模块中文教程,即可下载全网第一份OpenCV扩展模块教程中文版,涵盖扩展模块安装、SFM算法、立体视觉、目标跟踪、生物视觉、超分辨率处理等二十多章内容。在「小白学视觉」公众号后台回复:Python视觉实战项目,即可下载包括图像分割、口罩检测、车道线检测、车辆计数、添加眼线、车牌识别、字符识别、情绪检测、文本内容提取、面部识别等31个视觉实战项目,助力快速学校计算机视觉。在「小白学视觉」公众号后台回复:OpenCV实战项目20讲,即可下载含有20个基于OpenCV实现20个实战项目,实现OpenCV学习进阶。交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器
、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~










