作者 | 李梅
编辑 | 陈彩娴
机器学习领域的研究进展迅速,研究者既要及时跟进最新研究,也要不时地回顾经典。寒假开始,各位机器学习er在度假之余,想必也不会忘了自己卷王的身份。
最近,Github上出现了一个名为“ML Papers Explained”的优质项目,精选了机器学习领域的一些核心概念,对相关工作的原始论文做了解读,实在是广大MLer的一大福利。
项目地址:https://github.com/dair-ai/ML-Papers-Explained
该项目由三位数据 Rastogi、Diego Marinho、Elvis Saravia创建,旨在介绍机器学习领域重点技术的研究论文,既有经典重现,也有最新前沿跟进,突出论文的主要创新点,讨论它们对研究领域的影响及其应用空间。
该项目目前集合了25个机器学习概念,涉及计算机视觉、目标检测、文档信息处理、自然语言处理等方向。按类别划分,包括RCNN系列:

Transformer系列(Layout Transformers、Document Information Processing、Vision Transformers):
以及Single Stage Object Detectors系列:

点击这些关键词,就是一篇论文详解,这些论文解读大都不是长篇累牍,而是简明扼要地介绍论文的核心发现、实验结果,同时有进一步的延伸思考。文章的排版也清晰明了,能够帮助研究者快速且深入理解一篇论文的精髓。这里选取两篇解读来一睹为快。
TinyBERT解读
在大模型越来越成为AI核心研究方向的当下,回顾这些经典的语言模型论文是大有裨益的。比如自BERT模型出现以后,提高模型参数量的同时降低大模型的计算成本,就一直是该领域的一个热点方向。
Github上的这个论文解读项目就精选了多篇相关论文,以一篇对知识蒸馏方法TinyBERT的解读为例:

这项工作由年华中科技大学和华为诺亚方舟实验室合作,在2019年提出。这篇解读概括了TinyBERT这项工作的三个核心贡献:Transformer蒸馏、两步蒸馏过程、数据增强,这些方法改进了基于Transformer的模型在特定情况下的知识蒸馏效果。
首先是Transformer蒸馏。这部分介绍了论文所用蒸馏方法的核心思想和公式,并解释了先前的蒸馏工作DistillBERT的弊端,如它使用教师模型来初始化学生模型的权重,导致两者必须有相同的内部尺寸并允许层数不同,而TinyBERT通过在嵌入和隐藏损失函数中引入可学习的投影矩阵来规避这个问题,从而使得学生和教师模型的内部表示在元素方面可以进行比较。

另外,解读作者还在这里引用了另一项相关研究,为TinyBERT的进一步工作提出了一个有趣的方向。

然后是两步蒸馏法。这里说明了TinyBERT所使用的蒸馏过程遵循了原始BERT的训练方法——在大规模的通用数据集上进行预训练以获得语言特征,然后针对特定任务数据进行微调。所以在第一个步骤中,使用在通用数据上训练的通用BERT作为教师,学生学习模仿教师的嵌入和转换层激活来创建一个通用的TinyBERT;在第二个步骤中,将教师模型切换到特定任务模型并继续训练学生模型。

第三个是数据增强。这部分介绍了论文作者使用了数据增强技术来在微调步骤中对特定任务的数据集进行扩展。

之后文章精简地呈现了原始论文中TInyBERT的关键数据,如该模型的性能在基准测试中达到了BERT基础教师模型的96%,同时体积缩小了7.5倍,速度提高了9.4倍。

针对原始论文的三个核心贡献,文章还给出了一些有价值的思考,如特定任务的蒸馏(微调)比通用蒸馏(预训练)更重要等等。

Swin Transformer解读
再比如当年屠榜各大视觉任务的Swin Transformer,由微软亚洲研究院郭百宁团队提出,是视觉领域的研究者必读的一篇论文,这项工作也在这个论文解读项目有精彩的分享:

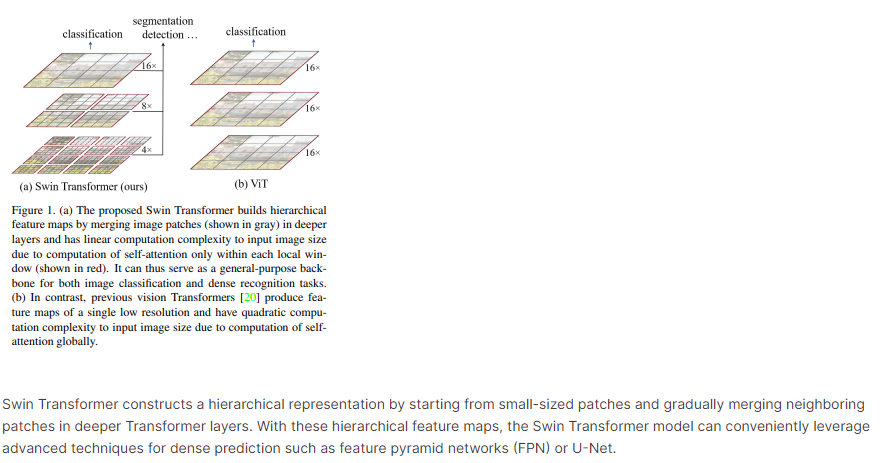
文章首先以原始论文中的关键图表,简要介绍了Swin Transformer的基本方法及其核心设计元素。
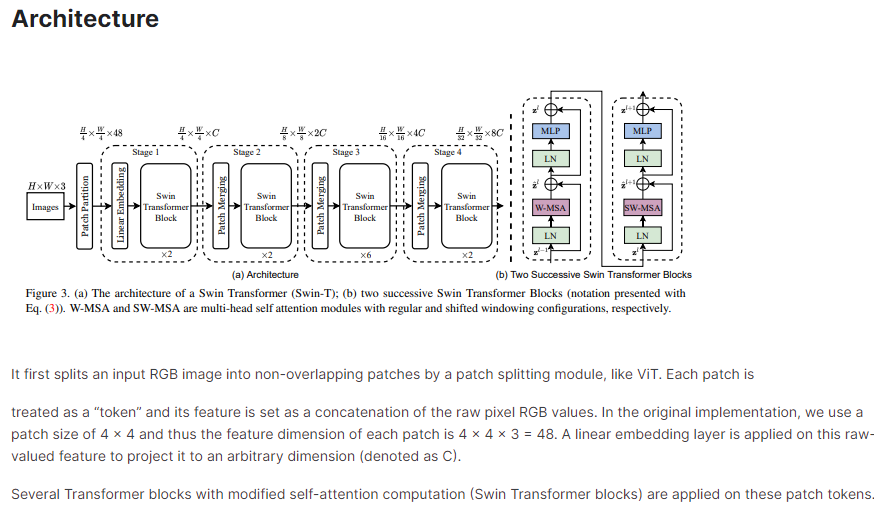
然后逻辑清晰地详解了Swin Transformer的架构细节,包括4个stage和Swin Transformer Block
接着列出了Swin Transformer的几项实验:

有兴趣的读者可以自行前往该项目探索一番,如果想分享自己的论文解读,也可以向该项目提交PR。据项目作者透露,后续还将推出notebook和讲座,帮助大家更好地跟进研究进展。
更多内容
,点击下方关注:

未经「AI科技评论」授权,严禁以任何方式在网页、论坛、社区进行转载!
公众号转载请先在「AI科技评论」后台留言取得授权,转载时需标注来源并插入本公众号名片。






