模型解释是有监督机器学习中的一项重要任务。解释模型对于理解支配数据的动态至关重要。让我们看看一些易于解释的模型。
为什么我们需要解释我们的模型?
数据科学家的角色是从原始数据中提取信息。他们不是工程师,也不是软件开发人员。他们挖掘内部数据,从矿井中提取黄金。
了解模型的作用和工作原理是这项工作的一部分。黑箱模型虽然有时比其他模型工作得更好,但如果我们需要从数据中学习一些东西,那就不是一个好主意。相反,一些模型,就其本质而言,很好地解释了它们如何将数据转换为信息,始终受到青睐和深入研究。
机器学习模型是一种将信息翻译成合适且可理解的语言的方法,即数学。如果我们能把一些东西转化为数学,我们就能从中学到更多,因为我们可以掌握我们所需要的数学。因此,模型不仅仅是我们可以用来预测客户是否会买东西的算法。这是一种理解“为什么”一个拥有特定个人资料的客户可能会购买某些东西,而另一个拥有不同个人资料的用户则不会购买任何东西的方法。
因此,模型解释对于为我们正在寻找的信息提供正确的形状至关重要。
通过特征重要性进行解释
解释模型如何“思考”我们的数据以提取信息的一种可能方式是查看特征的重要性。重要性通常为正数。该数字越高,模型对该特定特征的重要性就越高。
在本文中,我将展示一些模型,这些模型使用Python和scikit-learn库为我们提供了自己的特征重要性解释。让我们永远记住,不同的模型对特征的重要性不同。这是完全正常的,因为每一个模型如何看待信息的方式不一样。我们从来没有完整的视图,因此特征的重要性在很大程度上取决于我们选择的模型。
让我们首先导入一些库和scikit-learn的“葡萄酒”数据集。
import numpy as np
from sklearn.datasets
import load_wine,load_diabetes
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier,GradientBoostingClassifier
from sklearn.linear_model import *
from sklearn.svm import LinearSVC,LinearSVR
import xgboost as xgb
import matplotlib.pyplot as plt
from sklearn.pipeline import make_pipeline
from sklearn.preprocessing import StandardScaler
现在让我们加载数据集并存储特征的名称。
X,y = load_wine(return_X_y=True)
features = load_wine()['feature_names']
现在,我们准备计算不同类型模型的特征重要性。
决策树
基于树的模型根据其在整个树上提供的叶子纯度的总体改善来计算特征的重要性。如果一个特征能够正确地分割数据集并提高特征的纯度,那么这是非常重要的。为了简单起见,基于树的模型中的重要性得分被归一化,使其总和为1。
在scikit-learn中,每个基于决策树的模型都有一个名为feature_importances_的属性,其中包含了特征的重要性。它可以在拟合我们的模型后访问。
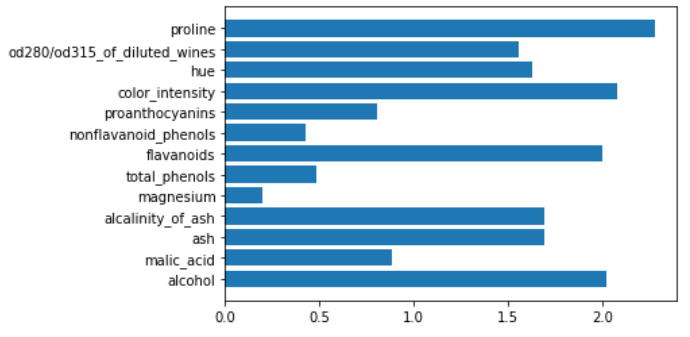
让我们看看一个简单的决策树模型会发生什么。
tree = DecisionTreeClassifier()
tree.fit(X,y)
plt.barh(features,tree.feature_importances_)
正如我们所看到的,一些特征的重要性等于0。
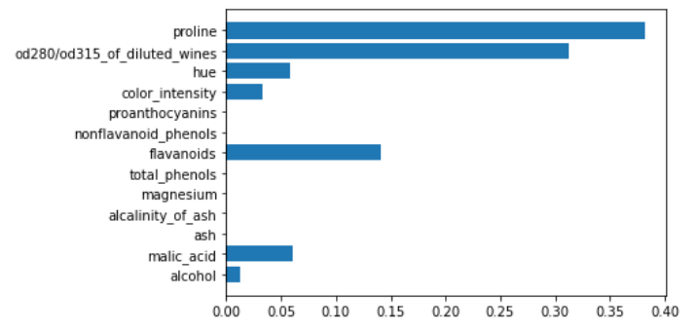
基于树的一个非常重要的模型是随机森林,它对特征的重要性非常有用。一般来说,集成模型对每个弱学习者给出的每个特征的重要性得分进行平均,然后像决策树一样对最终得分进行归一化。
下面是如何计算随机森林模型的特征重要性。
rf = RandomForestClassifier()
rf.fit(X,y)
plt.barh(features,rf.feature_importances_)
例如,由随机森林给出的特征重要性可用于执行特征选择。
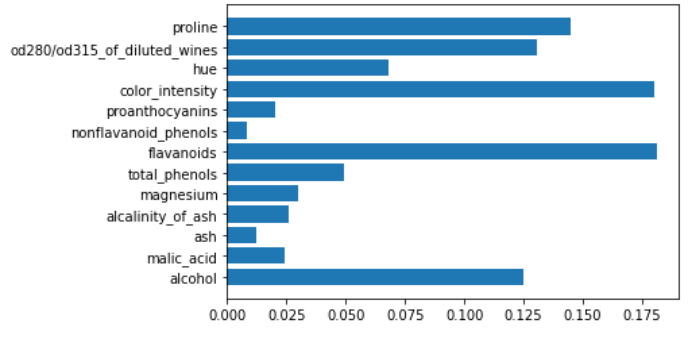
即使是梯度增强决策树模型也可以给我们自己的特征重要性解释。
gb = GradientBoostingClassifier()
gb.fit(X,y)
plt.barh(features,gb.feature_importances_)
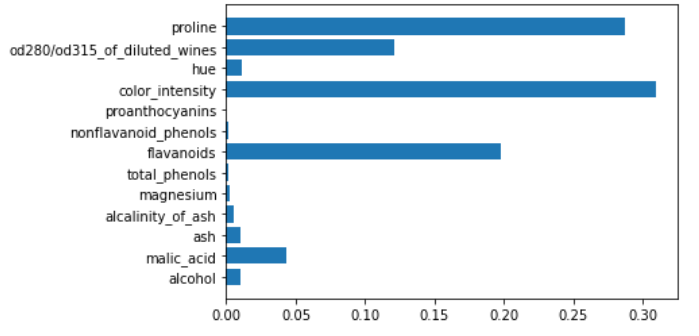
即使对于XGBoost也是如此。
xgboost = xgb.XGBClassifier()
xgboost.fit(X,y)
plt.barh(features,xgboost.feature_importances_)
线性模型
线性模型也能给我们特征的重要性。实际上,它是特征系数的绝对值。如果我们使用多类线性模型进行分类,我们将对与单个特征相关的系数的绝对值求和。
在计算特征重要性时,所有线性模型都需要标准化或标准化的特征。一些模型默认情况下需要这种变换,但如果我们想相互比较系数,我们总是必须应用它。这就是为什么我将在训练模型之前使用scikit-learn中的管道对象来标准化我们的数据。
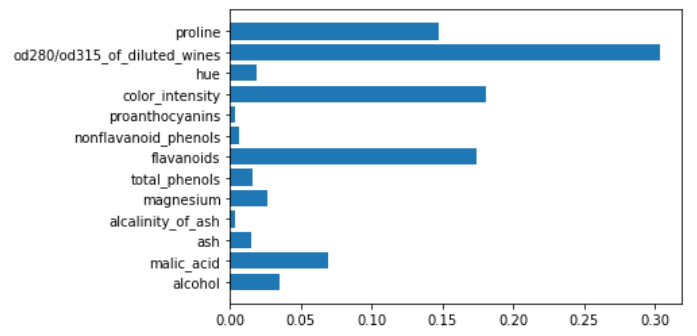
让我们看一个带有线性核的支持向量机的例子。
svm = make_pipeline(StandardScaler(),LinearSVC())
svm.fit(X,y)
plt.barh(features,np.abs(svm[1].coef_).sum(axis=0))
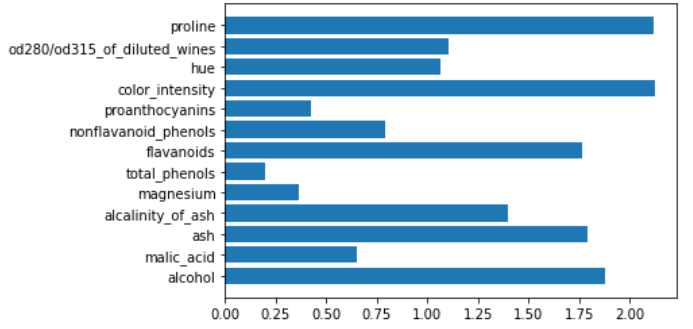
这同样适用于逻辑回归。
logit = make_pipeline(StandardScaler(),LogisticRegression())
logit.fit(X,y)
plt.barh(features,np.abs(logit[1].coef_).sum(axis=0))
可用于特征重要性的其他线性模型是回归模型,因此我们必须加载回归数据集以查看它们的工作方式。对于以下示例,我将使用“糖尿病”数据集。
X,y = load_diabetes(return_X_y=True)
features = load_diabetes()['feature_names']
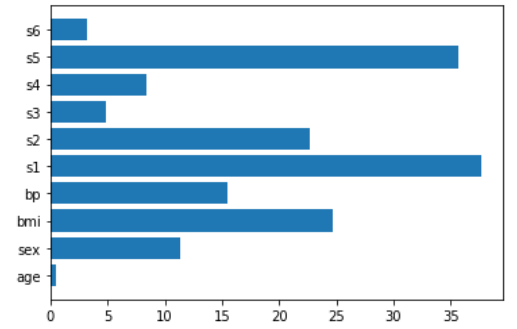
让我们看看线性回归如何计算特征重要性。
lr = make_pipeline(StandardScaler(),LinearRegression())
lr.fit(X,y)
plt.barh(features,np.abs(lr[1].coef_))
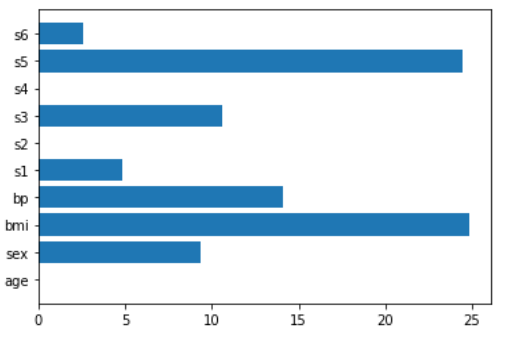
LASSO回归是一个非常强大的模型,可以用于特征重要性(以及特征选择)
lasso = make_pipeline(StandardScaler(),Lasso())
lasso.fit(X,y)
plt.barh(features,np.abs(lasso[1].coef_))
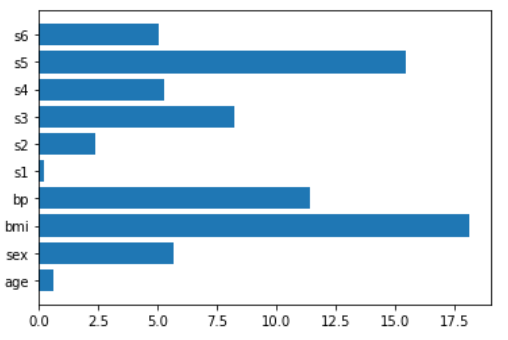
LASSO回归最亲密的朋友是岭回归,这也很有帮助。
ridge = make_pipeline(StandardScaler(),Ridge())
ridge.fit(X,y)
plt.barh(features,np.abs(ridge[1].coef_))
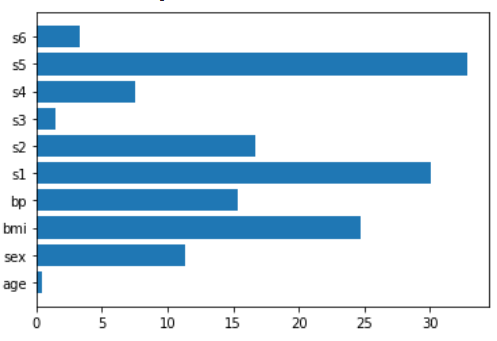
我们将看到的最后一个模型将LASSO回归和岭回归混合在一起,这就是Elastic Net回归。
en = make_pipeline(StandardScaler(),ElasticNet())
en.fit(X,y)
plt.barh(features,np.abs(en[1].coef_))
结论
模型解释通常是通过计算特征的重要性来完成的,一些模型给出了对特征重要性的解释。对于那些不能给出特征重要性的模型,我们可以使用一些与模型无关的方法,如SHAP(例如,对于解释神经网络非常有用)。正确使用特征重要性可以比模型本身的预测能力更好地提高数据科学项目的价值。
感谢阅读!
- 机器学习交流qq群955171419,加入微信群请扫码











