网上经常看到,请帮我 P 掉身边的 xxx 求助帖,拍照就会有 P 掉身边路人的需求。
今天介绍一个算法,不仅能够 P 掉指定的人或物,甚至能任意编辑。

配合着文字 prompt 输入,还能修改图片,比如:
输入 text prompt: "a camera lens in the hand"。
手中的甜甜圈就变成了相机镜头。

项目刚刚开源,感兴趣的小伙伴可以看看:
项目地址:https://github.com/geekyutao/inpaint-anything
论文链接:http://arxiv.org/abs/2304.06790
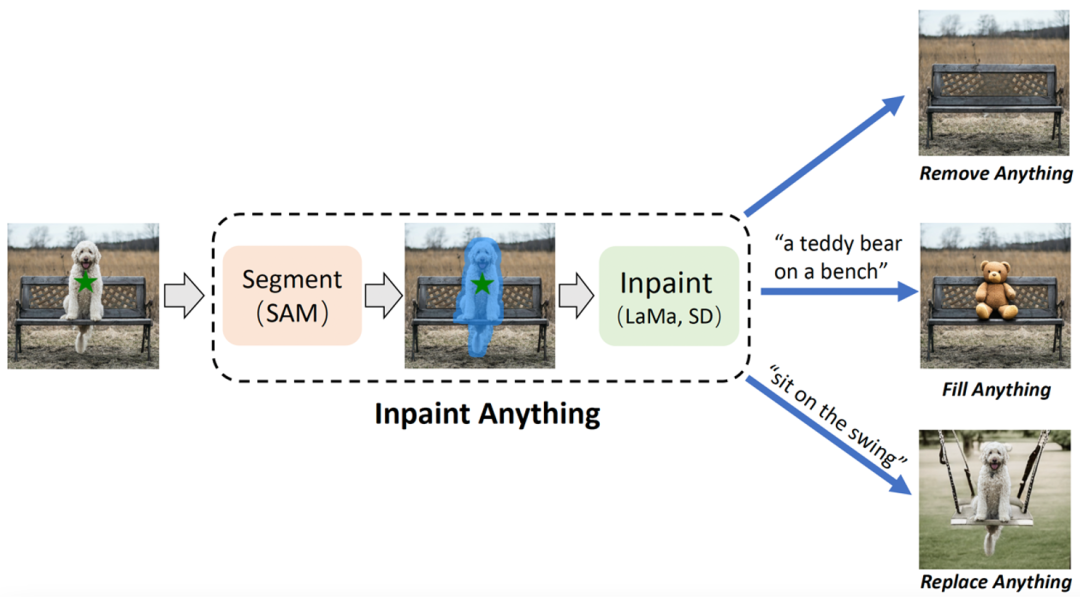
尽管当前图像修补系统取得了重大进展,但它们在选择掩码图和填补空洞方面仍然面临困难。基于 SAM,研究者首次尝试无需掩码(Mask-Free)图像修复,并构建了「点击再填充」(Clicking and Filling) 的图像修补新范式,他们将其称为修补一切 (Inpaint Anything)(IA)。IA 背后的核心思想是结合不同模型的优势,以建立一个功能强大且用户友好的图像修复系统。
IA 拥有三个主要功能:
- 移除一切(Remove Anything):用户只需点击一下想要移除的物体,IA 将无痕地移除该物体,实现高效「魔法消除」;
- 填补一切(Fill Anything):同时,用户还可以进一步通过文本提示(Text Prompt)告诉 IA 想要在物体内填充什么,IA 随即通过驱动已嵌入的 AIGC(AI-Generated Content)模型(如 Stable Diffusion)生成相应的内容填充物体,实现随心「内容创作」;
- 替换一切(Replace Anything):用户也可以通过点击选择需要保留的物体对象,并用文本提示告诉 IA 想要把物体的背景替换成什么,即可将物体背景替换为指定内容,实现生动「环境转换」。
IA 的整体框架如下图所示:
移除一切
 移除一切(Remove Anything)示意图
移除一切(Remove Anything)示意图「移除一切」步骤如下:
填补一切
 填补一切(Fill Anything)示意图,图中使用的文本提示:a teddy bear on a bench
填补一切(Fill Anything)示意图,图中使用的文本提示:a teddy bear on a bench「填补一切」步骤如下:
第 4 步:基于文本提示的图像修补模型(Stable Diffusion)根据用户提供的文本对物体进行填充。
替换一切
 替换一切(Replace Anything)示意图,图中使用的文本提示:a man in office
替换一切(Replace Anything)示意图,图中使用的文本提示:a man in office「替换一切」步骤如上。
更多效果:




研究者建立这样一个有趣的项目,来展示充分利用现有大型人工智能模型所能获得的强大能力,并揭示「可组合人工智能」(Composable AI)的无限潜力。项目所提出的 Inpaint Anything (IA) 是一种多功能的图像修补系统,融合了物体移除、内容填补、场景替换等功能(更多的功能正在路上敬请期待)。
IA 结合了 SAM、图像修补模型(例如 LaMa)和 AIGC 模型(例如 Stable Diffusion)等视觉基础模型,实现了对用户操作友好的无掩码化图像修复,同时支持「点击删除,提示填充」的等「傻瓜式」人性化操作。此外,IA 还可以处理具有任意长宽比和 2K 高清分辨率的图像,且不受图像原始内容限制。
-
机器学习交流qq群955171419,加入微信群请扫码










