计算机视觉界已经集中在度量 mAP 上,来比较目标检测系统的性能。在这篇文章中,我们将深入了解平均精度均值 (mAP) 是如何计算的,以及为什么 mAP 已成为目标检测的首选指标。
在我们考虑如何计算平均精度均值之前,我们将首先定义它正在测量的任务。目标检测模型试图识别图像中相关对象的存在,并将这些对象划分为相关类别。例如,在医学图像中,我们可能希望能够计算出血流中的红细胞 (RBC)、白细胞 (WBC) 和血小板的数量,为了自动执行此操作,我们需要训练一个对象检测模型来识别这些对象并对其进行正确分类。
EfficientDet(绿色)与 YOLOv3(黄色)的示例输出
这两个模型都预测了图片中细胞周围的边界框,然后他们为每个边界框分配一个类。对于每个任务,网络都会对其预测的置信度进行建模,可以在此处看到我们共有三个类别(RBC、WBC 和Platelets)。
我们应该如何决定哪个模型更好?查看图像,看起来 EfficientDet(绿色)绘制了过多的 RBC 框,并且在图像边缘漏掉了一些细胞。这当然是从事物表面来看——但是我们可以相信图像和直觉吗?
如果我们能够直接量化每个模型在测试集中的图像、类和不同置信阈值下的表现,那就太好了。要理解平均精度均值,我们必须花一些时间来研究精度-召回曲线。
精确是“模型猜测它正确猜测的次数?” 的一个衡量标准,召回是一种衡量“模型每次应该猜到的时候都猜到了吗?” 。假设一个具有有 10 个红细胞的图像,模型只找到这 10 个中正确标记的一个,因为“RBC”具有完美的精度(因为它做出的每一个猜测都是正确的),但并不同时具有完美的召回(仅发现十个 RBC 细胞中的一个)。
包含置信元素的模型可以通过调整进行预测所需的置信水平来权衡召回的精确度。也就是,如果模型处于避免假阳性(当细胞是白细胞时说明存在红细胞)比避免假阴性更重要的情况下,它可以将其置信阈值设置得更高,以鼓励模型只产生以降低其覆盖率(召回)为代价的高精度预测。
精度-召回曲线是绘制模型精度和以召回率作为模型置信阈值函数的过程。它是向下倾斜的,因为随着置信度的降低,会做出更多的预测,进而预测的准确性会降低(影像精确度)。
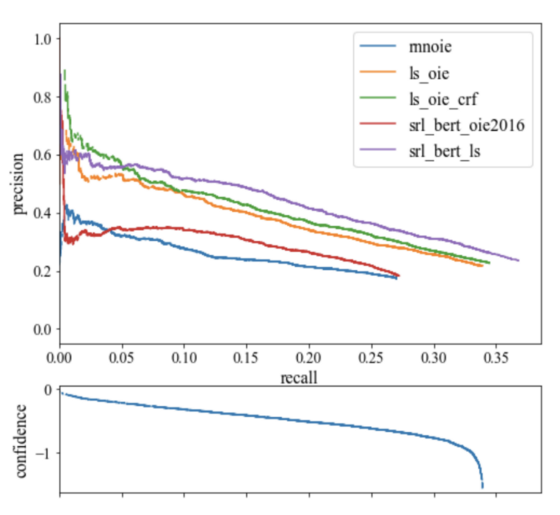
一个 NLP 项目中不同模型的精度、召回率和置信度
随着模型越来越不稳定,曲线向下倾斜,如果模型具有向上倾斜的精度和召回曲线,则该模型的置信度估计可能存在问题。
人工智能研究人员偏向于指标,并且可以在单个指标中捕获整个精确召回曲线。第一个也是最常见的是 F1,它结合了精度和召回措施,以找到最佳置信度阈值,其中精度和召回率产生最高的 F1 值。接下来是 AUC(曲线下面积),它集成了精确性和召回曲线下的绘图量。
精确召回汇总指标图
最终的精确-召回曲线指标是平均精度 (AP),它被计算为在每个阈值处实现的精度的加权平均值,并将前一个阈值的召回率增加用作权重。
AUC 和 AP 都捕获了精确-召回曲线的整个形状,选择一个或另一个进行目标检测是一个选择问题,研究界已经将注意力集中在AP 的可解释性上。
真正的目标检测图
在实践中,X1、X2、Y1、Y2 坐标中预测的边界框肯定会偏离地面真实标签(即使稍微偏离)。我们知道如果边界框预测是错误的类,我们应该将其视为不正确的,但是我们应该在哪里绘制边界框重叠的线?
Intersection over Union (IoU) 提供了一个度量来设置这个边界,与地面真实边界框重叠的预测边界框的数量除以两个边界框的总面积。
 真正对 IoU 指标的图形描述。
真正对 IoU 指标的图形描述。
为 IoU 指标选择正确的单个阈值似乎是任意的,一位研究人员可能会证明 60% 的重叠是合理的,而另一位则认为 75% 似乎更合理,那么为什么不在一个指标中考虑所有阈值呢?
为了计算 mAP,我们绘制了一系列具有不同难度级别的 IoU 阈值的精确-召回曲线。
 我们真正绘制的 mAP 精确召回曲线图
我们真正绘制的 mAP 精确召回曲线图在上图中,红色绘制的是对 IoU 的最高要求(可能是 90%),橙色线绘制的是对 IoU 的最低要求(可能是 10%),要绘制的线数通常由挑战设置。例如,COCO 挑战设置了十个不同的 IoU 阈值,从 0.5 开始,以 0.05 的步长增加到 0.95。
最后,我们为按类型划分的数据集绘制这些精度-召回曲线。
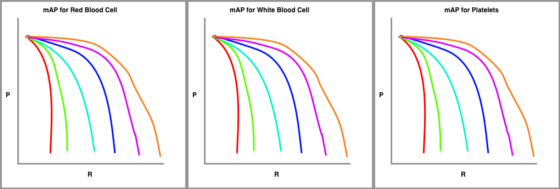
由我们真正按对象类别划分的 mAP 图
该指标在所有 IoU 阈值上单独计算每个类的平均精度 (AP),然后该指标对所有类别的 mAP 进行平均以得出最终估计值。
我最近在一篇文章中使用了mAP,比较了最先进的EfficientDet和YOLOv3检测模型,我想看看哪个模型在识别血液中的细胞表现更好。
在对测试集中的每个图像进行推理后,我导入了一个 python 包来计算Colab笔记本中的mAP,结果如下!
EfficientDet 对细胞物体检测的评价:
78.59% = Platelets AP 77.87% = RBC AP 96.47% = WBC AP mAP = 84.31%
YOLOv3对细胞物体检测的评价:
72.15% = Platelets AP 74.41% = RBC AP 95.54% = WBC AP mAP = 80.70%
因此,与本文开头的单一推断图片相反,事实证明EfficientDet在建模细胞目标检测方面做得更好!我们还将注意该指标是按对象类划分的,这告诉我们,白细胞比血小板和红细胞更容易检测,这是有道理的,因为它们比其他细胞大得多,并且不同。
地图也经常被分成小、中、大对象,这有助于识别模型(和/或数据集)可能出现错误的地方。
机器学习交流qq群955171419,加入微信群请扫码










