在之前的文章《ChatGPT下的知识图谱审视:一次关于必然影响、未来方向的讨论实录与总结》中,我们谈到了目前的一些思考,但不够具体,具体两者应该如何结合,并没有指出具体的实践方向,很多人也并不清晰。
因此,为了更好的解答这个问题,本文主要谈谈在CCFTF97:大语言模型时代的知识工程《浅谈大模型与知识图谱的结合:近期的几点方向探索与心得总结》中的一些分享心得,供大家参考。
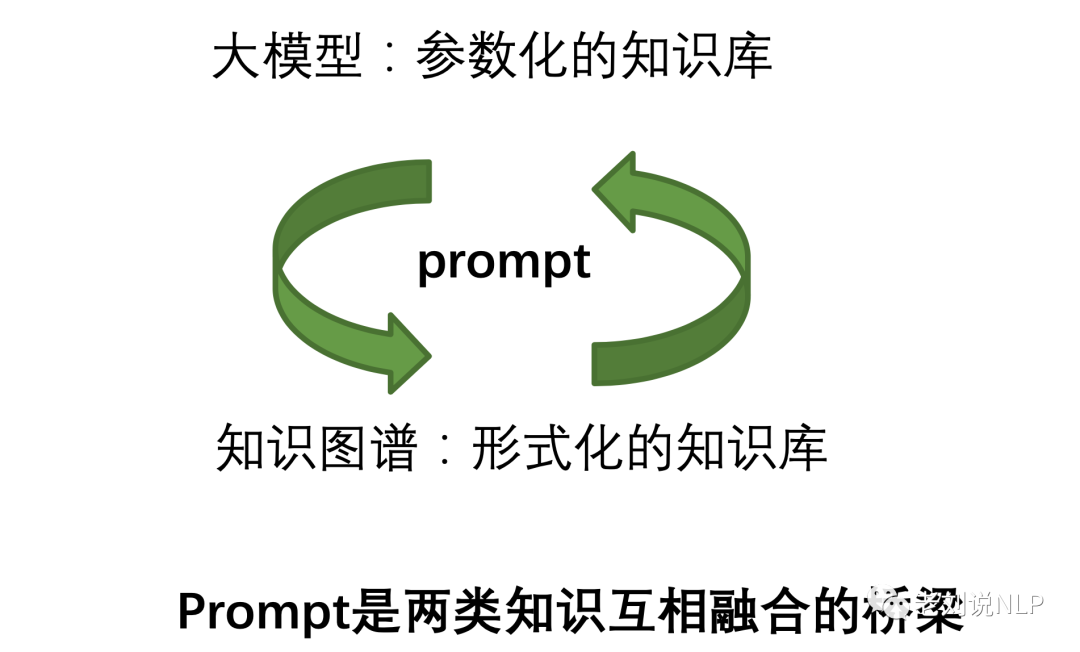
我们认为,首先,在模型层面,作为参数化知识库的大模型与形式化知识库的知识图谱之间,可以通过prompt作为桥梁进行互相转化。
例如,知识图谱,可以利用prompt,参与到大模型的训练前的数据构造,训练中的任务,以及训练后推理结果的约束生成,提升大模型的性能。
又如,大模型,可以通过prompt,来执行相应信息提取以及思维链的推理任务,形式化成不同形式的知识【例如三元组,多元组或者事件链条】。
此外,在平台系统层面。知识图谱目前有相应的知识图谱平台,与网络分析、图数据库查询、可视化展示,推理链条可解释形象化展示上已经形成了一个工具性平台。而大模型目前通过系统接口、插件的方式又可以作为一个灵活的组件注入到知识图谱平台当中,作为一个新的生产力提升工具而存在。
下面是具体的一些路线和方向心得,供大家参考。
一、先从知识图谱与大语言模型说起
1、知识图谱VS大语言模型
我们先来看看知识图谱和大语言模型之间的区别
首先,在相同点上。两者本质上都是一种知识库;在实时性和时效性上面临的挑战一致:chatgpt遇到的事实性错误和时效性,知识图谱同样存在,知识图谱也需要解决知识更新的问题。而且知识图谱如果不能保证非结构化数据源的正确性,到后面也注定会发生事实性错误。如果chatgpt创造出大量的内容之后,并作为数据源导入到知识图谱当中,会影响知识图谱的准确性。
其次,在不同点上,
知识图谱是一种知识的形式化表示方式,大语言模型(ChatGPT)是参数化的知识。KG优势在于方便debugging,人可理解,图结构表达能力强,ChatGPT就是any data, any task, 无所不能,不够简单。
此外,知识图谱具有双层结构,其本体层,对领域知识有个很好的建模和规范组织,这个队伍知识的更新、维护大有裨益。
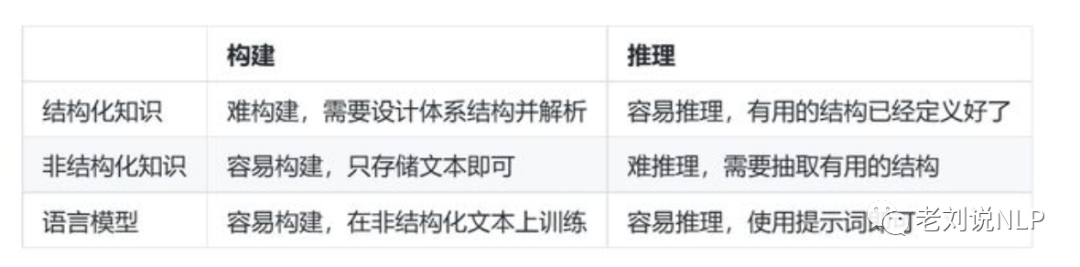
此外,在推理场景中,结构化知识很难构建(因为要设计知识的结构体系),但易于推理(因为有体系结构),非结构化知识易于构建(直接存 起来就行),但很难用于推理(没有体系结构)。
大语言模型提供了一种新的方法,可以轻松地从非结构化文本中提取知 识,并在不需要预定义模式的情况下有效地根据知识进行推理。
二、大模型应用于知识图谱研发
当我们来回答大模型如何应用于知识图谱这个命题时,我们需要"对症下药",找到它的不足,和切入点。
1、业界研发人员眼里的知识图谱认识
首先我们来看,知识图谱的真实工作,简单来说,做图谱就是在做数据。与大多数教科书以及PPT里给大家呈现的"大有可为"的知识图谱大价值观的印象不同,我们需要很好的认识其在真实应用场景中的实际状况。
下面总结几条:
1)做知识图谱,本身就是在做数据,是“表面光鲜亮丽”,但背后“脏、累、甚至“吃力不讨好”的活
2)知识图谱是一个领域性、case by case的范畴,需要算法、产品、工程个方面的协同
3)做知识图谱的过程,就是一个数据定义、数据挖掘、数据清洗、数据评估的过程
4)知识图谱在业务看来,更多时候是一个领域性的大词表,一个事实性的领域强规则和知识库
5)知识图谱是一门数据科学,也是一个数据工程,非纯粹算法,更多的是业务和工程
6)知识图谱做好,业务指标可能不会有明显提升,但不做好,业务指标大概率不会好
7)知识图谱的价值,在于其准确性、全面性、实时性、规范性以及加持图结构带来的特性增益。
2、知识图谱目前面临主要问题
因此,我们可以进一步地总结出如下知识图谱所面临的问题,一句话就是成本太高。
1)整个生产流程过长,涉及到格式转换、本体定义、实体抽取、关系抽取、实体对齐,不够端到端;
2)多个具有级联错误的环节,加上上线要求的高标准,构建成本相对较高;
3)信息抽取环节需要有大量的标注数据,标注成本高;
4)知识图谱的领域属性较强,更多时候需要case by case,需要行业专家高度参与研发周期过长带来的时间成本问题,以及不同领域的迁移问题;
5)在解决实时性、准确性、全面性上的问题时,所需要花费的运行和维护成本较高。
3、大模型应用于知识图谱研发
我们先来看大模型的优势。大模型最大的魅力在于其通用能力,即zeroshot和fewshot能力,可以作为一个统一系统完成统一信息抽取任务,加速不同任务的统一处理。
这个统一处理贯穿于从数据标注、数据增强、模型推理【信息抽取、分类】的整个环节,因此,在成本端利用大模型生成标注数据,减少人力成本,提升敏感场景项目交付,利用大模型平替各环节抽取任务,提升模型性能和交付速度。
但是,我们发现,这个"一字型"选手,广度上相当霸主,但在某一专长上,给其他小模型了一些可以深度优化的点,小模型在finetune上可以有很高的精度,但后续可以形成大模型进行数据增强,小模型进行领域finetune的应用范式。
例如,基于大模型完成数据标注和数据增强,加速知识图谱生产落地。
我们经常会问到,利用ChatGPT来标注语料,然后再利用Bert等模型来训练的方式是不是奇怪?ChatGPT用来做数据标注,再去训练模型,是不是有点本末倒置,为什么不直接ChatGPT 干下游任务?
但是,在不同的场景对大模型的使用方式有明显差异,在数据敏感、数据不出网的场景下,可能成为必选项; 在更偏垂直的下游任务中,全监督模型的方式能够取得更佳效果。
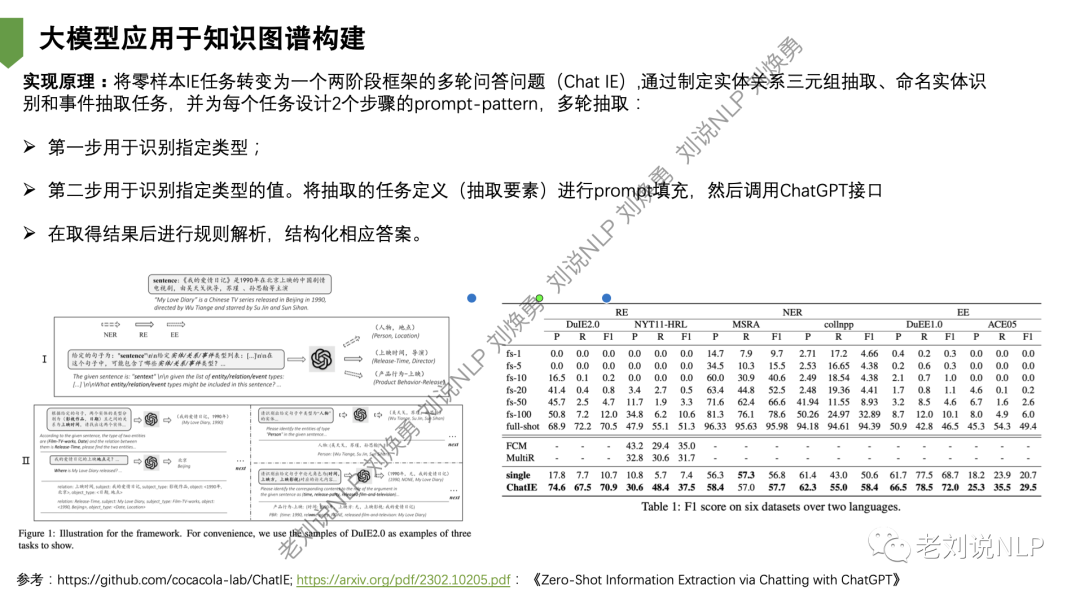
又如,模型应用于知识图谱构建。
例如,可以将零样本IE任务转变为一个两阶段框架的多轮问答问题(Chat IE),通过制定实体关系三元组抽取、命名实体识 别和事件抽取任务,并为每个任务设计2个步骤的prompt-pattern,多轮抽取: 第一步用于识别指定类型;第二步用于识别指定类型的值。将抽取的任务定义(抽取要素)进行prompt填充,然后调用ChatGPT接口在取得结果后进行规则解析,结构化相应答案。
三、知识图谱应用于大模型研发
同样的,我们再来看看,知识图谱应用于大模型研发中,有哪些可以结合的地方,依旧是大模型存在的问题以及图谱可以做的事两个方面。
1、ChatGPT当前存在的体验问题
作为生成模型的chatgpt最大的问题就是不确定性以及预训阶段语料的局限性,由此会出现包括时效性、事实性以及"不合规"性等问题。体现在以下几个方面【当然我们只能限定在现在的条件下进行评判,因为你无法预知其进化速度】:
1)可能写出看似合理但不正确或荒谬的答案。这可能是训练时没有真实来源,导致生成错误信息,或者训练模型谨慎性的提高导致它拒绝可以正确回答的问题监督训练误导模型;
2)对输入措辞的调整或多次尝试相同的提示很敏感。给定一个问题的措辞,模型可以声称不知道答案,但只要稍作改写,就可以正确回答,这其实就是不确定上,
3)生成偏向。该模型通常过于冗长并过度使用某些短语,该模型已努力使模型拒绝不当请求,但它有时会响应有害指令或表现出有偏见的行为,这属于"合规方面"的问题。
4)在符号形式的推理任务上,建模效果还不是特别好【限定为当前,后续可能会有改善】,这与底层缺乏符号性地知识有关。
5)在知识统一表示上,业务知识梳理和沉淀上建模性较差,这种随机性还需要规范化的统一知识表示进行组织跟重构【这是站在知识工程的角度上来说,虽然在实际应用场景中,并不需要,能用就行。】
6)不知是否可信,也不可解释。这个点是学术界常批判的一个点。其原理不可解,推理过程无法解释,不可控,也就无法做到可信。但这个可信,落在工业界上,还能和安全扯上关系。
2、知识图谱的几个优势
既然在事实性、符号性、知识组织上存在一定的差别,那么作为在知识形式表示,知识本体规范上有一定可为的图谱又有哪些具体优势呢?我们认为,有以下几点:
1)一份好的知识图谱数据,可以为关键词扩充、领域精准问答、实体拓展等提供一手数据来源。
2)一份好的领域知识图谱数据,可以作为一个行业专家系统,一个专业的强规则库进行权威指导。
3)知识图谱中的图结构多跳信息,可以完成多跳推理、隐藏关系发现等任务,知识图谱足够直观,足够醒目,可以作为现象的机理分析和可解释。
4)知识图谱作为一个领域的知识建模规范,可用于知识系统联合。
2、知识图谱应用于大模型研发的几个阶段
因此,我们认为,知识图谱应用于大模型研发,可以在训练前、训练中以及训练后几个角度上展开应用。
1)训练前阶段
大模型在训练前需要做大量的数据收集、整理、清洗等操作, 其中存在质量、多样性以及规模上多个问题 ,可以利用知识图进行数据清洗,其作为领域经验知识对特定语料进行错误检测或过滤; 利用知识图谱直接显式的进行形式化拼接,引入预训练语料;
2)训练中阶段
大模型在训练过程中,效果取决于所采用的模型架构、训练时间以及训练算力,引入知识图谱可以增强模型的有效性;
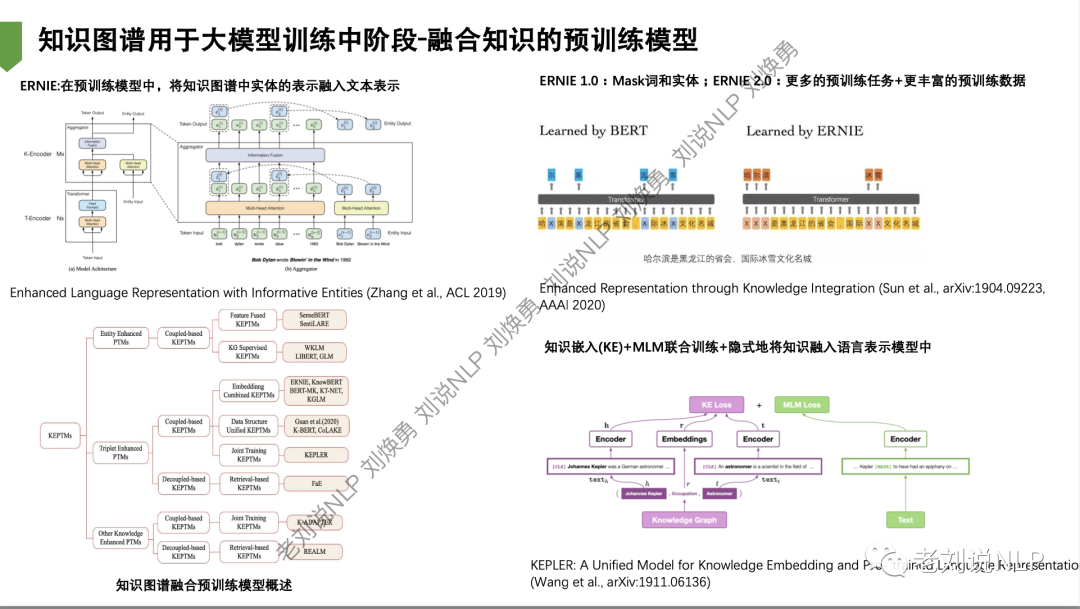
将知识图谱隐式地加入到模型训练中,ERNIE在预训练模型中将知识图谱中实体的表示融入文本表示;知识嵌入(KE)+MLM联合训练+隐式地将知识融入语言表示模型中;
构建以领域知识图谱为中心的下游评测任务,作为模型训练评估闭环;
3)训练后阶段
大模型在训练好之后,如何结合实际场景,用好prompt,更大地激发大模型的能力,促进生产力;
为解决生成“胡说八道”,在构造prompt时,作为先验知识进行prompt前约束,增强结果可控性;
为解决领域生成局限性现象,在构造prompt时,引入涉及实体的上下文进行丰富,增强结果可用性;
为解决生成“胡说八道”,对模型生成后的结果进行约束,减少模型事实性错误;
为解决大模型实时性问题,通过query实体消歧和实体链接,优化搜索引擎实时结果,增强生成准确性;
ChatGPT会生成大量虚假信息,作为下游的知识图谱,需要对ChatGPT进行虚假鉴定 ,基于知识图谱,为大模型生成提供可解释方案。
例如,将知识图谱用于大模型训练后阶段-融合自迭代的知识描述以增强常识推理能力
首先,进行常识推理需要常识知识,而预训练语言模型隐含了大量的知识,可以直接作为常识推理的推理模型,整合外部知识库可以 提高其中一些任务的性能。
其次,使用知识模型根据问题生成知识陈述,其中每个知识陈述是一个变长文本序列,每个陈述都包含了与问题相关的信息。 外部知识引入形式包括Random sentences/template-based/retrival-based等,根据问题和知识陈述,使用推理模型来预测答案。

又如,知识图谱用于大模型训练中阶段-融合知识的预训练模型,通过不同的引入方式进行知识增强。
四、知识图谱平台与大模型平台的共生
上面讲的都是模型层上的结合点,而两者又可以分别作为一个平台呈现。东南大学漆桂林老师分享了关于知识图谱平台与大模型平台的一些探讨观点,很受启发,抛出了2个探讨话题。
1、探讨:知识图谱平台&大模型图平台-双知识平台互相增强
首先,知识图谱平台是否可以被大模型平台替代?
目前看来是不能被替代的,见ChatGPT对于信息抽取和智能问答的评测,大模型的不可解释性决定了它(暂时)无法作为一个可信人工智能系统 。知识图谱作为一种显性的、高质量知识库,将继续用于问答、推荐、预测、決策类任务。
其次, 知识图谱平台如何增强大模型?
知识图谱平台可以通过人机交互创建和推理高质量知识(比如说处理知识的逻辑冲突) 。知识图谱平台生成的知识将通过前面介绍的方法用于增强大楧型 。知识图谱平台可以用于解决大模型不擅长解決的问题,比如说上下文知识遗忘、知识可视 化、关联分析和決第类任务。
2、探讨:知识图谱平台&大模型图平台-双知识平台互相增强
首先,大模型平合如何增强知识图谱平台?
大模型作为一种基础模型,为知识图谱平台的自动化提供了有效的解决方案 。知识图谱的表示学习和推理(比如说KGembedding和部分的ontology reasoning)可以基于大模型完成,即知识图谱的表示学习和大模型的表示学习互相增强 。本体和规则的学习可以通过大模型平台实现高度自动化(还是需要引入人机交互来更好实现) 。
但这也存在挑战:大模型如何实现复杂知识的抽取以及长尾知识的抽取?
其次,知识图谱平台和大模型平台如何协同完成复杂知识处理任务?
大模型平台利用知识困谱平合生成的知识对各种知识进行集成,对大模型平合的指令进行分解,完成复杂任务(比如说微软Office 365 Copilot) 。
知识图谱平台和大模型平台协同完成复杂问题的知识问答 ,知识图谱平台用于沉淀大模型乎台中任务驱动的关键知识,用于完成需要精确、可解释的问答和行动。
也就是说,在平台系统层面。知识图谱目前有相应的知识图谱平台,与网络分析、图数据库查询、可视化展示,推理链条可解释形象化展示上已经形成了一个工具性平台。大模型目前通过系统接口、插件的方式又可以作为一个灵活的组件注入到知识图谱平台当中,作为一个新的生产力提升工具而存在。
总结
本文主要介绍了《浅谈大模型与知识图谱的结合:近期的几点方向探索与心得总结》中的一些心得,从中我们可以看到两种不同知识库的具体特点,存在的问题以及互相补充的可行机制。
当然,本文只是一些个人的观点,也存在不对,浅薄甚至错误的论述,大家可以根据自己的理解进行批评。
参考文献
1、刘焕勇.《浅谈大模型与知识图谱的结合:近期的几点方向探索与心得总结》.CCFTF97:大语言模型时代的知识工程
2、漆桂林.《知识增强大语言模型技术与双知识平台融合思考》.CCFTF97:大语言模型时代的知识工程
关于老刘
老刘,刘焕勇,NLP开源爱好者与践行者,主页:https://liuhuanyong.github.io。
就职于360人工智能研究院、曾就职于中国科学院软件研究所。








