关注“FightingCV”公众号
回复“AI”即可获得超100G人工智能的教程
问题链接:https://www.zhihu.com/question/451498156
作者:桔了个仔
来源链接:https://www.zhihu.com/question/451498156/answer/1802577845
对于解释性有要求的领域,基本深度学习是没法和传统方法比的。我这几年都在做风控/反洗钱的产品,但监管要求我们的决策要可解释性,而我们曾经尝试深度学习,解释性很难搞,而且,效果也不咋地。对于风控场景,数据清洗是非常重要的事,否则只会是garbage in garge out。
在写上面内容时,我想起前两年看的一篇文章:《你不需要ML/AI,你需要SQL》https://news.ycombinator.com/item?id=17433752作者是尼日利亚的软件工程师Celestine Omin,在尼日利亚最大的电商网站之一Konga工作。我们都知道,对老用户精准营销和个性化推荐,都是AI最为常用的领域之一。当别人在用深度学习搞推荐时,他的方法显得异常简单。他只是跑了一遍数据库,筛选出所有3个月没有登录过的用户,给他们推优惠券。还跑了一遍用户购物车的商品清单,根据这些热门商品,决定推荐什么相关联的商品。结果,他这种简单的而基于SQL的个性化推荐,大多数营销邮件的打开率在7-10%之间,做得好时打开率接近25-30%,是行业平均打开率的三倍。当然,这个例子并不是告诉大家,推荐算法没用,大家都应该用SQL,而是说,深度学习应用时,需要考虑成本,应用场景等制约因素。我在之前的回答里(算法工程师的落地能力具体指的是什么?),说到过算法落地时需要考虑实际制约因素。
https://news.ycombinator.com/item?id=17433752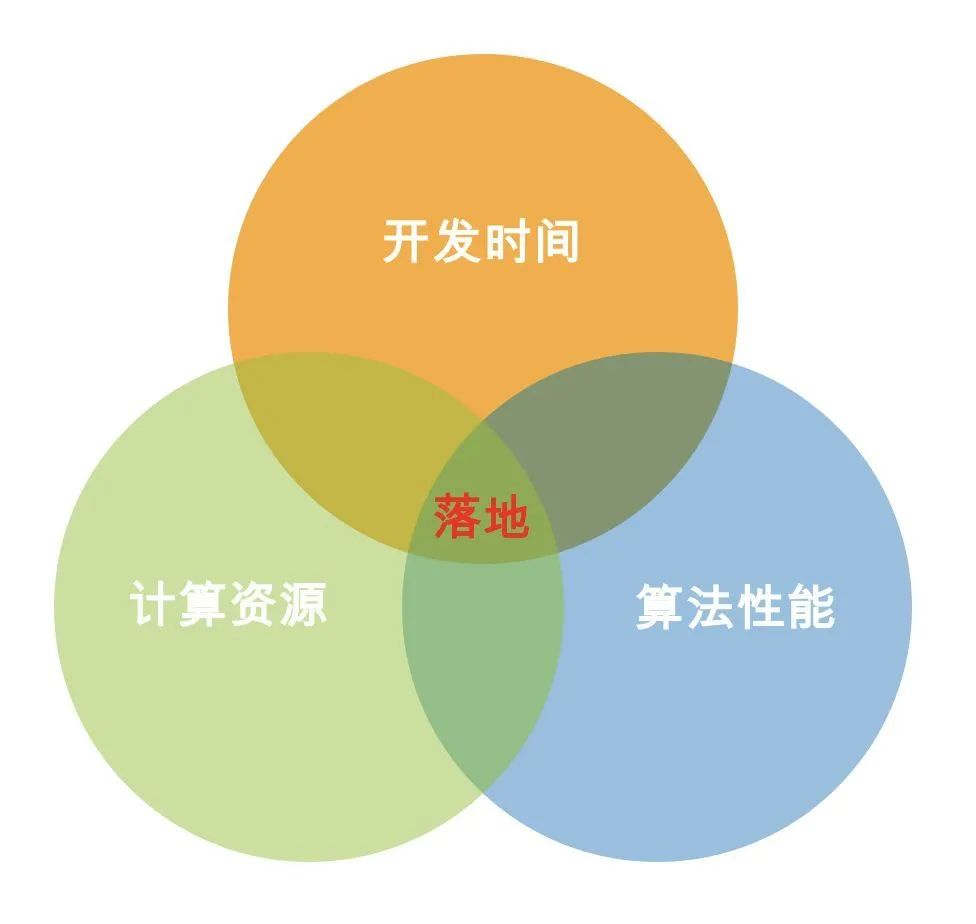 而尼日利亚的电商环境,依然出于非常落后的状态,物流也跟不上。即使使用深度学习方法,提升了效果,实际对公司整体利润并不会有太大影响。所以,算法落地时必须「因地制宜」否则,又会出现「电风扇吹香皂盒」的情况。某大企业引进了一条香皂包装生产线,结果发现这条生产线有个缺陷:常常会有盒子里没装入香皂。总不能把空盒子卖给顾客啊,他们只得请了一个学自动化的博士后设计一个方案来分拣空的香皂盒。
而尼日利亚的电商环境,依然出于非常落后的状态,物流也跟不上。即使使用深度学习方法,提升了效果,实际对公司整体利润并不会有太大影响。所以,算法落地时必须「因地制宜」否则,又会出现「电风扇吹香皂盒」的情况。某大企业引进了一条香皂包装生产线,结果发现这条生产线有个缺陷:常常会有盒子里没装入香皂。总不能把空盒子卖给顾客啊,他们只得请了一个学自动化的博士后设计一个方案来分拣空的香皂盒。
博士后拉起了一个十几人的科研攻关小组,综合采用了机械、微电子、自动化、X射线探测等技术,花了90万,成功解决了问题。每当生产线上有空香皂盒通过,两旁的探测器会检测到,并且驱动一只机械手把空皂盒推走。
中国南方有个乡镇企业也买了同样的生产线,老板发现这个问题后大为发火,找了个小工来说“你他妈给老子把这个搞定,不然你给老子爬走。”小工很快想出了办法他花了190块钱在生产线旁边放了一台大功率电风扇猛吹,于是空皂盒都被吹走了。
作者:莫笑傅立叶
来源链接:https://www.zhihu.com/question/451498156/answer/1802730183
深度学习非常善于解决分类和回归问题,但对于什么影响了结果的解释很弱,如果实际业务场景中,对于解释性要求很高,诸如以下场景,那么深度学习往往被干翻。 诸如调度,规划,分配问题,往往这类问题无法很好的转化为监督学习格式,因此常采用优化算法。在现在研究中,在求解过程中往往融合深度学习算法更好地求解,但总体而言,模型本身还不是深度学习为主干。深度学习是一个非常好的求解思路,但不是唯一,甚至在落地时依旧问题很大。若将深度学习融合于优化算法,作为求解的一个部件,依旧有很大的用武之地。
诸如调度,规划,分配问题,往往这类问题无法很好的转化为监督学习格式,因此常采用优化算法。在现在研究中,在求解过程中往往融合深度学习算法更好地求解,但总体而言,模型本身还不是深度学习为主干。深度学习是一个非常好的求解思路,但不是唯一,甚至在落地时依旧问题很大。若将深度学习融合于优化算法,作为求解的一个部件,依旧有很大的用武之地。
作者:LinT
来源链接:https://www.zhihu.com/question/451498156/answer/1802516688
这个问题要分场景看。深度学习固然免去了特征工程的麻烦,但是在一些场景下应该很难应用:应用对时延有高要求,而对精度没有那么高的要求,这时简单的模型可能是更好的选择;
一些数据类型,例如tabular数据,可能更适合使用基于树的模型等统计学习模型而不是深度学习模型;
模型决策有重大影响,例如安全相关、经济决策相关,要求模型具有可解释性,那么线性模型或者基于树的模型,相对深度学习是更好的选择;
应用场景决定了数据采集难,使用深度学习有过拟合的风险。
真实的应用都是从需求出发的,抛开需求(精度、时延、算力消耗)谈表现是不科学的。如果把问题中的『干翻』限定到某个指标上,可能讨论范围可以缩小一些。往期回顾
基础知识
【CV知识点汇总与解析】|损失函数篇
【CV知识点汇总与解析】|激活函数篇
【CV知识点汇总与解析】| optimizer和学习率篇
【CV知识点汇总与解析】| 正则化篇
【CV知识点汇总与解析】| 参数初始化篇
【CV知识点汇总与解析】| 卷积和池化篇 (超多图警告)
最新论文解析
NeurIPS 2022 | VideoMAE:南大&腾讯联合提出第一个视频版MAE框架,遮盖率达到90%
NeurIPS 2022 | 清华大学提出OrdinalCLIP,基于序数提示学习的语言引导有序回归
SlowFast Network:用于计算机视觉视频理解的双模CNN
WACV2022 | 一张图片只值五句话吗?UAB提出图像-文本匹配语义的新视角!
CVPR2022 | Attention机制是为了找最相关的item?中科大团队反其道而行之!
ECCV2022 Oral | SeqTR:一个简单而通用的 Visual Grounding网络
如何训练用于图像检索的Vision Transformer?Facebook研究员解决了这个问题!
ICLR22 Workshop | 用两个模型解决一个任务,意大利学者提出维基百科上的高效检索模型
See Finer, See More!腾讯&上交提出IVT,越看越精细,进行精细全面的跨模态对比!
MM2022|兼具低级和高级表征,百度提出利用显式高级语义增强视频文本检索
MM2022 | 用StyleGAN进行数据增强,真的太好用了
MM2022 | 在特征空间中的多模态数据增强方法
ECCV2022|港中文MM Lab证明Frozen的CLIP 模型是高效视频学习者
ECCV2022|只能11%的参数就能优于Swin,微软提出快速预训练蒸馏方法TinyViT
CVPR2022|比VinVL快一万倍!人大提出交互协同的双流视觉语言预训练模型COTS,又快又好!
CVPR2022 Oral|通过多尺度token聚合分流自注意力,代码已开源
CVPR Oral | 谷歌&斯坦福(李飞飞组)提出TIRG,用组合的文本和图像来进行图像检索








