
今天分享的论文为《CL4CTR: A Contrastive Learning Framework for CTR Prediction》,从特征表示角度入手,将多种对比学习损失引入到CTR预估的模型训练中,一起来看一下。
1、背景
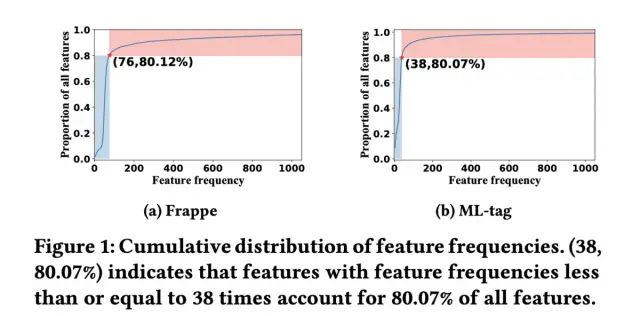
主流的CTR预估模型大致可以分为两类,一类是传统的模型,如逻辑回归,FM,FFM等,这些模型仅可以建模低阶的特征交互,另一类是基于深度学习的模型,如DeepFM、wide&Deep等,这些模型可以建模高阶的特征交互来提升模型的预估效果。对于深度学习类的CTR预估模型,大都基于三层的设计范式:Embedding层、特征交互(FI)层和预估层。在这种设计范式下,绝大多数的工作针对特征交互层展开,如xDeepFM、DCN等,对于Embedding层的研究却很少。但在实际训练过程中,大多数CTR模型面临的一个问题是:出现频率高的特征对应的Embedding会被充分学习,出现次数低的特征对应的Embedding无法被充分学习,进一步导致模型的表现是次优的。如在Frappe和ML-tag数据集中,可以看到明显的“长尾”现象,如下图所示:
当然也有一些工作从特征表示的角度入手进行优化,在模型中引入了特征重要度模块来增强其表示(如FEN,Duel-FEN),但额外模块的引入会带来额外的学习参数以及线上推理耗时,同时,这些模型仅通过监督信号来优化特征表示,论文认为这也是远远不够的。
因此,从特征表示优化的角度出发,针对现有模型的一些问题,将多种对比学习的损失引入到模型当中,接下来对具体方法进行介绍。
2、CL4CTR介绍
论文提出了一种CTR预估中的对比学习框架CL4CTR,整体如下图所示:
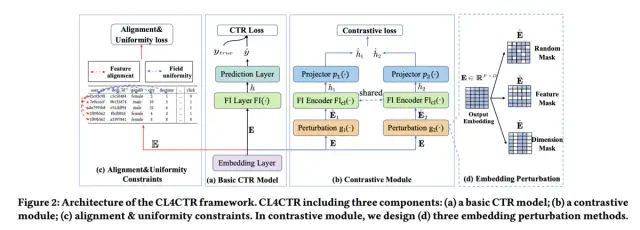
预估部分的内容就不介绍了,主要对三种对比学习损失进行介绍。
2.1 Contrastive Loss
这一部分引入了Contrastive Moudle,基于数据增强的思路,对样本的embedding进行扰动,构造相似的正例样本,相似的embedding在经过相同的特征交互层和映射层之后,得到的结果也应该是相近的。
对于embedding扰动的方式,论文提出了三种方法,分别是随机mask,按特征mask,按维度mask,三种方式如下图所示:
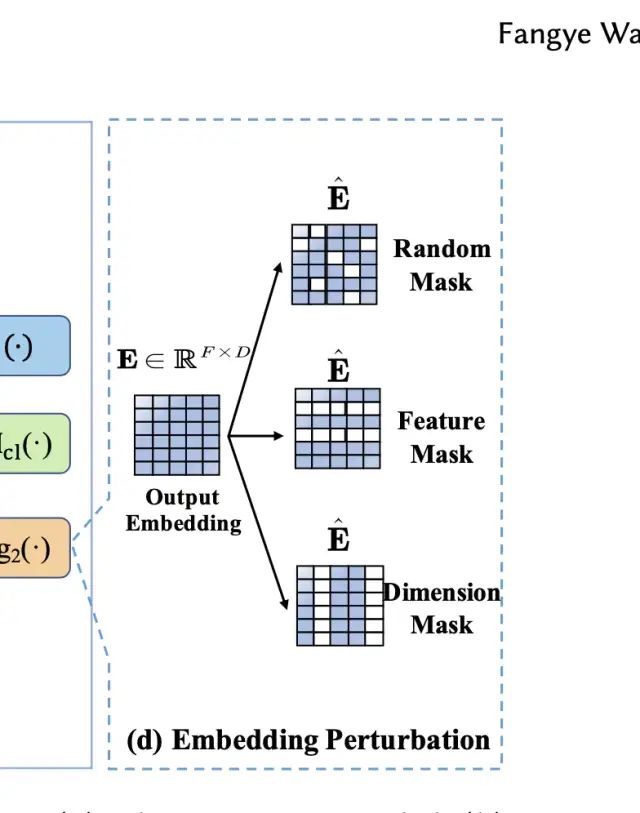
对于扰动后的样本对,经过特征交互层和映射层之后,希望其得到的向量表示越近越好,数学表示如下:
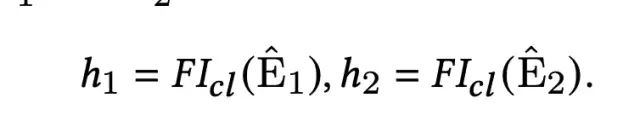
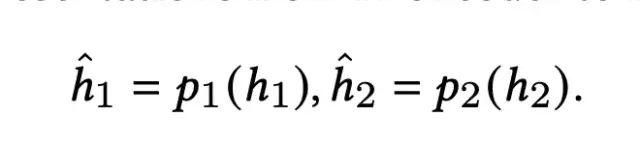
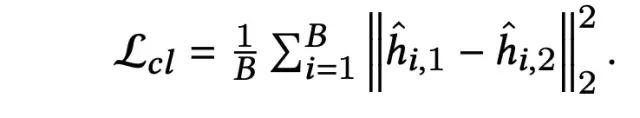
2.2 Feature Alignment And Field Uniformity Loss
为了确保高频特征和低频特征都能够得到有效的学习,受CV和NLP领域中的思路的启发,通过引入正负样本对,引入alignment和uniformity两个约束来实现。针对CTR预估场景,本文将同一个field的特征类比为正样本对,不同field的特征类比为负样本对,在这样的假定下,Feature Alignment即来自相同域的embedding尽可能接近,Field Uniformity即来自不同域的特征embedding尽可能远。数学表示如下:
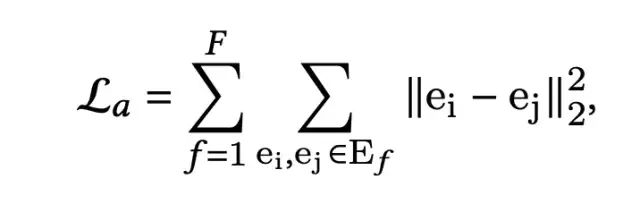
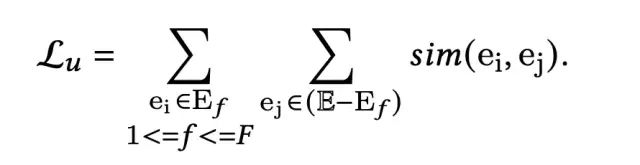
其中,F表示field的个数,f表示某一个特定的域,相似度计算采用cosine距离。
2.3 Multi-task Training
在引入上述三个对比学习损失后,模型的整体损失函数包含四部分:
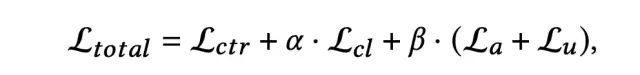
首先,模型没有引入额外的参数,因此不影响预测耗时;其次,通过引入Contrastive Loss,提升了embedding的表达能力;最后,引入最后一部分损失,保证长尾特征的embedding也能得到有效的学习。
3、实验结果
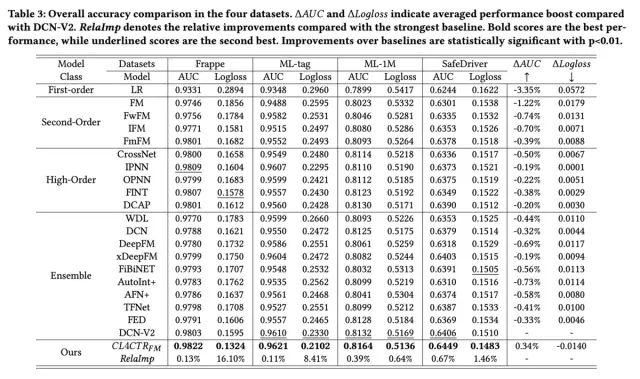
最后来看下实验结果,首先是与baseline模型的对比:
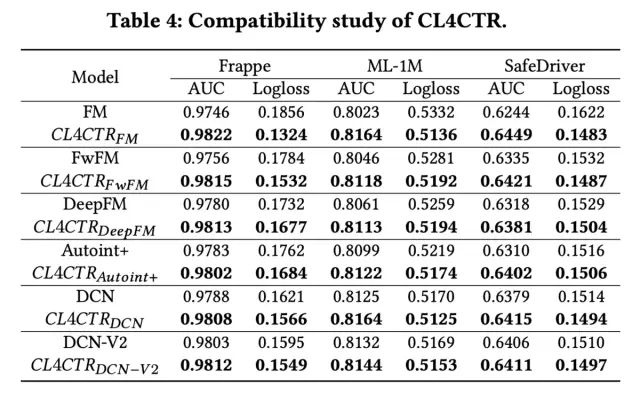
接下来论文进行了诸多消融实验验证模型的效果,首先是兼容性分析,将CL4CTR应用于不同的base模型上,均取得了AUC的提升:
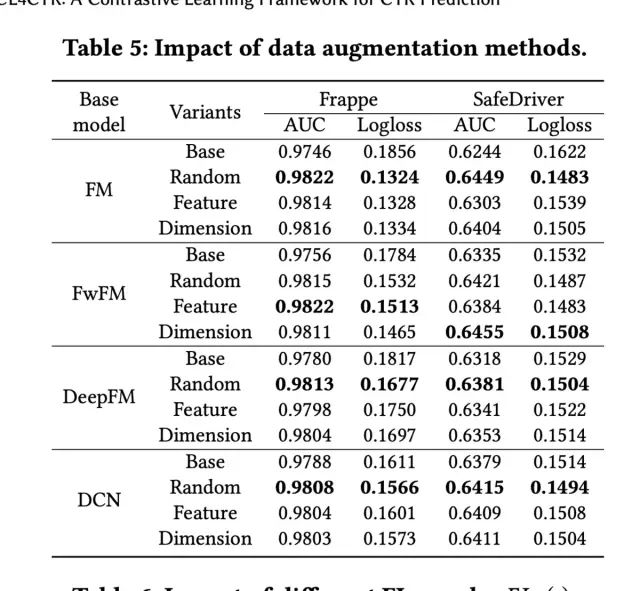
其次是Contrastive Loss中不同的数据增强方式,针对不同的数据集和Base模型,最优的数据增强方式不同:
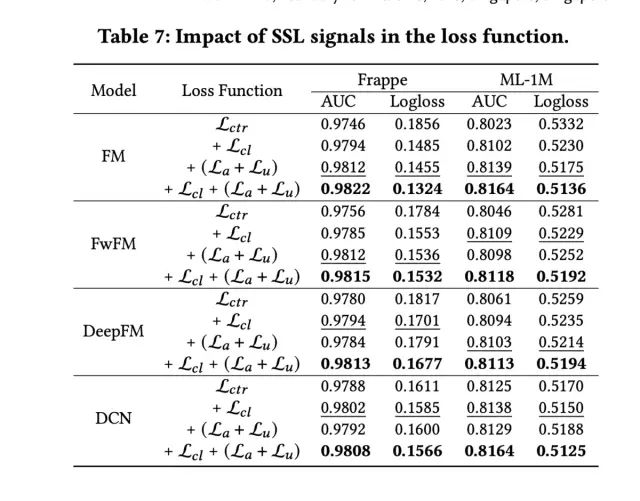
最后是loss function,引入三种对比学习损失时,效果最优:
好了,论文就介绍到这里,整体来说论文要解决的问题十分明确,所采取的对比学习方法具有一定的借鉴意义~







